本文提出了 OGPO(Off-policy Generative Policy Optimization),一种专为生成式控制策略(GCP)设计的高采样效率全策略微调算法。通过将双层 MDP 解耦并在“想象”的去噪过程中应用 PPO 优化,OGPO 在多项复杂机器人操纵任务中达到了 SOTA 性能。
TL;DR
生成式控制策略(Generative Control Policies, GCPs),如扩散策略(Diffusion Policy)和流匹配策略(Flow-matching Policy),已成为机器人学习的利器。然而,如何高效地通过强化学习(RL)对这些策略进行全量微调一直是个难题。本文提出的 OGPO (Off-policy Generative Policy Optimization) 通过巧妙地解耦环境交互与内部去噪优化,在保持极高采样效率的同时,实现了对复杂操纵任务的全策略优化。
核心地位:该工作是 GCP 微调领域的一里程碑,它填补了“低样本效率的全量微调”与“高样本效率的受限微调(如残差、转向)”之间的空白,达到了采样效率与最终表现的双赢。
痛点深挖:为什么 GCP 的全量微调这么难?
在机器人任务中,环境交互(收集真实样本)是非常昂贵的,而计算去噪(在模型内部生成动作)则是廉价的。
- 现有方法的僵局:
- 在线策略 (On-policy):如 DPPO,需要大量的新鲜环境样本,采样效率极低。
- 离线策略 (Off-policy):如 DSRL 或 EXPO,虽然样本重用率高,但通常只更新初始噪声(Steering)或学习一个残差项(Residual),当初始策略较弱时,它们无法改变策略的核心分布。
- 梯度的噩梦:通过 10 步甚至几十步的去噪链进行反向传播(BPTT)会导致严重的梯度爆炸或消失问题,尤其是在充满碰撞和非平滑接触的机器人任务中。
核心机制:OGPO 的“断后”艺术
OGPO 的核心 Insight 在于:与其通过整个环境序列进行端到端优化,不如在每一个动作执行的瞬间将世界“切断”。
1. 双层 MDP 的解耦 (Bi-level MDP Severing)
作者借用了 [Ren et al., 2024] 的双层 MDP 视角。在 OGPO 中:
- 外层 MDP:机器人与真实环境交互,收集 。
- 内层 MDP:模型内部的去噪过程,即在一个环境状态下,通过 步生成动作。
OGPO 的独创性在于,它使用一个维护在离线回放池中的 Q 函数(Critic) 作为内层去噪 MDP 的“终止奖励”。
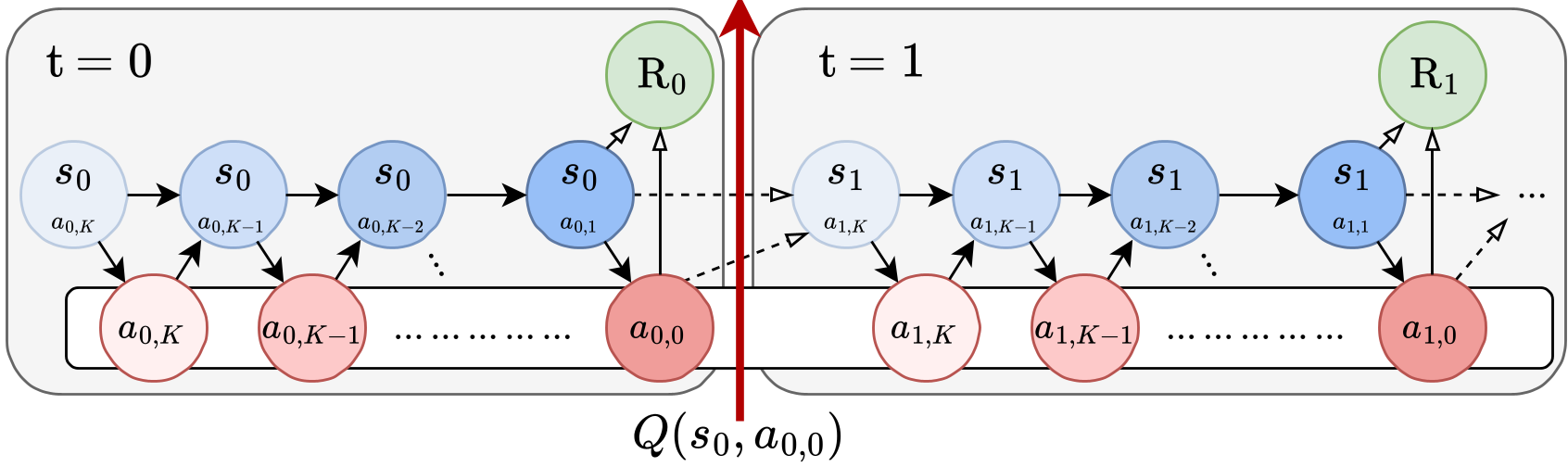
2. 零阶优化 (Zeroth-order Optimization)
为了躲避 backpropagation 的陷阱,OGPO 采用了 PPO 样式的零阶优化。它在同一个状态下并行生成多条“想象”的去噪轨迹,计算它们的累积概率比(AIS ratio),并根据离线 Critic 给出的优势信号(Advantage)来更新网络。这种方法不仅规避了梯度不平滑问题,还支持极大的 Batch Size 进行并行。
3. ODE-to-SDE 的纠偏算法
流匹配模型通常是确定性的,这对需要探索的 RL 并不利。OGPO 引入了高斯噪声使去噪过程随机化,但为了防止噪声引入分布偏移,作者采用了特殊的纠偏技术(Stochastic Interpolant Correction),确保带有随机扰动的去噪过程仍能贴合原有的动作流分布。
性能战绩:全量微调的力量
在多项极具挑战性的任务中,OGPO 展现了统治级的表现:
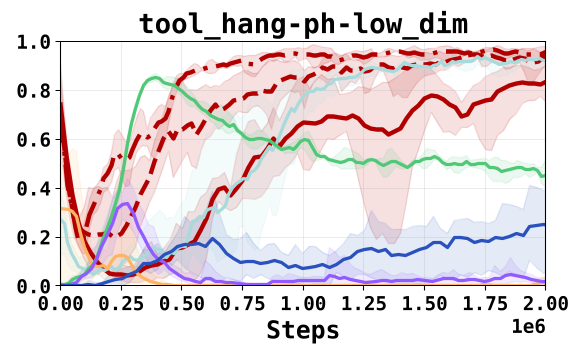
- 采样效率:在 Robomimic 的 Square 和 Transport 任务中,OGPO 到达 SOTA 成功率的速度比 DPPO 快了整整一个数量级(10x)。
- 克服初始极差的策略:即使初始策略是通过行为克隆(BC)得到的、成功率只有 50% 的“残次品”,且在线训练时不给模型看任何专家数据,OGPO+ 依然能将其推向近乎 100% 的成功率。
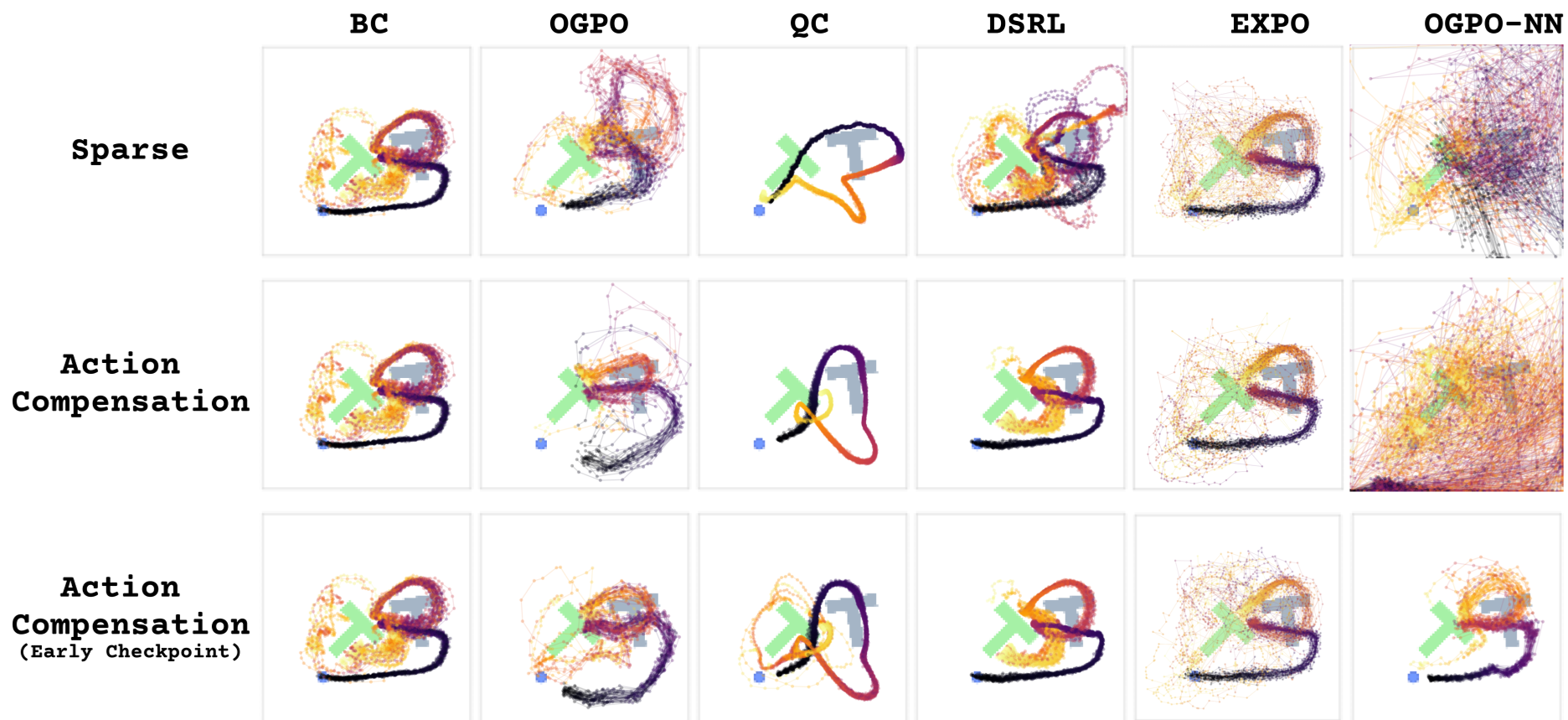
深度洞察:为什么全量微调优于残差更新?
如图 13 所示,通过 UMAP 可视化可以发现,单纯的行为克隆(BC)常陷入单一模态(Mode-seeking)。当环境发生变化需要新行为时,残差学习(EXPO)只能在原有分布附近微调。而 OGPO 展现了“流形扩张”(Manifold Expansion)的能力。
它利用 Q 函数引导整个生成链去探索高价值区域,这使得策略不仅能找回丢失的模态,还能学到比人类演示更高效、更快速的轨迹策略(Execution Efficiency)。
总结与启示
OGPO 成功的原因可以总结为:离线 Critic 提供全局视野(解决采样问题),在线 PPO 提供稳定动作提取(解决生成质量问题)。
局限性:尽管 OGPO 在稀疏奖励的高精度任务中表现卓越,但在某些密集奖励(Dense-reward)任务中,全量微调的过度表达能力可能导致过度拟合或速度下降。此外,如何在超大规模动作维度(如 24-DoF 机械手)下进一步提升稳定性仍是未来的课题。
对于实践者来说,OGPO 提供的不仅是一个算法,更是一种范式:在生成式模型时代,充分利用“计算廉价、采样昂贵”的非对称性,是让机器人自主进化的关键。