OmniCodec 是一种通用的神经音频编解码器,旨在实现低帧率(12.5Hz/6.25Hz)下语音、音乐和通用音频的统一建模。它通过引入预训练理解模型 Qwen3-Omni-AuT-Encoder 的语义知识,结合分层多码本设计,实现了语义与声学特征的高效解耦。
TL;DR
大语言模型(LLM)在音频生成领域的爆发,对“音频分词器”(Audio Tokenizer)提出了既要低帧率又要高语义的严苛要求。来自西北工业大学 ASLP 实验室的研究团队推出了 OmniCodec,这是一个通用的神经音频编解码器,首次证明了使用有监督预训练的理解模型(如 Qwen3-Omni)作为语义引导,能够超越传统的自监督模型(如 WavLM),在语音、音乐和音效全场景中实现 SOTA 级别的重构表现与语义建模能力。
1. 痛点:为什么 SOTA 编解码器在 LLM 面前“失灵”了?
在构建音频 LLM 时,研究者通常面临一个悖论:
- 重构 vs 压缩:像 DAC 或 Encodec 这样追求高保真的模型,通常需要 50Hz 甚至更高的帧率,这会使 LLM 的上下文窗口迅速饱和,难以处理长音频。
- 声学 vs 语义:传统的编解码器通过重构损失训练,捕获的是波形细节(声学),而忽略了背后的含义(语义)。这导致 LLM 在预测这些 Token 时如同“盲人摸象”,缺乏逻辑一致性。
- 领域局限:多数模型偏重语音(Speech),在处理复杂的交响乐或环境噪声时,重构效果会大幅下降。
OmniCodec 的出现,正是为了打破这三道枷锁,实现全领域(Universal)、低帧率(Low Frame Rate)与语义解耦(Disentanglement)。
2. 核心架构:语义与声学的“双人舞”
OmniCodec 抛弃了传统的单分支结构,采用了极具启发性的双分支解耦设计。
2.1 语义监督的换代
以往的方法(如 SpeechTokenizer)多采用 WavLM 等自监督模型进行蒸馏。OmniCodec 锐意创新,引入了 Qwen3-Omni-AuT-Encoder。这个编码器在 2000 万小时的海量有监督音频数据上训练过,具备极强的跨域语义理解能力。
2.2 架构拆解
- 语义分支(Semantic Branch):负责前几层码本,捕获音频的核心内容。
- 声学分支(Acoustic Branch):采用 SEANet 架构和流式卷积,通过减去语义特征再进行 RVQ 量化,确保剩下的码本只关注细节补全。
- 自引导机制(Self-guidance):这是一个巧妙的设计,通过让 Decoder 模仿未量化之前的连续特征输出,强迫模型对量化误差具备鲁棒性。
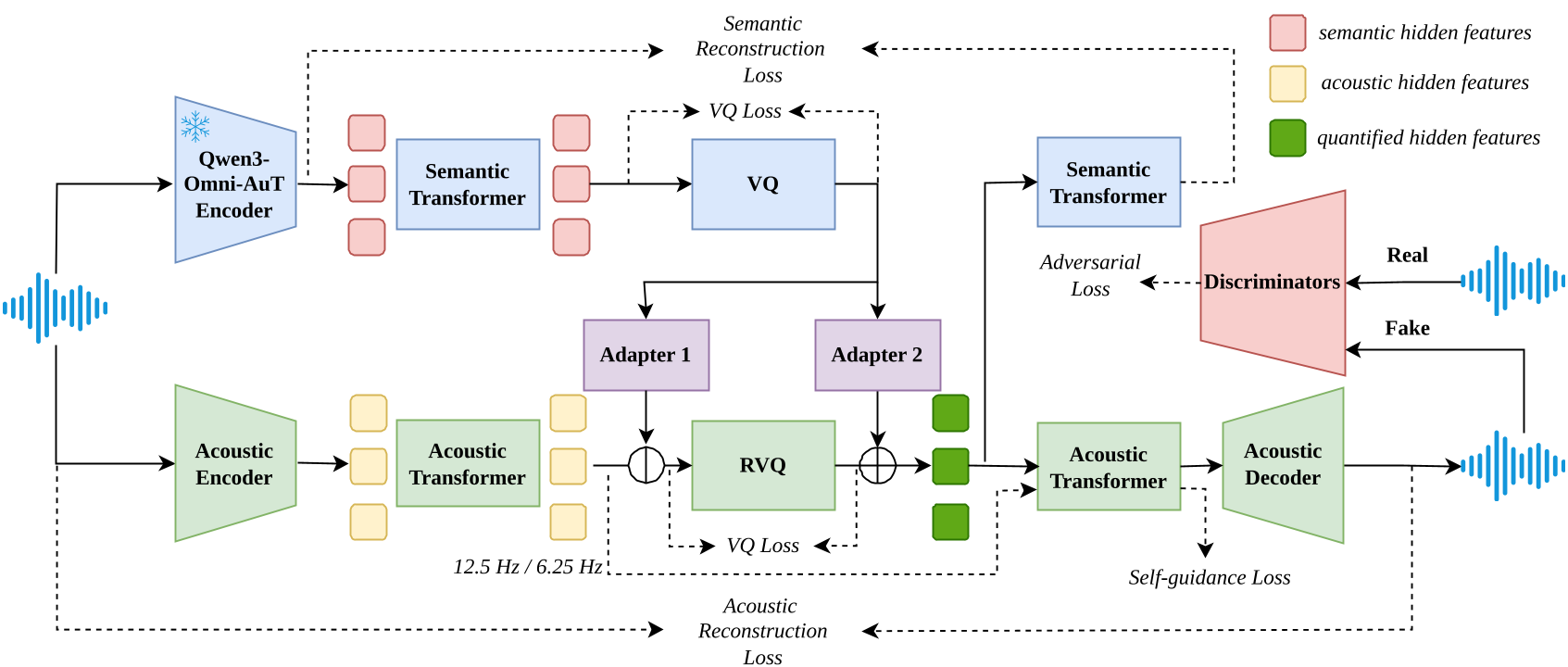 图 1:OmniCodec 整体架构流程图。展示了语义分支与声学分支如何通过 Adapter 进行解耦与重组。
图 1:OmniCodec 整体架构流程图。展示了语义分支与声学分支如何通过 Adapter 进行解耦与重组。
3. 实验战绩:低帧率下的降维打击
3.1 全场景重构对比
在 LibriSpeech(语音)、GTZAN(音乐)和 AudioSet(音效)三大数据集上的测试显示,OmniCodec 即使在 6.25Hz(极低帧率)下,其 STOI 和 MCD 指标依然能与高帧率模型一较高下。
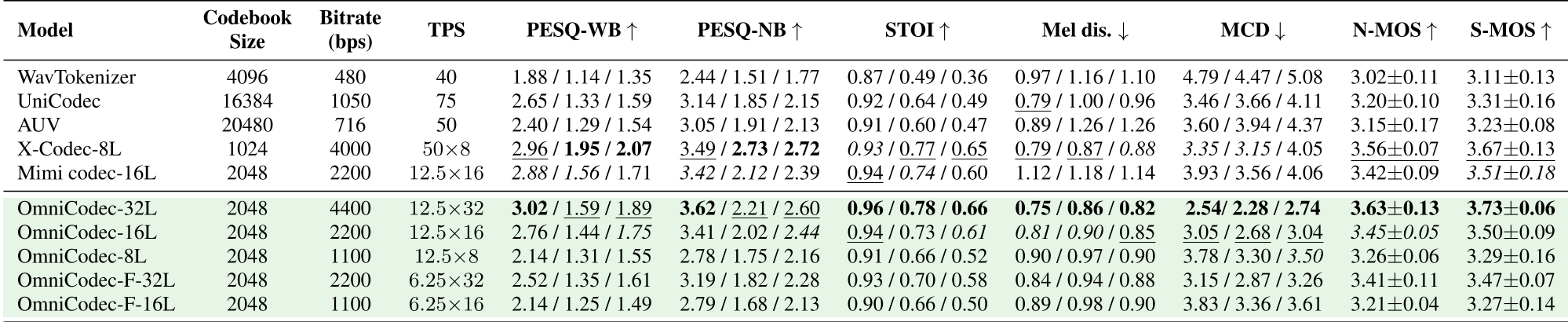 表 1:OmniCodec 与 WavTokenizer, Mimi 等主流模型的量化对比。可以看到在相同比特率下,OmniCodec-16L 的 MCD 显著更低。
表 1:OmniCodec 与 WavTokenizer, Mimi 等主流模型的量化对比。可以看到在相同比特率下,OmniCodec-16L 的 MCD 显著更低。
3.2 语义特性的“降噪”效果
通过下表可以看到,虽然 WavLM 在纯语音 PPL 上有微弱优势(源于其 BERT 结构的音素敏感性),但在音乐和通用音效领域,OmniCodec 展示了压制性的语义表征能力,这对于构建全能音频助手至关重要。
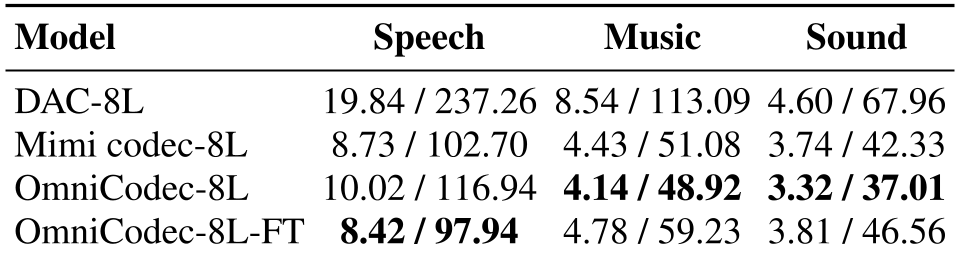 表 4:不同模型在各领域下的 PPL(Perplexity)表现。
表 4:不同模型在各领域下的 PPL(Perplexity)表现。
4. 深度洞察:为什么 Self-guidance 有效?
在消融实验中,去掉 Self-guidance loss 会直接导致码本利用率从 98.2% 下降到 97.4%。
学术直觉:自引导实质上是在潜在空间(Latent Space)中进行了一种“一致性正则化”。它告诉模型:“无论我用的是连续的精细特征,还是被量化后的离散特征,你解码出的结果都应该是稳定的。”这种约束大大减轻了量化带来的信息断层(Artifacts),是提升低比特率音质的神来之笔。
5. 局限与未来
尽管 OmniCodec 在多领域表现卓越,但在语音解耦方面仍面临挑战。由于音乐数据量比例的差异,纯语音的精细度在极端低帧率下仍有提升空间。作者指出,未来的研究将探索更灵活的数据配比方案,并考虑将 WavLM 与有监督编码器进行联合蒸馏,以取长补短。
结论:OmniCodec 为音频 LLM 提供了一个高性能、全场景的“数字嘴巴”,其开源特性(模型与代码均已发布)必将加速通用音频生成领域的研究进程。