本文提出了基于认知负荷相关的语言特征来预测解释性对话中听者理解状态的方法。该研究利用 MUNDEX 多模态语料库,通过信息值(Surprisal)、句法复杂度和听者注视熵(Gaze Entropy)三类特征,实现了对“理解、部分理解、不理解、误解”四种状态的自动分类,其中微调后的 German BERT 结合多模态特征表现最优。
TL;DR
在解释性对话中,听者是否真的听懂了?本文探讨了如何通过分析说话人的句法复杂度、**信息惊奇度(Surprisal)以及听者的注视行为(Gaze Entropy)**来实时预测听者的理解状态。研究发现,这些与认知负荷(Cognitive Load)强相关的特征能显著提升模型对“懂、半懂、不懂、误解”四种状态的识别能力,最高准确率达到 81.6%。
痛点深挖:为什么 AI 很难“察言观色”?
社交可解释 AI(Social XAI)的核心目标是根据用户的实时反馈调整解释策略。然而,现有的研究存在两个主要局限:
- 粒度过粗:大多数系统只能简单判断“懂”或“不懂”,无法识别“看似懂了实则误解”的情况。
- 缺乏理论支撑的特征工程:很多模型盲目喂入原始视频数据,而忽略了心理语言学中认知负荷与理解水平之间的物理联系。
本文的动机在于:理解是一个消耗认知的过程。如果解释内容过于生僻(Surprisal 高)或结构过于复杂(Syntactic Complexity 高),听者的认知负荷会激增,这种压力会通过非言语行为(如注视回避)外化。
核心方法论:量化“理解”的物理指标
作者从 MUNDEX 语料库出发,提取了三个维度的认知负荷指标,并设计了一套特征融合流水线。
1. 三大核心特征的数学定义
- 信息值 (Information Value):基于 German GPT-2 词级别的平均 Surprisal。公式如下:
- 句法复杂度 (Syntactic Complexity):结合了句子长度 、依赖头数量 和语法树最大深度 。
- 注视熵 (Gaze Entropy):通过 OpenFace 捕捉听者注视点,并利用 Transformer 计算注视序列的可预测性。注视越零散(熵越高),通常意味着认知加工越吃力。
2. 模型架构:BERT 遇到语言学特征
作者并没有简单的堆叠特征,而是采用了**特征融合(Feature Fusion)**策略:
- 使用 German BERT 提取文本隐含层表示(取最后 4 层,因为这几层更偏重语义和指代信息)。
- 将上述三大手工特征(Linguistic Cues)拼接到 BERT 的向量之后。
- 通过 Linear Layer 进行四分类。
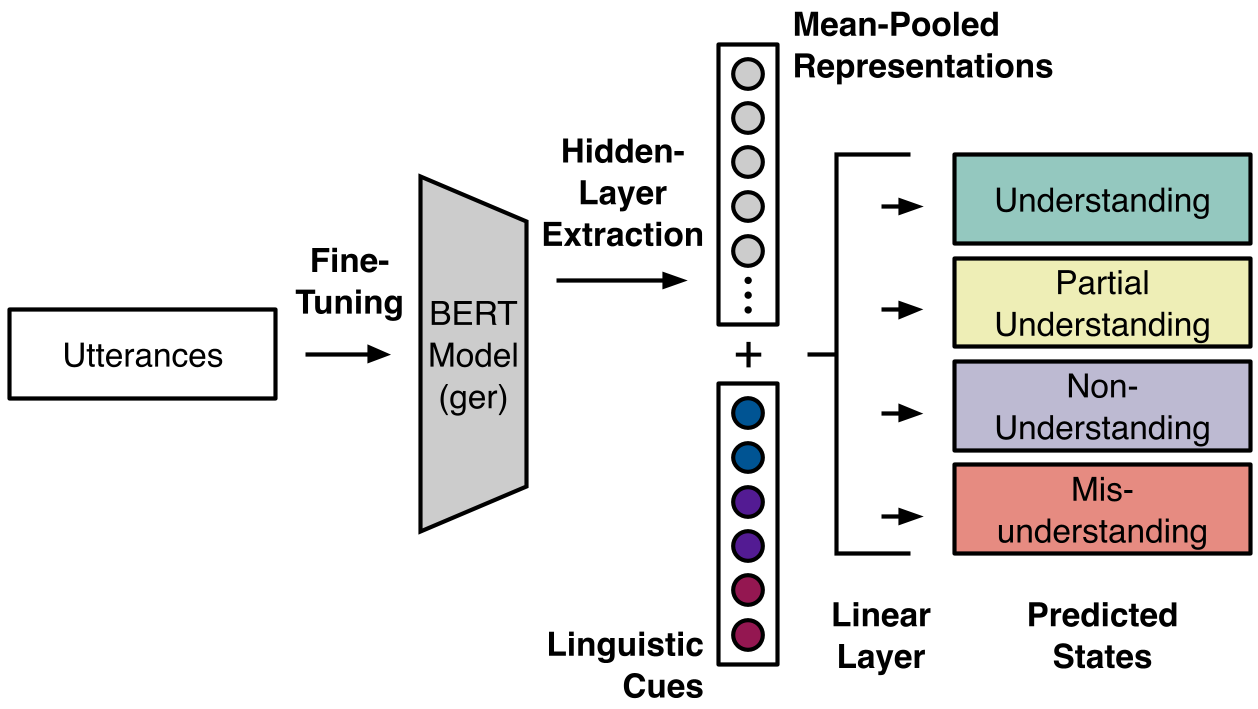 图 1:基于特征融合的 BERT 理解状态分类器架构
图 1:基于特征融合的 BERT 理解状态分类器架构
实验与结果:认知负荷真的能预测理解吗?
统计显著性
实验首先验证了这些特征在不同理解状态下的差异。结果显示,信息值和注视熵在“理解”和“不理解”状态下有显著的中位数差异。有趣的是,研究发现:当解释内容的 Surprisal 较高时,听者反而更倾向于报告“理解”,这可能是因为高信息密度激发了更高的注意力集中度(Attention Engagement)。
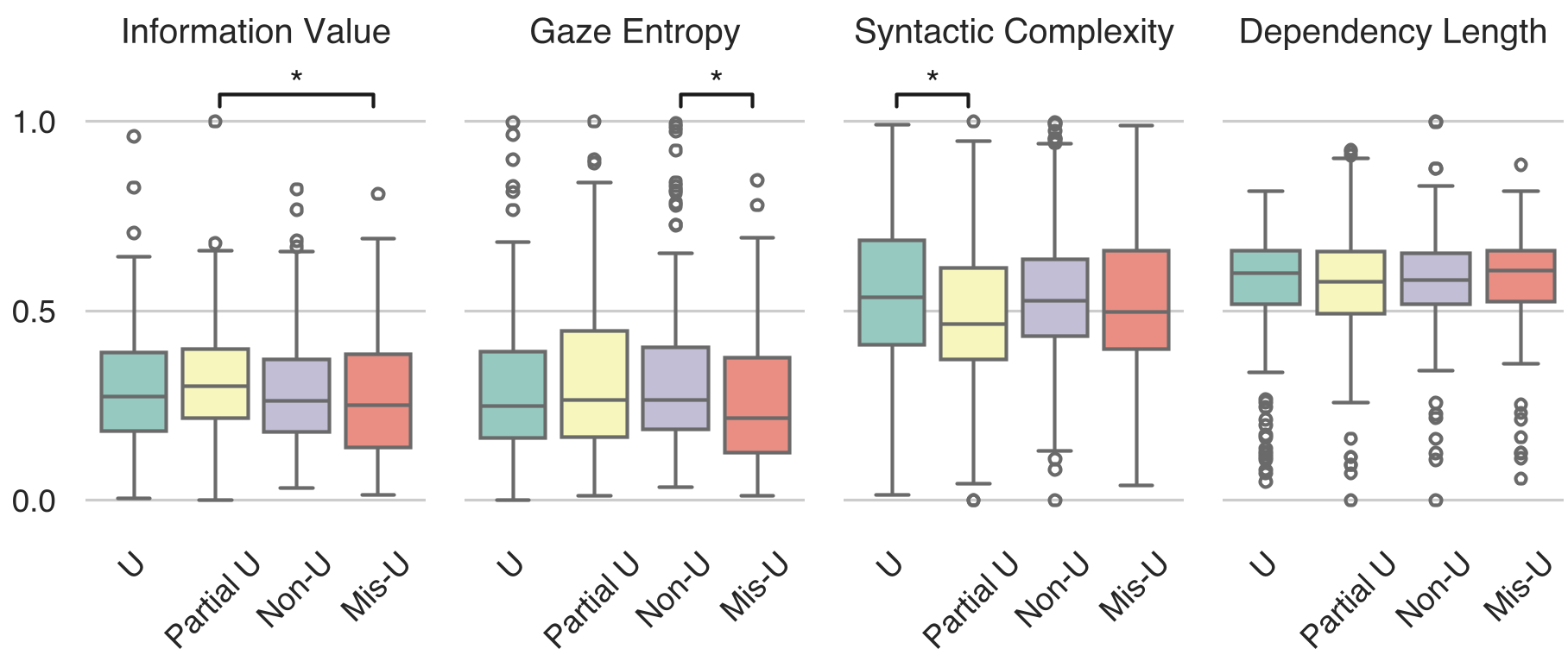 图 2:不同理解状态下各项语言/行为指标的分布差异
图 2:不同理解状态下各项语言/行为指标的分布差异
分类性能
在多类分类任务中,BERT 融合模型展现了强大的 Baseline。相比于传统的随机森林(RF)和 XGBoost,BERT 模型能捕捉更深层的语境特征。
- 关键发现:“不理解 (Non-Understanding)”最容易预测(F1=0.82),可能因为其语言和注视模式最具有代表性。
- 挑战点:“误解 (Misunderstanding)”表现最差,这验证了交互中的常识:用户往往在一段时间之后才意识到自己之前产生了误解。
深度洞察:迈向社交智能
该研究揭示了一个关于反馈机制(Grounding Process)的深刻道理:听者的状态不仅仅取决于听者本身,更取决于说话者提供的“认知载荷”。
局限性与展望
- 数据极度稀缺:MUNDEX 虽然质量高,但样本量对深度学习仍显薄弱。
- 文化普适性:德国人的反馈模式(如点头、注视)可能与亚洲或美国文化存在显著差异,未来需跨语种验证。
- 未来的多模态补完:作者计划加入音高(Pitch)、语质(Voice Quality)和手势特征,构建一个真正的全模态理解监测器。
总结 (Takeaway):这篇论文构建了从“心理语言学理论”到“机器学习实践”的桥梁。对于下一代智能助理而言,不仅仅要优化“生成的准确性”,更要学会“通过用户的眼神和句法复杂度来评估自己的解释效果”。