本文提出了 PRISM,这是一个针对大语言模型(LLM)Mid-training 阶段设计选择的全面实证研究。通过在 3B 到 24B 规模的多种架构(Transformer 及 Mamba 混合架构)上进行 ~27B 高质量 token 的训练,该方法在保持通用能力的同时,显著提升了模型的数学、代码和科学推理能力。
TL;DR
传统的 LLM 训练往往跳过预训练(Pre-training)与对齐(Alignment)之间的中间地带。IBM Research 发布的 PRISM 框架通过实证研究证明:仅需 ~27B 的高质量混合数据进行 Mid-training,即可让 8B 规模的模型在数学、代码等硬核推理任务上产生质变,并为随后的强化学习(RL)铺平道路。
背景定位:这是一篇典型的“练功指南”式论文,不仅刷新了 SOTA 榜单,更通过深度的机械论分析(Mechanistic Analysis),厘清了数据成分、长文本保留与 RL 交互之间的复杂关系。
为什么 Mid-training 是必不可少的?
在 LLM 的生命周期中,基座模型(Base Model)虽然博学但“鲁钝”。直接对其进行 RL 往往效果不佳,原因在于:
- 分布鸿沟:预训练数据的海量杂乱与推理任务的严谨逻辑之间存在巨大鸿沟。
- 能力缺失:基座模型往往缺乏长链条推理(Chain-of-Thought)的表达习惯。
- RL 的局限性:实验证明,RL 只能对模型进行“手术刀式”的稀疏微调(更新约 5% 参数),如果 Mid-training 没有预先构建好推理的“表征几何结构”,RL 将无从下手。
PRISM 核心方法论:精密的数据炼金术
PRISM 的成功并不依赖于单纯的数据堆砌,而是源于对三类关键变量的精准控制:
1. 数据配比(The Mixture)
PRISM 将数据分为通用 Web 数据(保证不“变傻”)、数学/代码推理数据(建立逻辑基石)以及科学数据。作者发现,科学数据的引入对 RL 阶段有奇效:在 Mid-training 中加入科学数据,能让模型在随后的 RL 阶段于 GPQA-Diamond 榜单上额外爆发 17-28 点的提升。
2. 架构通用性
PRISM 不仅适用于标准的 Dense Transformer(如 Llama 3.1, Mistral),在 Attention-Mamba Hybrid(如 Nemotron-H)架构上也表现出极强的鲁棒性。
3. 长文本能力的“回春术”
Mid-training 通常在短序列(8k)上进行,这会破坏预训练时习得的长文本处理能力。PRISM 提出了一个优雅的解法:线性合并(Linear Merge)。
- 将 Mid-training 后的模型与基座模型按 85:15 的比例合并。
- 进行极短时间的恢复性训练。
- 结果:RULER 分数从几近崩溃的 6.46 迅速恢复至 42.16,同时保留了推理增益。
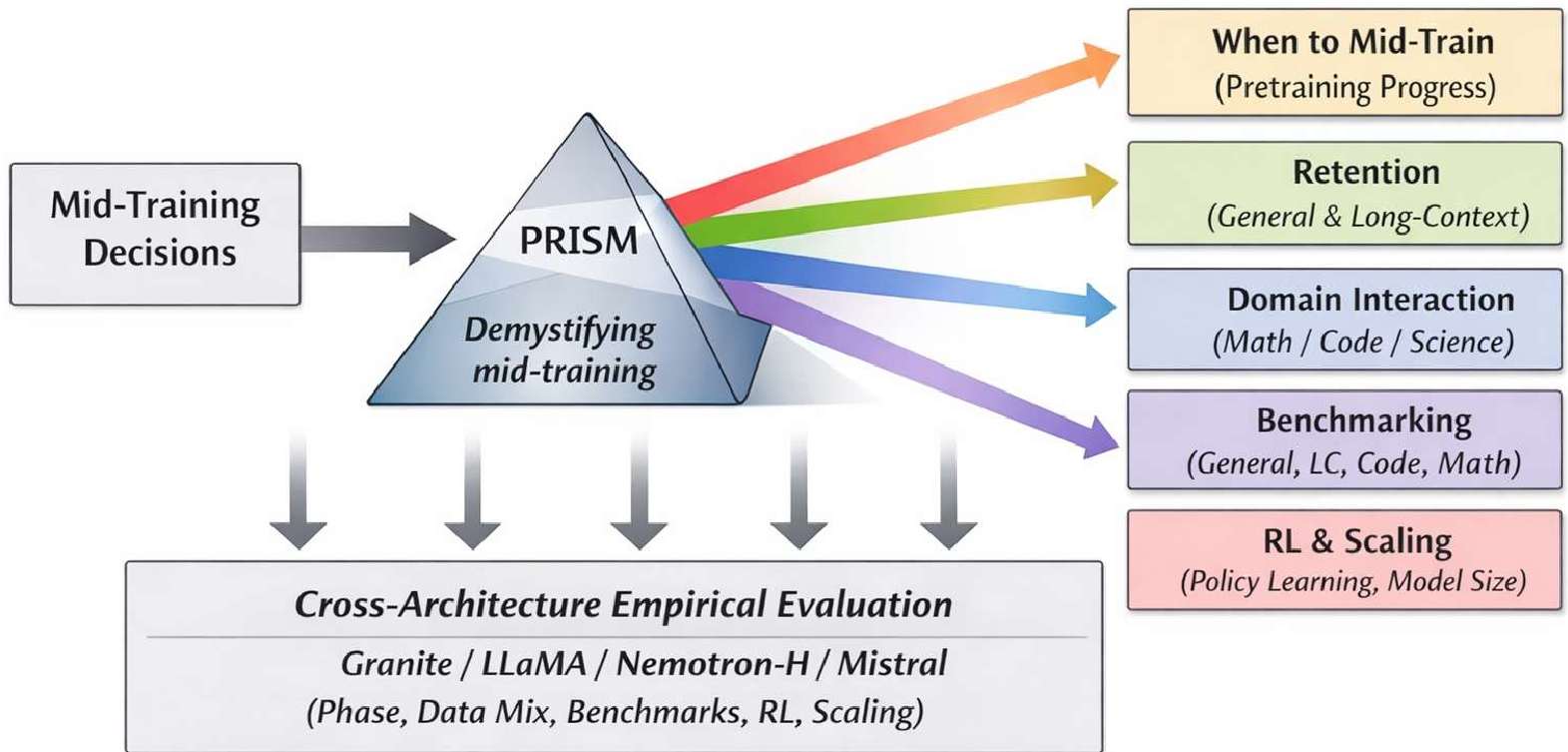 图 1:PRISM 实验框架图,涵盖了从数据交互到下游 RL 兼容性的全流程分析。
图 1:PRISM 实验框架图,涵盖了从数据交互到下游 RL 兼容性的全流程分析。
实验战绩:推理能力的 4 倍飞跃
在 Granite-3.3 (8B) 等模型上的实验表明,PRISM → RL 管道比单纯的 Base → RL 强大得多。
- 数学突破:在 AIME 基准测试中,基座模型直接做 RL 几乎得不到分,而经过 PRISM 处理后的模型得分从接近 0 飙升至 30-40 分水平。
- 可解边界的扩张:通过对失败案例的追踪,作者发现 RL 不仅仅是优化了已有的答案,它确实在 PRISM 奠定的基础上“悟出”了原本无法解决的新问题。
 表 6:PRISM 在多种参数规模和架构下的性能提升预览。
表 6:PRISM 在多种参数规模和架构下的性能提升预览。
深度洞察:Mid-training 与 RL 在本质上做了什么?
这是本文最令人兴奋的发现。作者利用 CKA(Centered Kernel Alignment) 和权重散度分析,揭示了两者的分工:
- Mid-training 是“重塑”:它会对模型 >90% 的参数进行剧烈调整。它并没有改变模型的通用认知,而是重新校准了预测的置信度,并引导模型生成更长的思维链。
- RL 是“精雕”:RL 的参数更新量比 Mid-training 小 370-580 倍。CKA 分析显示,RL 阶段模型的内部表征几何结构几乎没有变化(相似度 > 0.998)。
- 结论:Mid-training 负责在大脑中“修路”(构建推理几何),RL 负责在路上“跑车”(优化策略选择)。
总结与启示
PRISM 告诉我们:不要指望 RL 能凭空创造奇迹。 如果你想让模型具备强大的推理能力,必须在 Mid-training 阶段下足功夫,通过高质量的混合数据将模型的权重配置推到一个“易于被 RL 优化”的甜点位(Sweet Spot)。
局限性:虽然 24B 规模已经涵盖了主流应用,但在 70B 以上的超大规模模型上,Mid-training 的成本效益曲线是否依然如此陡峭,仍需进一步验证。
本文由资深学术技术主编重构。如需深入了解,请参阅 arXiv 原文《PRISM: Demystifying Retention and Interaction in Mid-Training》。