本文提出了 Realtime-VLA V2,一套旨在提升 Vision-Language-Action (VLA) 模型在真实机器人上执行速度、平滑度与准确性的系统级框架。通过结合精密的时间延迟校准、学习型速度自适应模型以及两阶段轨迹优化(时间和空间优化),该方法使机器人在复杂任务中的执行速度达到了接近人类操作的水平。
TL;DR
即使拥有最先进的 VLA (Vision-Language-Action) 模型,机器人往往运行得像“幻灯片”一样缓慢且僵硬。Dexmal 团队推出的 Realtime-VLA V2 改变了这一现状。通过一套严密的系统工程方案——包括物理延迟校准、速度自适应学习和双重轨迹优化,模型生成的动作不仅能跑得快(超越演示速度),而且极其平滑和精准,在多个复杂任务中展现出了足以媲美人类的执行效率。
痛点深挖:为什么机器人跑不快?
在学术研究中,我们习惯于关注模型的 Zero-shot 能力,但在实际部署时,Cycle Time(循环时间) 才是决定工业价值的核心指标。
- 时间错位 (Temporal Misalignment):从相机采集图像到机械臂产生动作,中间隔着读取延迟、推理延迟和通信延迟。如果不加补偿,模型看到的“现在”其实是“过去”。
- 硬件限制与震动:轻量级机械臂(如 QDD 臂)刚性较弱。简单地压缩动作时间会导致严重的加速度突变,引发机械震动,这不仅伤硬件,更会让视觉反馈变得模糊。
- 演示数据的诅咒:模仿学习通常限制在人类演示的速度下,而人类手动示教往往因为反馈延迟而操作缓慢。
核心方法论:从时间校准到空间优化
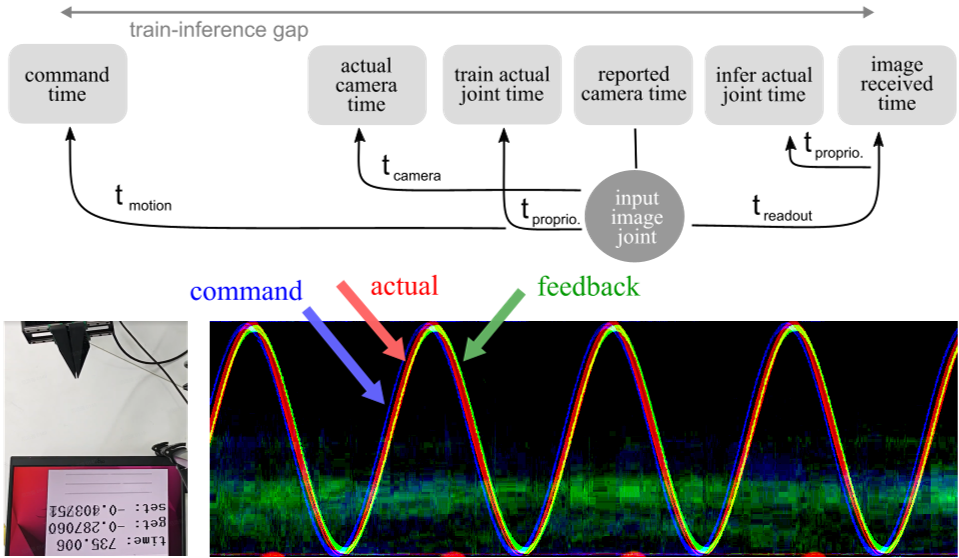
1. 毫秒级的物理校准
作者构建了一个极其精妙的校准系统(见下图)。通过 LED 灯条和高 fps 相机,精确识别出 t_camera、t_readout、t_proprio(本体感受延迟)以及高达 150ms 的 t_motion(运动跟踪延迟)。
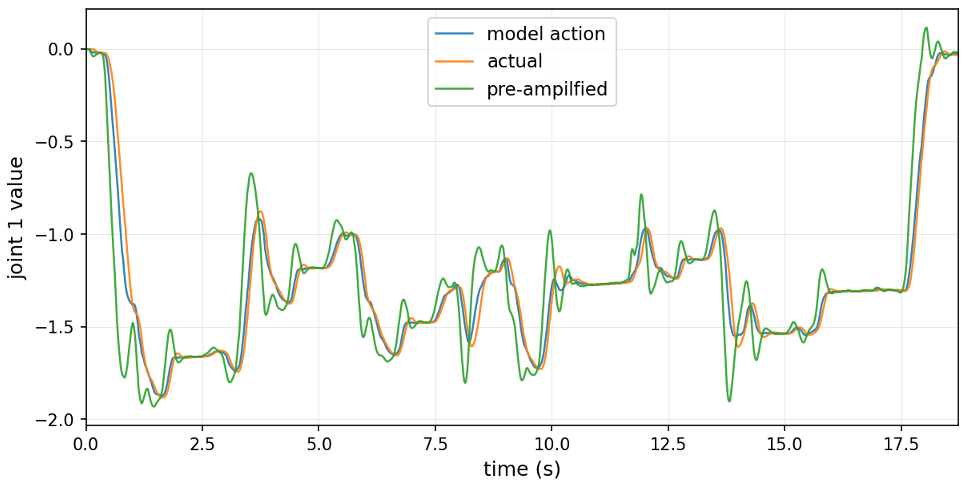
为了抵消 t_motion,系统引入了预放大 (Pre-amplification) 机制。如轨迹图所示,发送给机器人的指令比模型预期的更“激进”,通过硬件自身的 PD 控制器过滤后,实际轨迹反而能完美贴合模型目标。
2. 两阶段优化流水线
为了确保高速下的“稳”,系统设计了严密的后处理流水线:
- 时间优化 (Temporal Optimization):在服务器端通过 QP 求解,重新分配动作快照的时间进度,消除突发的关节跃迁,确保加速度曲线圆润。
- 空间优化 (Spatial Optimization):在客户端(机器人本地)运行 MPC 算法(基于 acados)。它考虑了机械臂的实际响应动力学,对指令进行最终的微调,确保即使网络波动,机器人也不会偏离轨道。
3. 学习“快”的艺术
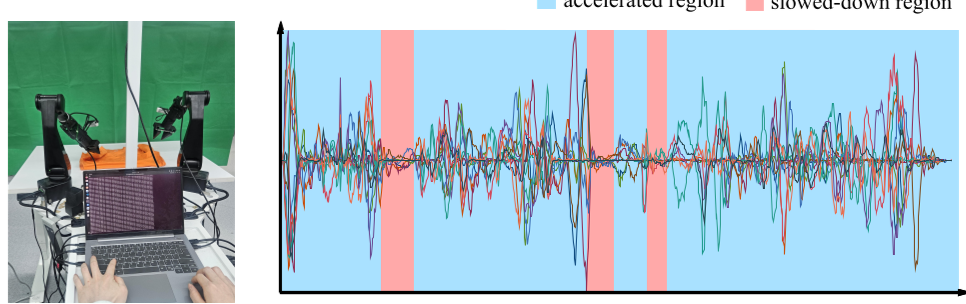
并非所有动作都能加速。在“叠衣服”任务中,平移动作可以极快,但“捏起衣角”需要减速以保证精度。作者发明了人机协同速度调制:人类操作员在模型运行时像踩油门一样实时调整速度,数据随后被用于训练一个回归模型,让 VLA 学会什么时候该“飙车”,什么时候该“收油”。
实验与结果:性能的极限挑战
团队在三种极具挑战性的任务上进行了验证:
- 叠衣服:对平滑度要求高,需处理柔性物体。
- PCB 插件:精度要求极高,边隙仅 0.2mm,模型学会了在插入瞬间智能减速。
- 工件装配 (Pick-and-latch):结合了力度与高精度定位。
结果显示,Realtime-VLA V2 的动作逻辑非常自然,不再有传统 VLA 常见的“思考停顿”,其轨迹在加速度和 Jerk(加加速度)分布上表现得非常均衡。

深度洞察:Roofline 模型在机器人上的投影
作者提出了一个非常有启发性的观点:机器人的速度瓶颈可以类比为计算领域的 Roofline Model。
- 运动受限区 (Motion Bound):硬件的物理加速度已达极限。
- 控制受限区 (Control Bound):硬件能跑更快,但由于控制链路延迟太大,提速会导致闭环失效。
该工作的成功在于通过精准校准,将“控制受限”的问题转化为“物理受限”的问题,从而压榨出了硬件的最后一分潜力。
总结
Realtime-VLA V2 不仅仅是一个模型预测器的改进,更是一次对机器人闭环控制系统的重新审视。它告诉我们:要让大模型真正落地,理解并尊重物理世界的延迟规律与力学约束,与设计巧妙的神经网络架构同样重要。
更多关于实测轨迹与无倍速视频请访问项目主页:dexmal.github.io/realtime-vla-v2/