本文提出了一种统一的概率图模型框架,用于描述基于代理(Proxy-based)的测试时对齐方法。通过引入一种全新的“保守置信度博弈”(Conservative Confidence Bet)拒绝标准,该方法在多个推理任务上超越了现有的 Nudging 和 KAD 等 SOTA 基准。
TL;DR
在大型语言模型(LLM)的对齐领域,传统的监督微调(SFT)和偏好学习(RLHF)代价极其昂贵。测试时对齐(Test-time Alignment)作为一种高效替代方案,通过在推理时动态修正模型分布来实现对齐。本文提出,现有的对齐方法本质上都是一种“拒绝采样”过程。作者通过引入保守置信度博弈(Conservative Confidence Bet),解决了大模型因语言歧义而产生的假性不自信问题,在数学和常识推理任务中取得了显著的 SOTA 性能。
背景定位:从训练对齐到推理对齐
将模型对齐到人类偏好通常需要海量算力和精心标注的数据。近期研究转向了“代理辅助”模式:用一个已经对齐的小模型(如 1B 的 )来指导一个未对齐的大基础模型(如 13B 的 )。这就像是给一个知识渊博但口无遮拦的学者配了一名谨小慎微的助理。
现有的方法主要分为两派:
- 隐式奖励派:利用大小模型的对数概率差作为奖励信号。
- 触发切换派(Nudging/KAD):当大模型“不自信”时,把接力棒交给小模型。
痛点深挖:模型是真的“迷茫”还是“左右为难”?
作者指出,现有的拒绝准则(Rejection Criterion)存在一个根本性直觉缺陷:它们只看大模型自己选的 Token 概率够不够高。
但在自然语言中,存在大量的语义歧义(Ambiguous Phrasing)。例如,“Frameworks like Pytorch”和“Frameworks such as Pytorch”都是完美的表达。此时,大模型的概率质量会平摊给 “like” 和 “such”,导致每个 Token 的绝对概率都低于 0.5。按照旧准则,这会被判定为“不自信”而触发切换,但实际上大模型此时的生成是非常高质量的。
核心贡献:概率图模型的统一与博弈准则
作者首先在理论上确立了代理对齐的统一框架:
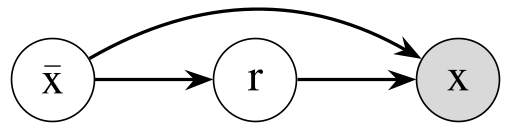
在这个 PGM 模型中,生成过程变为:先从大模型采样一个“草稿” ,然后由拒绝分布 决定是否接受。作者通过数学证明(Proposition 1)发现,即便是复杂的隐式奖励方法,本质上也只是这个图中特定参数下的一个特例。
保守置信度博弈 (Conservative Confidence Bet)
为了解决歧义问题,作者提出了核心公式:
直觉解析:不再设定死板的 0.5 或 0.3 阈值,而是让大模型选出的 Token 和小模型认为全场最好的 Token 进行现场 PK。只有当大模型的选择显著差于小模型的最佳建议时,才进行拒绝。这巧妙地绕过了因多个正确选项导致的概率稀释问题。
实验与结果:小助理立大功
实验覆盖了 GSM8K(数学)、MATH500、ARC(常识推理)等多个高难度 benchmark。
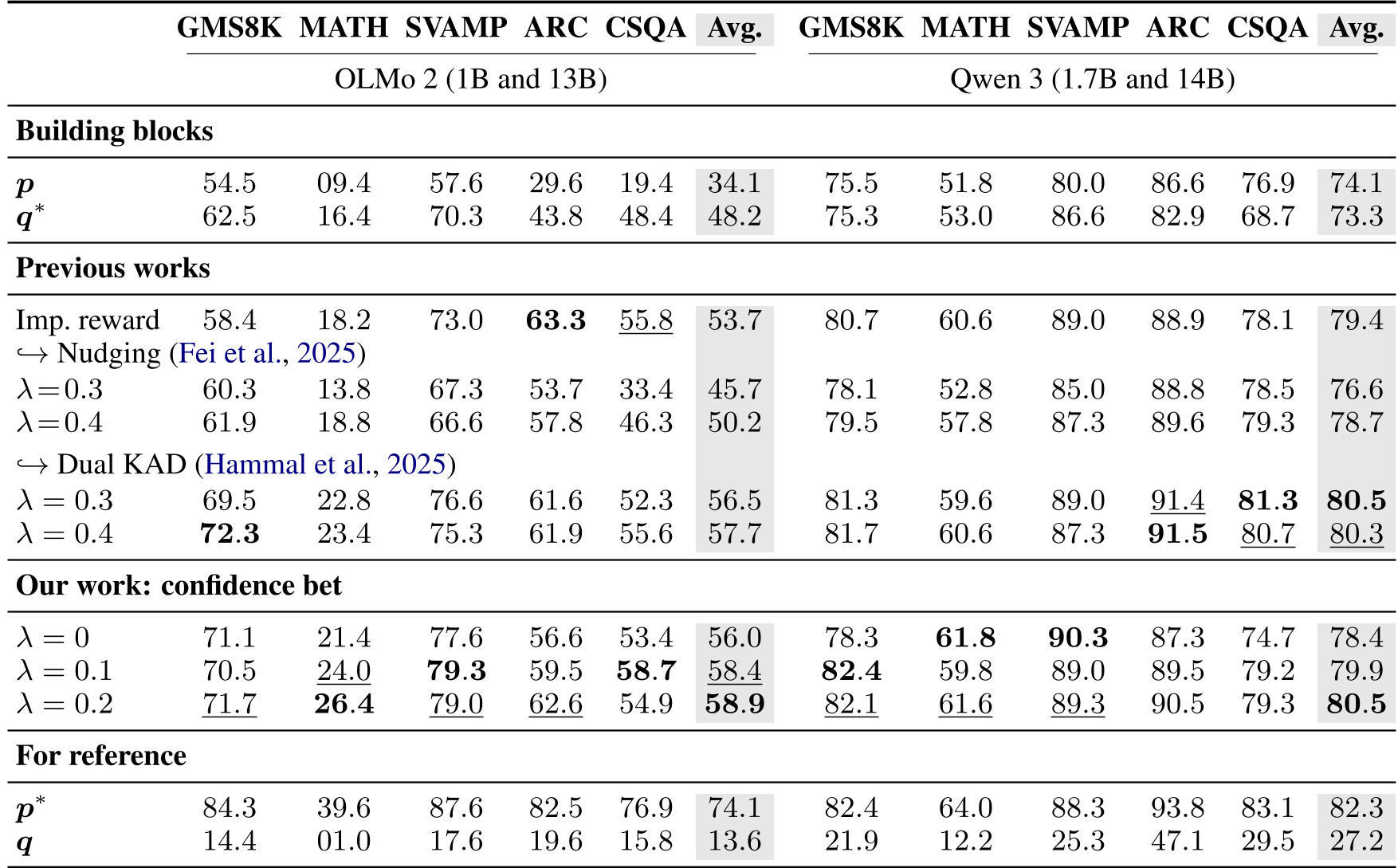
关键结论:
- 跨模型有效性:在 OLMo 和 Qwen 两个系列上,新准则均表现优异。
- 数学任务暴涨:在 MATH500 任务中,OLMo 2 (13B) 的表现从原本的 9.4% 直接飙升至 26.4%,涨幅达 180%。
- 效率平衡:相比于完全使用大模型对齐版本(),这种“草稿-拒绝”机制显著降低了推理成本,且性能非常逼近原生对齐模型。
深度洞察与总结
本文的价值在于它打破了“置信度即对齐”的迷思。它告诉我们:对齐不是为了消除不确定性,而是为了在不确定中做出符合预期的选择。
局限性: 目前该方法仍需在小型验证集上调整超参数 。未来的方向可能在于如何根据上下文动态学习这个“博弈边界”,实现完全自动化的测试时对齐。
启示: 对于开发者而言,如果你手头有一个强大的 Base 模型和一个微调过的同系列小模型,使用这种“博弈拒绝”策略可能比单纯的重采样或直接调用对齐模型更具性价比。