本文提出了 RewardFlow,一种为大语言模型(LLM)智能体(Agent)设计的轻量级过程奖励估算方法。该方法通过构建状态图(State Graph)并利用拓扑感知奖励传播(Topology-Aware Reward Propagation),在无需额外训练奖励模型的情况下,将稀疏的终端奖励转化为稠密的中间状态奖励,显著提升了强化学习(RL)在复杂推理任务中的性能。
TL;DR
在强化学习训练 LLM 智能体(Agent)时,我们常常面临“过程很努力,结果无反馈”的尴尬:任务执行几十步,只有最后一步才知道输赢。RewardFlow 另辟蹊径,它不依赖昂贵的人工标注奖励模型(PRM),而是通过将智能体的尝试轨迹织成一张“状态图”。利用图论中的拓扑传播算法计算每个中间步骤离“成功”有多远,从而自动生成高质量的过程奖励。实验显示,在视觉推箱子(Sokoban)任务中,该方法将成功率从 34.4% 狂拉到了 62.4%。
背景定位:从“盲目探索”到“精准导航”
目前智能体强化学习(Agentic RL)主要通过终端奖励进行优化。这种“轨迹级”的反馈非常粗糙,智能体分不清哪一步是关键助攻,哪一步是无用功。先前提出的 GiGPO 虽然尝试了过程估算,但忽略了智能体在不同尝试中可能多次经过同一个关键状态的拓扑特性。RewardFlow 的核心直觉是:如果一个状态在通往成功的路径上频繁出现,或者它距离成功状态在图上更近,它的价值就应该更高。
核心机制:状态图的构建与传播
RewardFlow 的工作流程分为三个关键阶段:
1. 状态图建模 (State Graph Modeling)
智能体在同一个任务下会进行多次 group sampling。RewardFlow 将这些轨迹中的相同状态合并为图中的唯一节点。为了处理 LLM 产生的细微状态差异,作者引入了状态归一化 (State Normalization),例如通过嵌入向量(Embedding)相似度将语义一致的状态聚类。
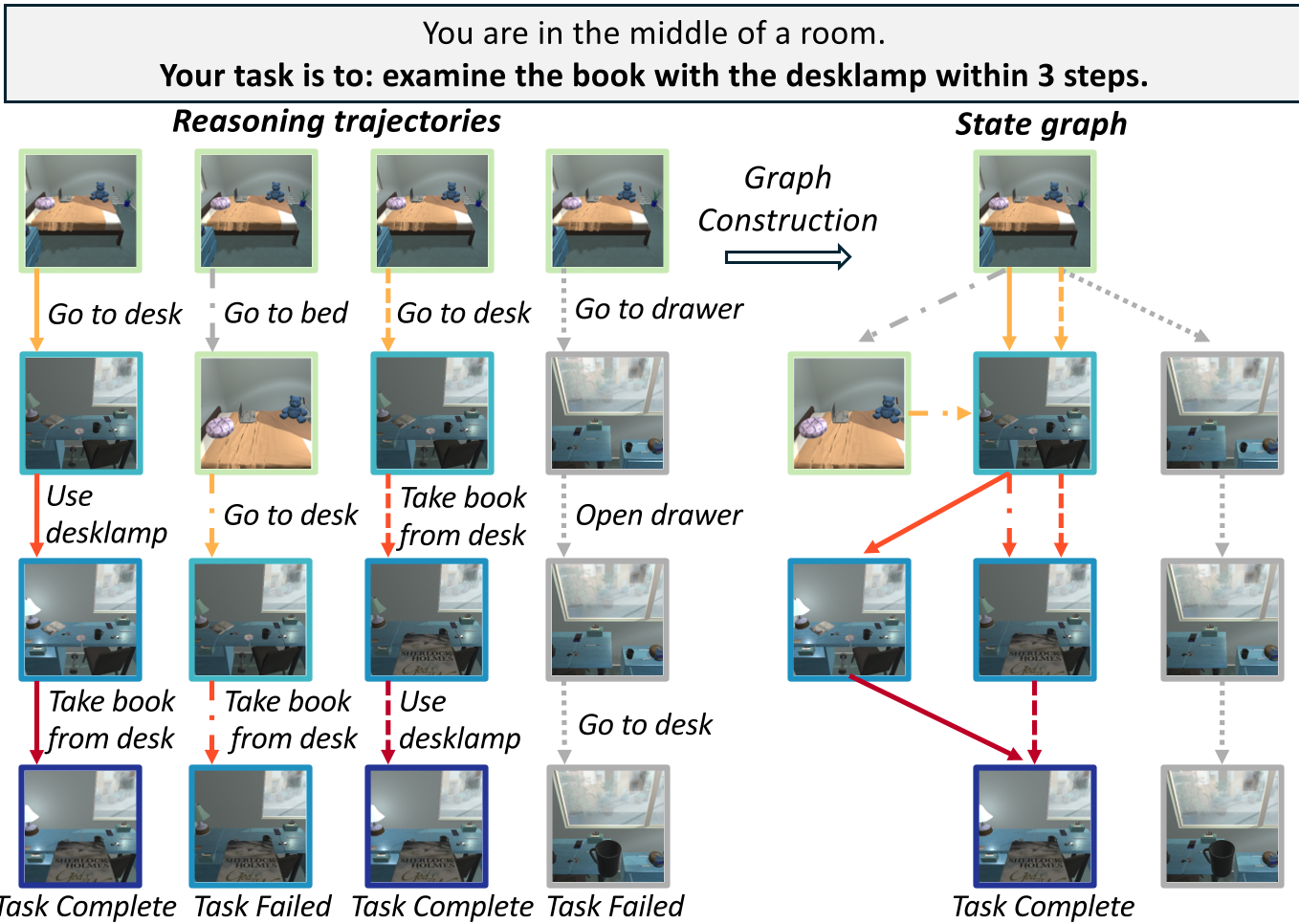 图 1:状态图构建示意图。通过聚合多次采样的等效状态,揭示任务的内在结构。
图 1:状态图构建示意图。通过聚合多次采样的等效状态,揭示任务的内在结构。
2. 拓扑感知奖励传播 (Graph Propagation)
一旦图结构建立,算法会从所有成功的终端节点开始,利用逆向 BFS(广度优先搜索)向后传播奖励。一个状态 的奖励值 取决于它到最近成功节点的跳数距离 : 这种设计捕捉了可达性 (Reachability) 和 接近度 (Proximity),让智能体明确知道哪些中间状态更有“冠军相”。
3. 协同优势估算 (Synergistic Advantages)
传统的动作优势(Advantage)往往只看全局胜率。RewardFlow 设计了协同机制:
- 动作级优势:对比同一状态下不同动作带来的“价值增益”()。
- 轨迹级优势:保留全局成败的宏观指导。
实验战绩:全线 SOTA
RewardFlow 在文本任务(ALFWorld, WebShop, DeepResearch)和视觉任务(Sokoban)上均展现了统治力。
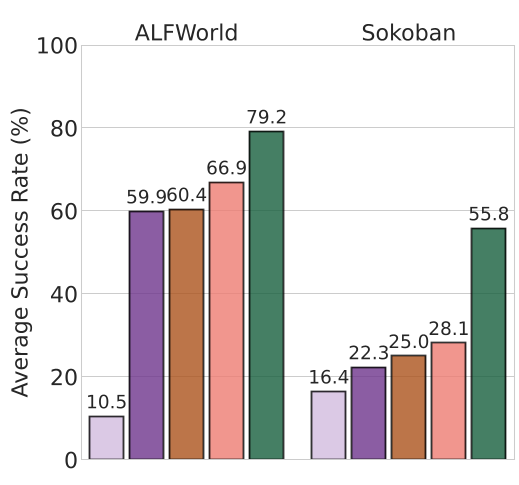 图 2:性能概览。RewardFlow 在多个基准测试中一致超越 GRPO、RLOO 等强力 RL 算法。
图 2:性能概览。RewardFlow 在多个基准测试中一致超越 GRPO、RLOO 等强力 RL 算法。
关键发现:
- 小模型的救星:在 1.5B/3B 等小规模模型上提升尤为显著。这表明精准的过程奖励能极大弥补模型本身探索能力的不足。
- 极高效率:如图 7 所示,图构建和传播的时间开销极低(小于 2.4s),相比动辄数小时的策略梯度更新,这几乎是“免费的午餐”。
- 鲁棒性强:即使只有 4 条采样轨迹,其效果依然优于拥有 8 条轨迹的其他算法。
深度洞察:为什么这很重要?
RewardFlow 的本质是利用图论的客观性取代了神经网络估算的主观性。 在传统的 PPO 或 GRPO 中,如果我们想得到过程奖励,必须训练一个 PRM。但 PRM 本身可能存在“奖励黑客”(Reward Hacking)问题。而 RewardFlow 基于“最短路径”和“状态连通性”提供的反馈是物理真实的、环境导向的。
局限性分析: 该方法目前依赖于能够清晰定义的“状态”。在极度开放、状态表示极其复杂的环境中(例如无结构的自由文本对话),如何进行高效的状态合并仍是一个挑战。
结论
RewardFlow 提供了一个优雅的框架,证明了智能体不需要昂贵的“教练”(额外的奖励模型),深挖自己探索过的轨迹背后的拓扑规律,就能自发地理解任务的轻重缓急。对于追求高效训练 Agent 的研究者来说,这无疑是一个极具启发性的方向。