本文提出了一种名为 Cascade 的卷积神经网络(CNN)解码器,专门用于量子纠错(QEC)。该方法利用量子低密度奇偶校验(QLDPC)码和表面码的几何结构,在 144, 12, 12 Gross 码等任务上达到了 SOTA 精度,逻辑错误率比现有解码器降低约 17 倍,且吞吐量提升 3-5 个数量级。
TL;DR
哈佛大学的研究团队推出了一种名为 Cascade 的卷积神经解码器。它通过将神经网络的几何归约偏置(Inductive Bias)与量子纠错码的拓扑结构相结合,不仅在速度上碾压了传统算法,更在精度上解析出了此前被忽略的**“瀑布区” (Waterfall Regime)**。这意味着在相同物理硬件条件下,我们能以更小的量子比特代价实现极低的逻辑错误率。
背景定位:为何现有的解码器“不够好”?
在通往大规模容错量子计算的路上,解码器是那个必须在微秒级完成任务的“交警”。
- BP (Belief Propagation):虽快,但在量子码中容易自旋,被复杂的简并错误模式困住。
- MWPM/Tesseract:精度高,但在处理高码率的 QLDPC 码时要么不适用,要么慢得像幻灯片。
作者敏锐地指出:之前的研究过度迷信码距 (Distance, d)。大家认为错误率按 缩放,但这只是最坏情况。实际上,如果解码器足够聪明,能够处理那些数量庞大但权重稍高的错误模式,就能进入一个抑制效率极高的“瀑布区”。
核心直觉:结构感知 (Structure-aware) 的神经网络
Cascade 并没有使用昂贵的 Transformer 全局注意力,而是回归了卷积的精髓。它基于三个物理直觉:
- Locality (局部性):错误通常在空间上是局部的,可以通过层层卷积实现“粗粒化”识别。
- Translation Equivariance (平移等变性):纠错码的稳定器测量在格点上具有重复性,规则应该是通用的。
- Anisotropy (各向异性):时间轴(测量错误)和空间轴(物理比特错误)的物理意义完全不同,需要方向敏感的卷积核。
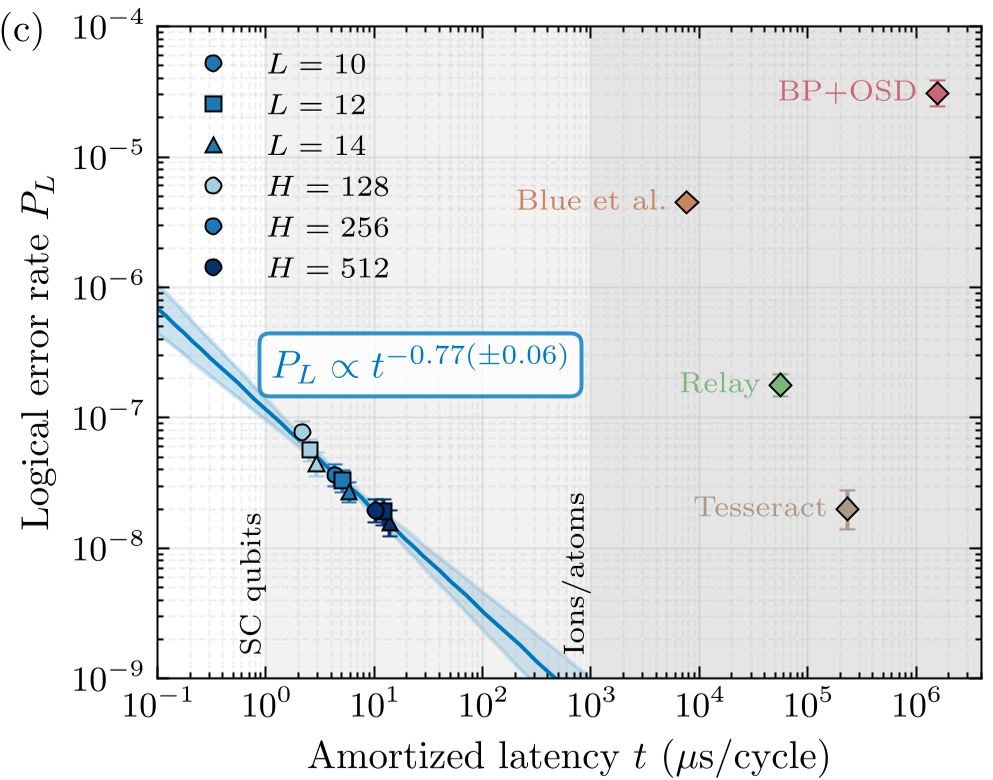 图 1:Cascade 架构展示,展示了从时空校正子(Syndrome)嵌入到 3D 卷积处理,最后映射回逻辑错误预测的过程。
图 1:Cascade 架构展示,展示了从时空校正子(Syndrome)嵌入到 3D 卷积处理,最后映射回逻辑错误预测的过程。
关键发现:“瀑布”效应与资源节省
论文最震撼的结论是图 1(b) 展示的逻辑错误率曲线。在 Gross 码中,Cascade 成功识别出了由大量高权重错误模式驱动的“瀑布项”(),这比传统的码距受限项()要陡峭得多。
这意味着:要达到 10⁻⁹ 的逻辑错误率,传统方法可能需要 d=19 的表面码,而 Cascade 配合先进纠错码只需 d=15。这直接导致物理量子比特的需求量减少了约 40%!
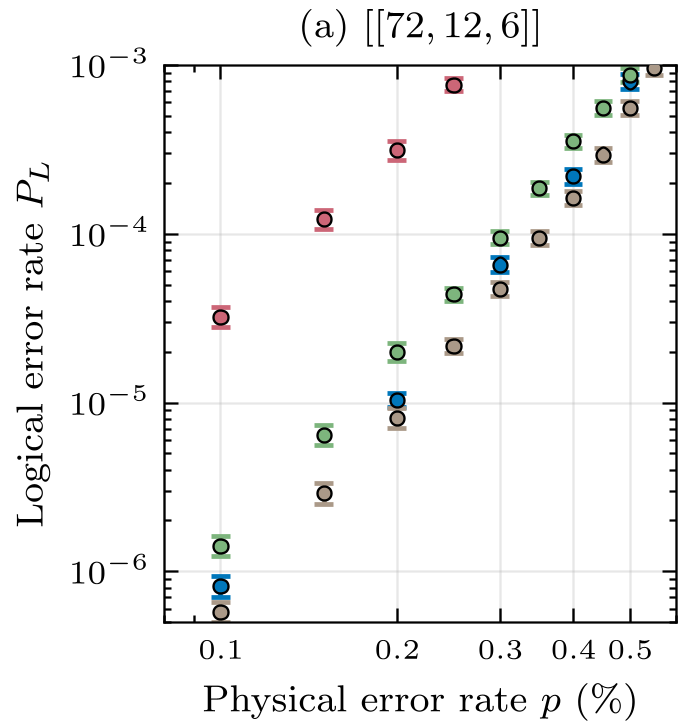 图 2:在不同规模的 BB 码下,Cascade (蓝色) 始终保持着对 BP+OSD (橙色) 和 Relay (绿色) 的代差级优势。
图 2:在不同规模的 BB 码下,Cascade (蓝色) 始终保持着对 BP+OSD (橙色) 和 Relay (绿色) 的代差级优势。
性能与硬件的前瞻
在 NVIDIA H200 上,Cascade 的批处理吞吐量达到了惊人的量级。更重要的是,它对 FP8 量化 表现出极强的鲁棒性(精度无损)。
| 平台 | 延迟要求 | Cascade 表现 | 结论 | | :--- | :--- | :--- | :--- | | 离子阱/中性原子 | ~1 ms | ~40 μs | 绰绰有余 | | 超导比特 | ~1 μs | 10-100 μs (GPU) | 需要专用的 ASIC/FPGA 加速 |
作者通过 Roofline 模型分析,如果将 Cascade 部署到专用硬件(如 AMD Versal),利用深度可分离卷积(Depthwise Conv),其实时延迟完全有望压进 1μs。
深度洞察:不仅仅是快
Cascade 还有一个被低估的贡献:置信度校准。 在复杂的量子算法中,有些步骤需要“重复直到成功”。Cascade 不仅告诉你“错没错”,还会告诉你它“有多大把握”。通过丢弃低置信度的实验结果,可以用极小的成本换取逻辑错误率两个数量级的下降。
总结与启发
这篇论文标志着量子纠错解码从“算法设计”向量化“架构设计”的转变。
- 未来展望:距离 (d) 不再是评价量子码的唯一标准,解码器与代码结构的协同设计 (Co-design) 将成为主流。
- 局限性:虽然精度与通用性极佳,但对于超导比特等极高性能要求的平台,仍需依赖底层硬件语言(如 Triton 或 Verilog)实现更极致的加速。
Cascade 的出现告诉我们,AI 并不总是需要昂贵的 Large Model,针对物理规律优化过的“小而美”卷积结构,在科学计算中依然拥有统治力。