This paper introduces Simulation Distillation (SimDist), a world-model-based framework for rapid sim-to-real adaptation in robotics. By pretraining a latent world model with diverse, sub-optimal simulation data and freezing task-specific components during deployment, SimDist achieves SOTA performance in precise manipulation and quadruped locomotion with only 15-30 minutes of real-world interaction.
TL;DR
SimDist (Simulation Distillation) is a new framework that treats sim-to-real transfer not as a policy fine-tuning problem, but as a system identification problem in a latent space. By pre-learning "what to do" (rewards/values) in simulation and only adapting "how the world moves" (dynamics) in the real world, it enables robots to adapt to complex new terrains (like PTFE slippery slopes or foam) in under 30 minutes.
Background Positioning: This work moves away from brittle end-to-end Model-Free RL finetuning and instead leverages the modularity of World Models to solve the "sim-to-real gap" with unprecedented sample efficiency.
Problem & Motivation: The Finetuning Fragility
Why do robots fail when they move from a simulator to the real world? The standard answer is the "dynamics gap"—physics in a simulator is too clean. However, the authors argue the real problem is how we finetune.
Current model-free RL (like SAC or PPO) entangles rewards, representations, and actions. When you try to finetune these on a real robot, the model often forgets the rich priors it learned in simulation (catastrophic forgetting) or fails to explore because it doesn't receive dense rewards.
The Insight: Global task structure (e.g., "the peg needs to go into the hole") is invariant between sim and real. Only the local dynamics (e.g., "how much friction is on this table") change. Therefore, we should freeze the intent and adapt the physics.
Methodology: Distilling the World Model
SimDist follows a three-stage pipeline:
- Simulated Teacher-Student Distillation: A state-based expert (using privileged info) teaches a vision-based world model. Crucially, the authors inject action perturbations (noise) so the model learns how to recover from failures—a concept known as "counterfactual reasoning."
- Frozen Global Priors: When the robot hits the real pavement, SimDist freezes the State Encoder, Reward Model, and Value Function.
- Local Dynamics Adaptation: The robot interacts with the world, and the only part of the neural network that updates is the Latent Dynamics Model. This turns RL into a much simpler supervised learning problem.
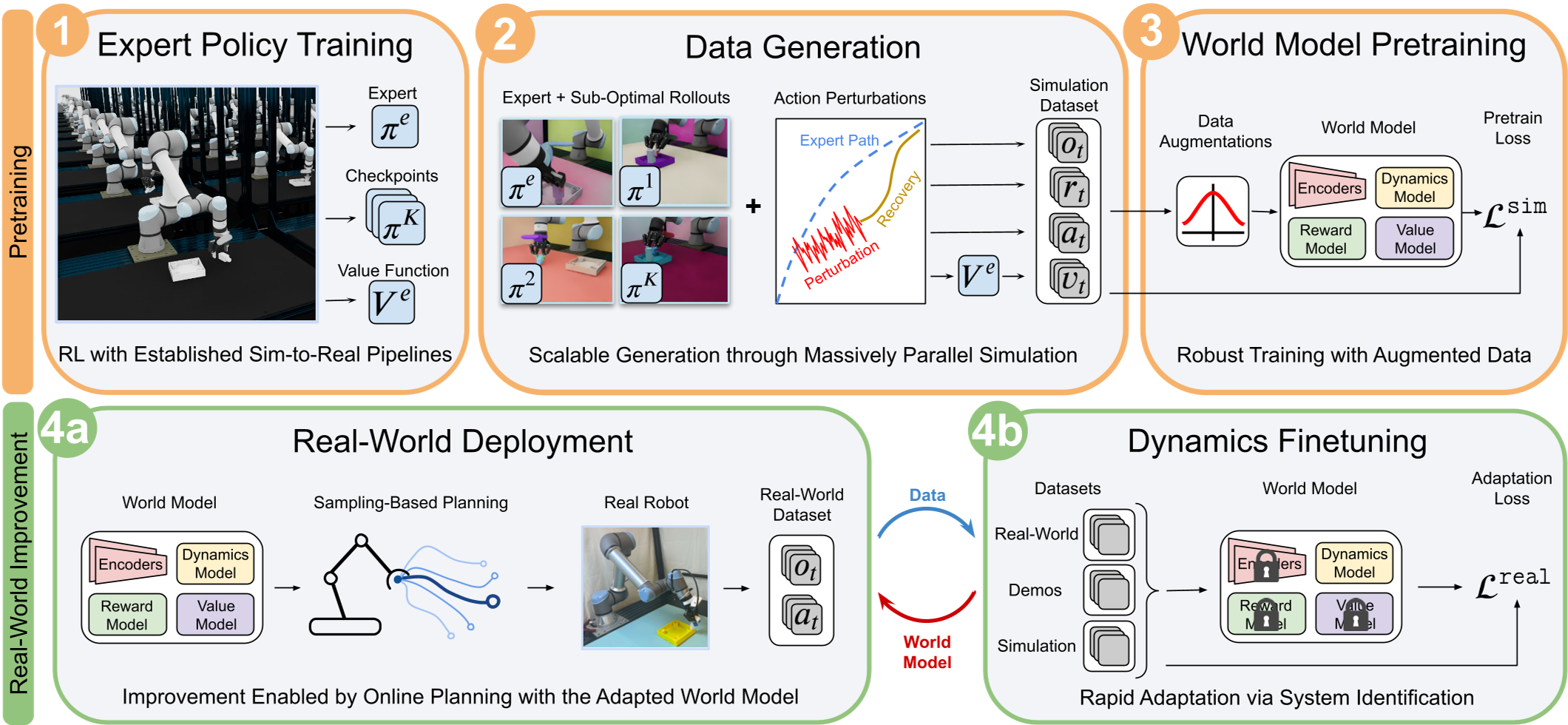
The architecture uses a multi-step Transformer instead of an autoregressive MLP. This allows the robot to "hallucinate" future trajectories in parallel on the GPU, enabling high-frequency Model Predictive Control (MPC) at 50Hz.
Experiments: Slippery Slopes and Compliant Foam
The authors tested SimDist on a Unitree Go2 quadruped and a UR5e arm.
- Quadruped Challenge: The robot had to cross PTFE (Teflon) plates and memory foam. These surfaces are notoriously hard to simulate.
- Results: While zero-shot policies slipped and fell, SimDist adapted within 30 minutes. It outperformed RLPD and IQL baselines, which often "collapsed" during training.
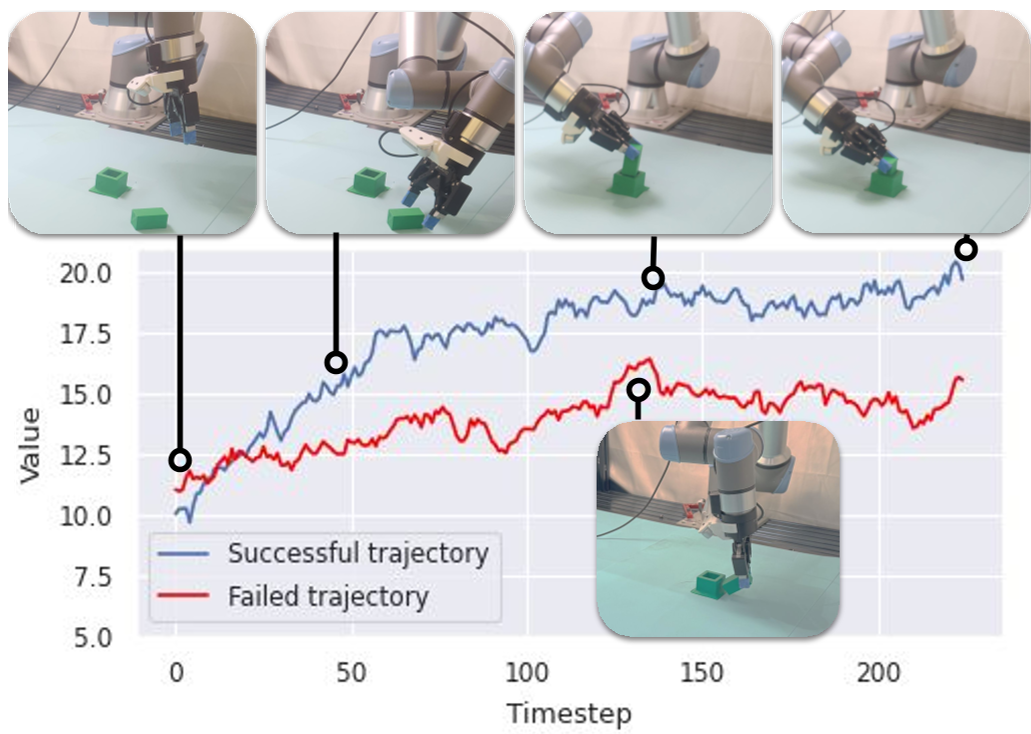 Fig: SimDist's frozen value function correctly identifies successful vs. failed trajectories in the real world, proving that "intent" transfers zero-shot.
Fig: SimDist's frozen value function correctly identifies successful vs. failed trajectories in the real world, proving that "intent" transfers zero-shot.
The paper includes a striking visualization of the "slip" prediction. Before finetuning, the model thought the foot would stay steady; after finetuning, it accurately predicted the slip, allowing the planner to adjust the robot's gait to stay balanced.
Deep Insight & Conclusion
The success of SimDist hinges on data diversity. In their ablation study, training on "expert-only" data caused performance to tank. This confirms that for a world model to be useful, it must see the robot struggle and fail in simulation so it knows how to handle those same failures in the real world.
Takeaway for the Industry: If you are building real-world robotic products, stop trying to finetune the whole policy. Distill a robust value function in a high-fidelity simulator, and treat the real-world deployment as a continuous supervised stream of dynamics updates.
Limitations: Currently, SimDist relies on high-fidelity simulators to learn the initial representation. If the simulator is too different (e.g., different lighting or object types), the frozen encoder might become a bottleneck. Future work in multi-task foundation world models may solve this.