本文提出了 SkillClaw,一个面向多用户智能体(Agent)生态系统的技能协作演化框架。该框架通过自主演化器(Agentic Evolver)自动聚合不同用户的交互轨迹,将静态技能库转变为能够根据现实失败案例和成功经验持续自我优化的动态系统,在 Qwen3-Max 模型上实现了显著的性能提升。
TL;DR
在大规模部署 LLM Agent 的时代,技能(Skills) 是 Agent 完成复杂任务的基石。然而,绝大多数系统的技能库在部署后就陷入了“冻结”状态。SkillClaw 彻底打破了这一僵局:它利用多用户产生的真实交互轨迹作为进化信号,引入一个“智能体演化器(Agentic Evolver)”自动诊断失败原因、重写技能流程,并经过严格的模拟验证后推送到全网。实验显示,这种“群体进化”模式能让模型在搜索检索任务中性能飙升 52%。
1. 痛点深挖:为什么你的 Agent 总是“记吃不记打”?
当前的 LLM Agent(如 OpenClaw 系列)面临一个尴尬的现实:个体经验无法转化为集体智慧。
- 隔离的失败:用户 A 发现某个搜索工具的端口变了,通过多次对话纠正了 Agent;但当用户 B 遇到同样问题时,Agent 依然会犯错。
- 静态的技能:目前的技能库通常是人工编写的 Markdown 或 SOP。一旦环境发生细微偏移(如 API 更新、文件路径变更),技能就会失效。
- 信噪比难题:单次交互的反馈可能是随机的,系统很难判断是一个偶然的错误还是需要修正的系统性缺陷。
SkillClaw 的核心 Insight 是:相同技能在不同 context 下的并发调用,构成了天然的“消融实验”。通过对比不同用户的成功与失败轨迹,系统可以精准定位哪些是环境强加的 hard constraints。
2. Methodology:SkillClaw 的进化闭环
SkillClaw 并不直接修改模型权重,而是修改 Prompt-level 的技能描述和流程。其架构遵循“白天生产数据,晚上进化技能”的逻辑。
2.1 结构化证据提取
系统不仅记录对话,还记录 Causal Chain(因果链)。这包括:
Prompt -> Action (工具调用) -> Feedback (环境返回/错误信息) -> Reasoning -> Response。
许多技能层面的失败(如参数格式不对)不会体现在最终答案里,只有看中间过程才能诊断。
2.2 Agentic Evolver:以毒攻毒
作者使用一个高能力的 LLM 作为演化器,它不再通过预定义的规则更新,而是进行开放式推理。
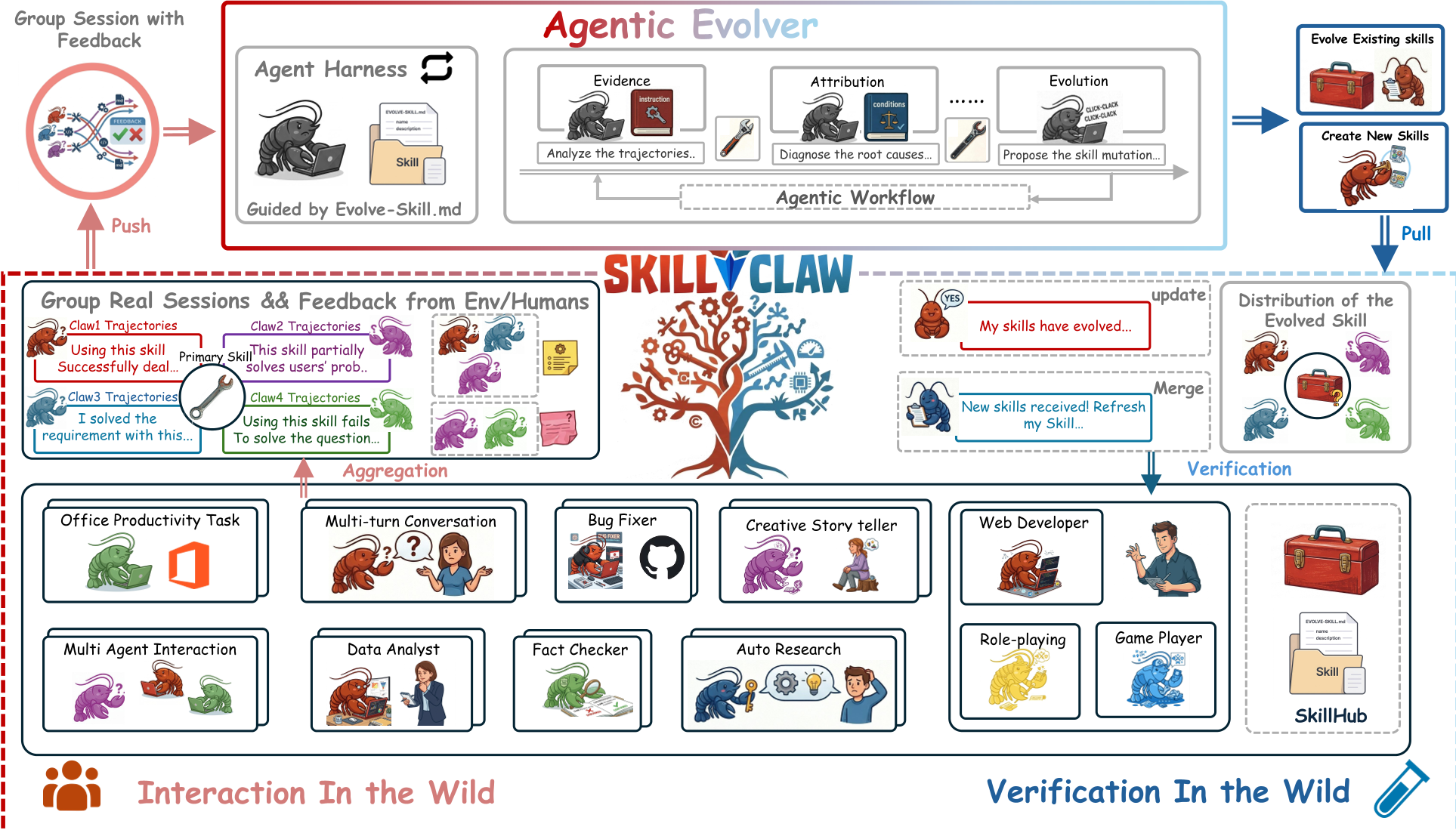
演化器面对的是一组调用同一技能的 sessions 。它会分析:
- Refine:如果多数失败指向同一个步骤,重写该流程。
- Create:如果用户频繁触发某种现有技能没覆盖的模式,创建新技能。
- Skip:信号不足时保持沉默,防止过拟合。
2.3 保守编辑与夜间验证
为了防止“越改越差”,SkillClaw 引入了 Monotonic Deployment(单调部署)。所有新技能必须在隔离的 Linux 容器中通过 WildClawBench 的回测,只有胜过旧版本的技能才会被合并到 Master 分支并同步给所有用户。
3. 实验战绩:能力的“阶跃式”增长
研究团队在 WildClawBench(包含 productivity, safety, coding 等 6 个领域)上测试了 Qwen3-Max 模型的进化过程。
3.1 核心结果对比
实验展示了 6 天(6 个迭代周期)的进化曲线:

- 创意合成(Creative Synthesis):第 1 天到第 2 天出现了阶跃式提升(11.57% -> 21.80%)。分析发现,进化器纠正了 Agent 对
/tmp工作空间和多模态文件路径的误解。 - 搜索检索(Search & Retrieval):表现出阶段性改进(22.73% -> 34.55%)。系统首先解决了输入校验问题,随后进化出了“约束感知检索规划”的高级策略。
3.2 深度案例:从“无序尝试”到“结构化流程”
在 Slack 消息分析任务中(Figure 2),原始技能只是一条简单的指令。进化后的技能变成了一个 4 阶段 SOP:
- 预览扫描(识别候选);
- 选择性提取(节省上下文);
- 内容对齐(确保准确);
- 异常感知(预判 API 端口错误并热修复)。
这种从“描述性指令”到“算法化流程”的跃迁,是性能提升的根本原因。
4. 资深主编洞察:Agent 进化的未来
SkillClaw 的价值在于它提出了一个低成本、去中心化的自适应方案。
- Inductive Bias 的显性化:通过修改 Markdown 技能而非微调权重,人类可以随时审计 Agent 学到了什么“歪门邪道”,保证了安全可控。
- 长尾问题的终结者:对于复杂的 API 环境,只有真实用户的撞墙尝试才能穷举出边界情况。SkillClaw 证明了“用户即标注员”的可行性。
- 局限性:目前的演化依赖于高水平的 Teacher Model(如 Qwen3-Max)。如果 Teacher 模型本身对底层错误存在认知偏差,演化可能会陷入局部最优。
总结 (Takeaway): SkillClaw 展示了 Agent 生态系统的未来趋势:不再有孤立的 Agent,只有不断进化的集体大脑。对于开发者而言,这预示着未来的 Agent 开发重心将从“编写完美的 Prompt”转向“设计高效的演化机制”。
注:本文基于 arXiv 论文《SkillClaw: Let Skills Evolve Collectively with Agentic Evolver》重构。