本文提出了 SOMA,这是一个战略编排与增强记忆系统,旨在提升视觉-语言-动作(VLA)模型在分布外(OOD)任务中的鲁棒性。SOMA 通过 contrastive Dual-Memory RAG、LLM 编排器及 MCP 预干预机制,在无需微调参数的情况下,使 π0 和 SmolVLA 等模型在 LIBERO 任务上的成功率平均提升了 56.6%。
TL;DR
视觉-语言-动作(VLA)模型虽然开启了通用机器人协作的新纪元,但它们在面对从未见过的杂乱环境或模糊指令时仍显得异常脆弱。SOMA (Strategic Orchestration and Memory-Augmented System) 提出了一种不改变模型参数的“外挂”方案:通过双重记忆检索(成功+失败案例)和动态工具编排(如视觉重绘、噪声消除),SOMA 让冻结的 VLA 模型在 OOD 任务中成功率翻倍,特别是在复杂长程任务中表现惊人。
1. 痛点:为什么 SLA 模型总是“一学就会,一做就废”?
目前的 VLA 模型(如 OpenVLA、π0)大多是**无状态(Stateless)**控制器。它们将当前视觉和指令直接映射为动作,缺陷显而易见:
- 缺乏历史感:如果不小心滑了一下导致物体移位,模型往往陷入僵局。
- 注意力漂移:环境中的一个小干扰物(Distractor)就可能让模型找错目标。
- 因果缺失:模型不知道自己为什么失败,只会机械地重复错误动作。
2. 核心直觉:归因驱动的动态干预
SOMA 的作者认为,很多 OOD 失败并非因为模型底层控制(Motor Skills)不行,而是**感知对齐(Perceptual Alignment)**出了问题。既然模型本身不能改,那就改变模型“看到”的东西。
2.1 模型架构图
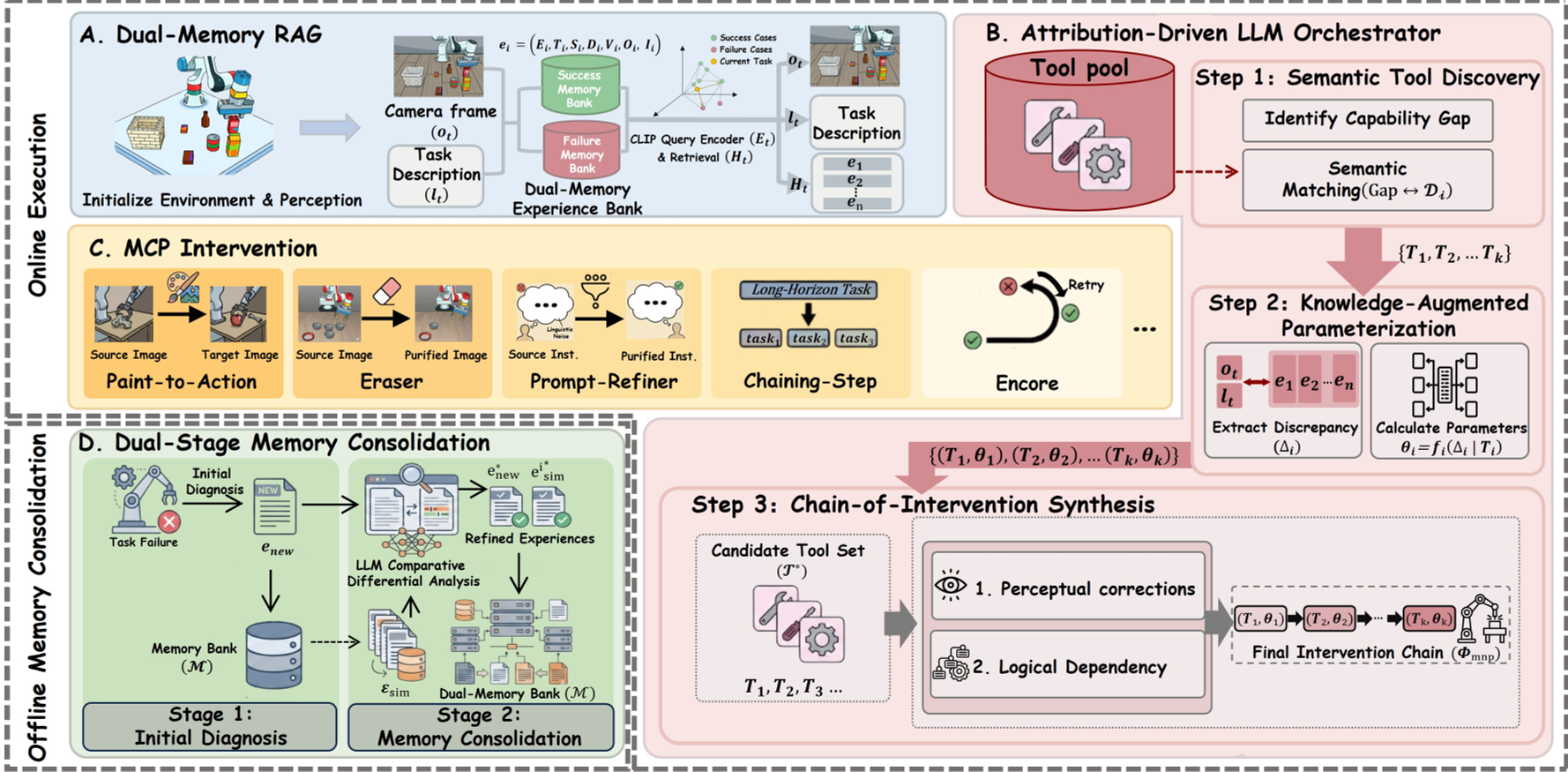
SOMA 的核心流程分为三个阶段:
- 双重记忆检索 (Dual-Memory RAG):不仅看别人怎么成功的(Success Bias),更看自己或他人怎么失败的。这种对比式检索能更精准地锁定当前问题的症结。
- LLM 编排器:利用像 Qwen3-VL 这样的强推理模型,分析检索到的经验,诊断出是“视觉漂移”还是“语义模糊”。
- MCP 工具链干预:
- Paint-to-Action:如果颜色变了识别不出,就给物体“涂”上模型熟悉的纹理。
- Eraser:用修图算法抹消掉背景里的干扰物。
- Encore:动作僵死时,执行回滚和重试。
3. 实验见证:化腐朽为神奇
在 LIBERO-SOMA 这一极具挑战性的基准上,SOMA 的介入让原本束手无策的基准模型发生了质变。
3.1 核心实验结果对比
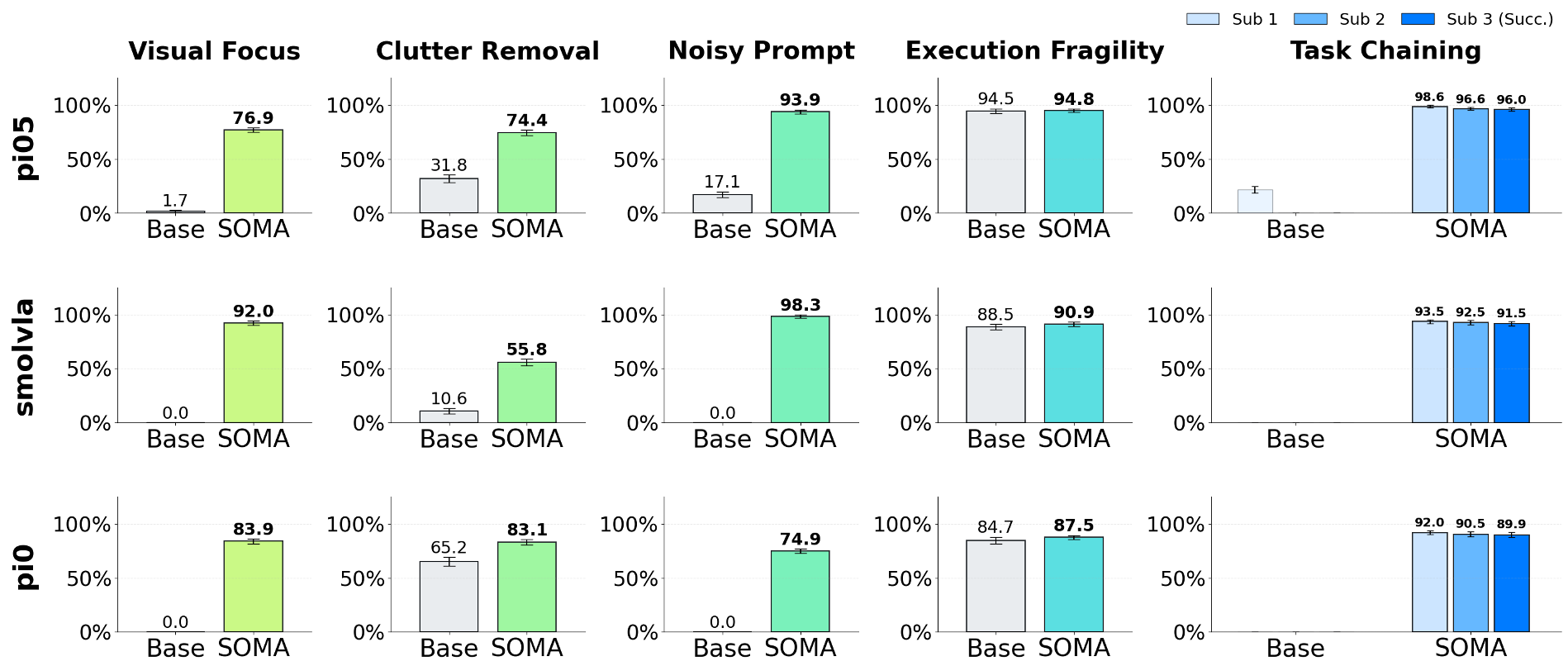
在长程任务链 (Task Chaining) 中,随着步数增加,普通模型因误差累积(Compounding Error)往往很快崩盘(图中蓝色虚线)。而 SOMA(紫色实线)通过 MCP 工具的实时纠偏,几乎保持了恒定的高成功率,最终提升幅度高达 89.1%。
3.2 消融实验:为什么失败记忆很重要?
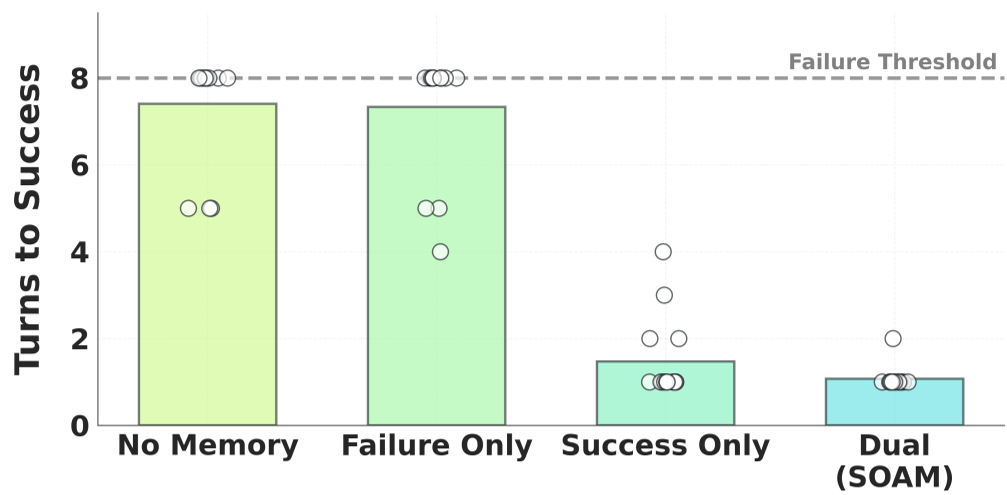
作者发现,如果只提供“成功经验”,LLM 的推理往往带有随机性;只有引入了“失败记忆”,系统才能形成闭环的因果推断(Reasoning Turns 显著下降),让干预动作更加“一针见血”。
4. 深度洞察:具身智能的新范式?
SOMA 的价值在于它验证了一个重要趋势:大模型不必亲自执行底层动作。
- 解耦思维:将高层的策略规划(Strategic Orchestration)与底层的原子动作执行解耦。
- 插拔式推理:这种无需微调(Parameter-free)的方式非常适合快速变化的工业环境。
- 自我进化:通过离线记忆整合(Memory Consolidation),系统能够从每一次失败中“自省”,从而实现越用越强的良性循环。
总结
SOMA 不仅仅是一个补丁工具箱,它代表了迈向通用机器人(Generalist Robots)的一条务实路径:通过给静态的 VLA 模型安上“大脑缓存”和“逻辑滤镜”,让它们在混乱的真实世界中也能表现出如实验室般的稳健。
注:文中使用的关键工具包含 SAM3 语义分割、OpenCV Inpainting 及 Qwen 系列大模型。