This paper presents a token-level analysis of Reinforcement Learning with Verifiable Rewards (RLVR) in LLMs, revealing that RL fine-tuning induces highly sparse and targeted distributional shifts. By employing cross-sampling interventions, the authors demonstrate that a tiny fraction of critical tokens (typically <10%) is responsible for the majority of reasoning performance gains (e.g., AIME 2024 accuracy jumping from 8% to 44%).
In the rapidly evolving landscape of Reinforcement Learning with Verifiable Rewards (RLVR), models like DeepSeek-R1 and Qwen2.5-Math have shown that LLMs can "learn to think" by optimizing for correctness. But what is actually happening under the hood during this fine-tuning? Does the model undergo a global personality shift, or is it something more precise?
A new study by the Qwen Pilot Team at Alibaba Group provides a definitive answer: RLVR is a surgical process. It doesn't rewrite the model; it identifies and corrects a tiny, sparse set of "critical transitions" that determine the success of a reasoning chain.
TL;DR
- Sparsity is King: Over 80% (and up to 98% in some methods) of next-token distributions remain virtually unchanged after RL fine-tuning.
- The Steering Mechanism: Performance gains are concentrated in a small subset of tokens (often <10% of the sequence). If you "fix" these tokens in a base model, you recover nearly all RL-level performance.
- Refinement vs. Invention: RLVR rarely "invents" new tokens. Instead, it reorders and prioritizes existing tokens that were already plausible but underweighted by the base model.
1. The Anatomy of a Shift: Highly Targeted Sparsity
The authors used Jensen-Shannon (JS) Divergence to measure how much the next-token probability distribution changed at every position in a sequence. The results were startling: the vast majority of tokens showed zero change.
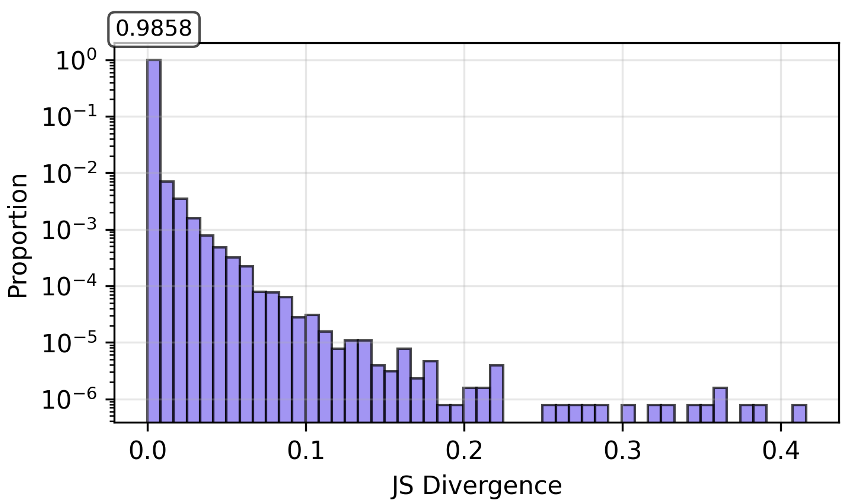
Figure: The percentile curve for DAPO shows that the vast majority of tokens undergo negligible distributional change.
Interestingly, these shifts are not random. They cluster at the beginning of the response (high-level strategy) and the end (formatting/termination). This suggests RLVR is primarily teaching the model how to start the "reasoning engine" and how to conclude it.
2. Functional Importance: The Cross-Sampling "Smoking Gun"
To prove that these sparse changes are what actually drive performance, the team performed a brilliant set of intervention experiments called Cross-Sampling.
Forward Cross-Sampling (Base + RL "Steering")
What happens if we take a "dumb" base model and only let it use the RL model's brain for the 5% of tokens where they disagree most?
- Result: The performance gap vanishes. On AIME 2024, injecting a small fraction of RL-sampled tokens into base generations recovered the RL model's 44% accuracy.
Reverse Cross-Sampling (RL - RL "Steering")
What happens if we take a "smart" RL model and force it to use the base model's choices at those same critical positions?
- Result: Immediate collapse. Replacing just ~5% of critical tokens with base choices erased all the gains, dropping accuracy back to ~8%.
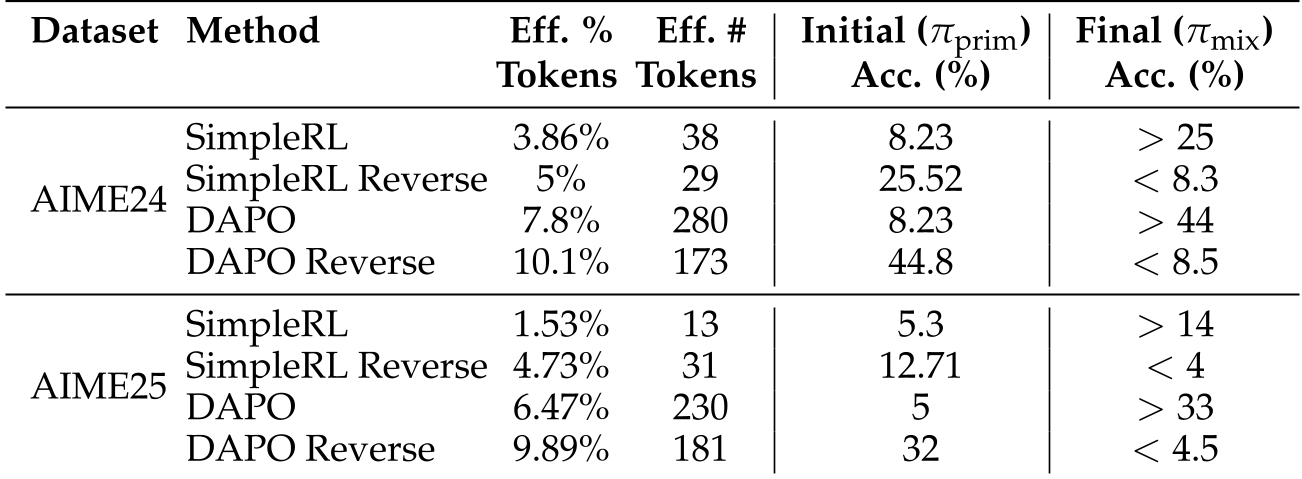 Table: Summary showing that modified token counts as low as 13–38 tokens can pivot the entire success of a sequence.
Table: Summary showing that modified token counts as low as 13–38 tokens can pivot the entire success of a sequence.
3. Does RL "Invent" New Reasoning?
A common question is whether RLVR teaches the model entirely new concepts. By looking at Top-k Overlap and Rank Reordering, the authors found that the RL model's favorite token was usually already in the base model's "Top 3" list.
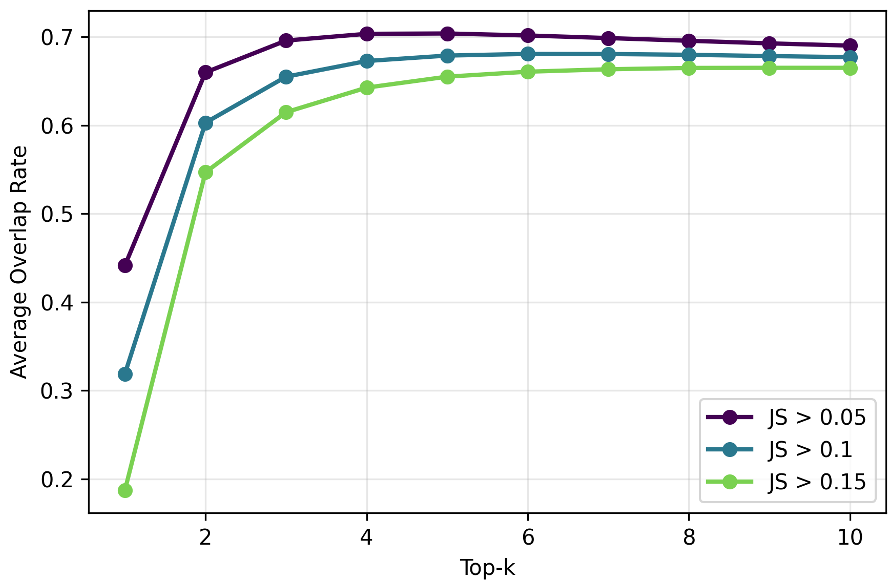 Figure: High overlap between base and RL models suggests mass reallocation within existing candidate sets.
Figure: High overlap between base and RL models suggests mass reallocation within existing candidate sets.
RLVR isn't teaching the model new words; it's teaching it to re-prioritize. It acts as a selection mechanism that amplifies subtle cues the base model already "knew" but didn't trust enough to output.
4. Why This Matters: Efficiency and Future Objectives
The discovery that performance is gated by a few tokens led the authors to experiment with Divergence-Weighted Advantages. By focusing the RL learning signal specifically on tokens that exhibit high KL-divergence, they were able to further boost performance beyond standard training recipes.
Key Takeaways for Practitioners:
- Stop the SFT Hammer: Unlike SFT, which changes the distribution of the whole sequence (often leading to catastrophic forgetting), RLVR is a "scalpel."
- Focus on the Deviants: The tokens where the model is most "unsure" (high entropy) or where the policy is shifting most rapidly are the keys to reasoning performance.
- Invariance Sensitivity: Reasoning chains are incredibly fragile. Even "semantically equivalent" token swaps can derail a logic chain if they shift the hidden state into a region the model hasn't mastered.
Conclusion
This paper demystifies the "magic" of models like DeepSeek-R1. It's not a global overhaul; it's a series of targeted, sparse refinements at critical decision points. By understanding RLVR as a targeted steering mechanism, we can design more efficient training objectives that focus our computational "firepower" exactly where it matters most: at the sparse, critical bottlenecks of thought.