本文提出了 SLQ(Statistically-Lossless Quantization),一种旨在实现“统计无损”的大语言模型量化框架。通过引入 Expected Acceptance Rate (EAR) 这一分布保真度度量指标,SLQ 在 Llama-3.3 和 Qwen 等模型上实现了低于 4-bit 的任务无损压缩,并提供了 1.7x-3.6x 的推理加速。
TL;DR
在 LLM 的部署实践中,我们常常在“压缩率”和“模型精度”之间做艰难的抉择。传统的量化方法如 GPTQ 虽然能压到 4-bit,但往往伴随着不可忽视的精度损失。本文提出的 SLQ (Statistically-Lossless Quantization) 另辟蹊径,定义了“统计无损”的标准。它能让模型在 3.3-4.7 bits 的极低位宽下,依然保持与原始模型几乎一致的任务表现,并带来最高 3.6 倍的加速。
核心洞察:为什么要追求“统计无损”?
作者观察到一个有趣的现象:即使是原始的 FP16 模型,在推荐的随机采样参数(如 Temperature=0.7)下,两次运行的结果也会有约 1% 的偏差。如果量化模型的输出波动位于这种“自然采样差异”之内,那么在实际应用中,它就是无损的。
基于此,论文提出了两个维度的无损定义:
- 任务无损 (Task-lossless, TL):在零样本(Zero-shot)基准测试中的准确率保持在采样方差范围内。
- 分布无损 (Distribution-lossless, DL):这是更严格的标准,要求量化后的 Token 输出概率分布与原模型几乎不可区分。作者引入了 EAR (Expected Acceptance Rate) 指标,EAR=0.99 意味着 99% 的情况下,量化模型生成的 Token 与原模型完全一致。
理论支柱: 方差定律
这是本文最具学术深度贡献的部分。作者从数学上证明了,对于非中心对称的权重分布,非对称量化 (Asymmetric Quantization) 是必须的。
他们提出了中心化效率(Centering Inefficiency)因子 。推导表明,对称量化的噪声方差比非对称量化高出 倍。即便 只有 1.2(轻微不对称),噪声也会增加 44%。这一结论直接解释了为什么以前的对称量化方法在追求极致保真度时会遇到瓶颈。
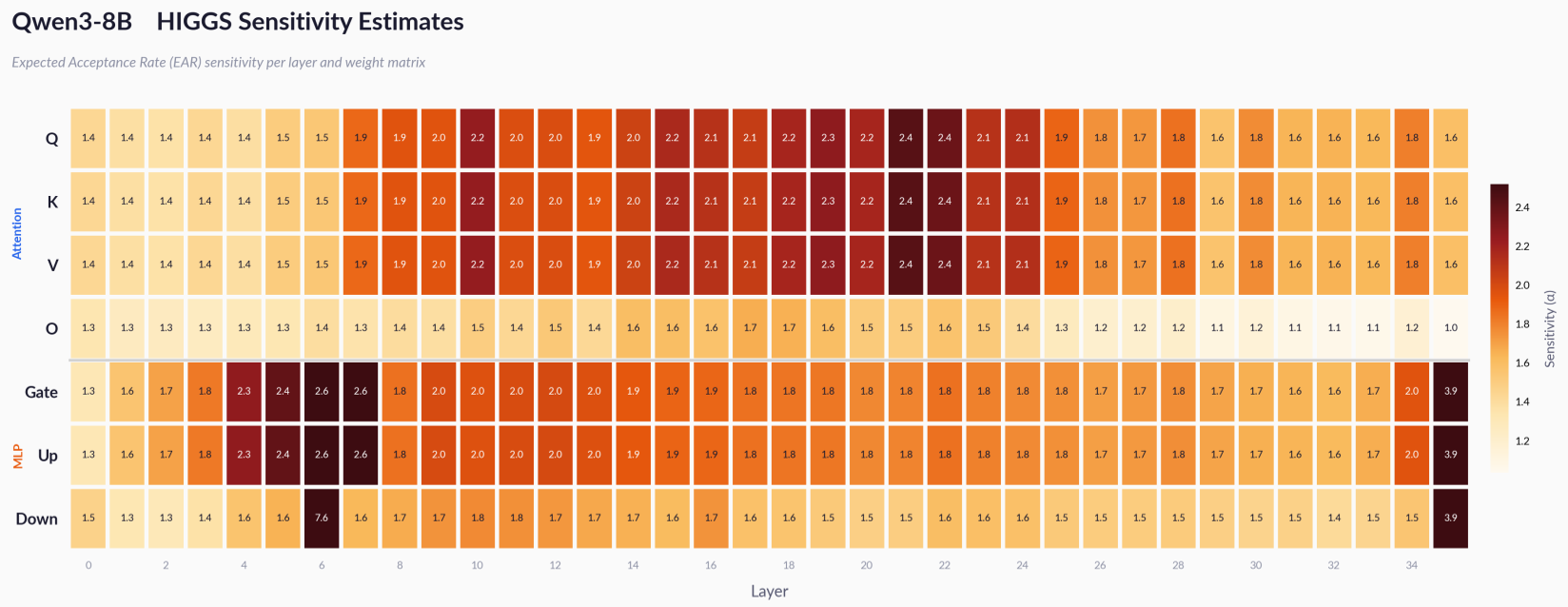 上图展示了 Qwen3-8B 每一层的灵敏度,可以看到 Attention 层的 K/V 投影对量化极其敏感。
上图展示了 Qwen3-8B 每一层的灵敏度,可以看到 Attention 层的 K/V 投影对量化极其敏感。
SLQ 方法论:如何精准分配比特?
SLQ 并不是简单地给所有层设置相同的位宽,而是采用了一套精密的自动分配流程:
- 多位宽 Shapley 估计:基于博弈论中的 Shapley Value,计算每一层在不同位宽(2, 3, 4, 5, 6, 7, 8-bit)下对整体模型性能的贡献度。
- 整数线性规划 (ILP):在给定的比特预算下,自动寻找最优的层级位宽组合。比如敏感的 K/V 层分配 7-8 bit,而不敏感的 MLP 层可能只用 3-4 bit。
- 单点校准策略:作者发现 KL 散度与任务恢复率之间存在近似线性关系。通过一次 FP16 运行和一次 4-bit 运行,即可推算出达到 99% 精度恢复所需的 KL 阈值,极大地缩短了搜索时间。
实验战果:超越 FP8 的效能
实验覆盖了 Llama-3.3 和 Qwen3 等顶级模型。关键结果如下:
- 极致压缩:Qwen3.5-27B 仅需 3.3 bits 即可达到任务无损。
- 分布对齐:在 5-6 bits 下,模型不仅能刷榜,连生成的语气、风格都与原版高度一致(EAR ≥ 0.99)。
- 推理加速:通过集成 Humming 高性能算子,SLQ 在 NVIDIA L40S GPU 上的吞吐量是 FP16 的 1.7 到 3.6 倍,显著优于 FP8 平态。
 表 2 显示,SLQ-DL 在多个模型上都实现了远超 BF16 和 FP8 的吞吐量(TPS/GPU)。
表 2 显示,SLQ-DL 在多个模型上都实现了远超 BF16 和 FP8 的吞吐量(TPS/GPU)。
深度诊断:思考 Token (Thinking Tokens) 的膨胀
对于像 Qwen-RL 这样带有推理过程(Thinking process)的模型,严重的量化损失会导致模型变得“啰嗦”。SLQ 的实验表明,DL 配置下的思考 Token 数量与 BF16 持平,而简单的 4-bit 量化会导致思考 Token 增加 2.9%。这证明了保持分布一致性能有效降低生成成本。
总结与局限
SLQ 证明了我们不需要 11-bit 或 16-bit 也能实现“无损”,关键在于非对称量化和非均匀位宽分配。
局限性:虽然权重压缩很完美,但目前工作仍集中在权重(Weight-only)量化。对于 KV Cache 的量化处理虽然在附录中有所提及,但在主实验中尚未完全展开,这可能是未来实现更大推理吞吐量(尤其是大 Batch 情况下)的突破口。
关键词: LLM Quantization, SLQ, EAR Metric, Mixed-precision, Inference Optimization.