本文提出了 StereoWorld,一种基于相机参数引导的立体视频世界模型。该模型通过统一的相机帧 RoPE 编码和立体感知注意力机制(Stereo-aware Attention),实现了端到端的双目视频生成,并在保持 SOTA 视觉质量的同时,显著提升了几何一致性和推理速度。
TL;DR
StereoWorld 是首个支持相机轨迹引导的端到端立体(Stereo)视频生成世界模型。它弃用了传统的“单目生成+深度估计+空洞填充”的繁琐流程,通过创新的 相机帧 RoPE 和 立体感知注意力 机制,在保持预训练视频模型强大生成能力的同时,直接输出具备底层几何一致性的双目视频。不仅推理速度提升 3 倍,更在 VR 渲染和具身智能场景中展现了卓越的几何推理能力。
痛点深挖:为什么单目世界模型不再够用?
当前主流的视频生成模型(如 Sora 等)在视觉美感上已臻化境,但在“物理常识”和“几何一致性”上仍存短板:
- 尺度歧义性 (Scale Ambiguity):单目图像无法提供真实的绝对度量,导致模型在长距离相机导航中经常出现物体大小比例扭曲。
- 累积误差:基于重投影的离线立体转换方法严重依赖深度预测器的精度,容易在细微结构(如围栏、文字)处产生严重伪影。
- 计算开销:如果粗暴地将双目视频拼接输入 Transformer,计算量会随序列长度成平方级爆炸。
 图 1:StereoWorld 与传统单目/RGBD 世界模型的对比,展示了其在几何接地和 VR 适配上的优势
图 1:StereoWorld 与传统单目/RGBD 世界模型的对比,展示了其在几何接地和 VR 适配上的优势
核心方法论:几何直觉与架构创新
1. 统一相机帧 RoPE (Unified Camera-Frame RoPE)
为了在视频扩散模型(DiT)中注入相机控制,作者没有采用传统的绝对坐标拼接(如 Plücker Ray),而是扩展了计算注意力时的 旋转位置编码 (RoPE)。
- 维度扩展:在预训练的 $d$ 维特征基础上,增加了一个专门的 $d_c$ 维度来承载相对相机参数。
- 权重初始化:实验证明,使用 Copy Init(复用时间注意力的权重)而非 Zero Init,能让模型在微调初期更快地捕获相机运动信号,同时不破坏预训练的视频生成质量。
2. 立体感知注意力 (Stereo-Aware Attention)
这是实现 3x 加速的关键。作者利用了立体视觉中的 极线约束 (Epipolar Prior):在校正后的立体对中,左右眼的对应点只会在同一水平行上震荡。
- 分解策略:将复杂的 4D 全全局注意力分解为两个低维操作:
- 3D Intra-view Attn:处理视图内的时空动态。
- Attn-Row:仅在相同时间步的左右视图 token 间进行水平行上的跨视点交互。 结果:计算复杂度从 $O((2F \cdot H \cdot W)^2)$ 骤降至接近单目模型水平。
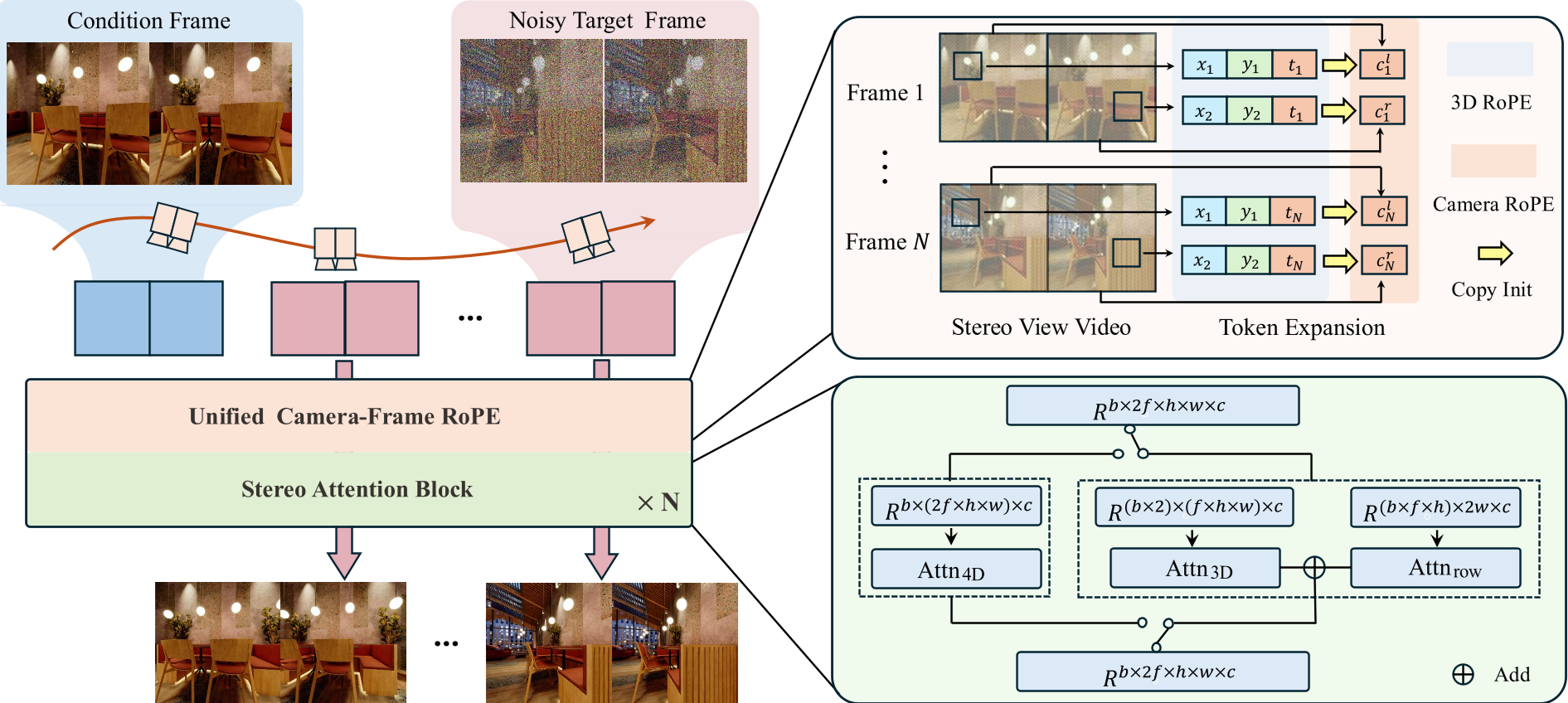 图 2:StereoWorld 整体架构图,重点展示了 RoPE 注入和注意力分解机制
图 2:StereoWorld 整体架构图,重点展示了 RoPE 注入和注意力分解机制
实验战绩:速度与精度的双重飞跃
在 TartanAir、Stereo4D 等多个数据集上的测试显示:
- 生成效率:在 H20 GPU 上,FPS 从基线方案的 0.1 左右提升至 0.49。通过长视频蒸馏技术,甚至能达到 5.6 FPS 的准实时水平。
- 几何精度:模型在未接受任何显式深度监督的情况下,生成的视差图(Disparity Map)比专门的 RGB-D 世界模型(如 Voyager, Aether)更干净、更符合场景逻辑。
 表 1:定量指标对比,StereoWorld 在相机精度和视点同步指标上全面领先
表 1:定量指标对比,StereoWorld 在相机精度和视点同步指标上全面领先
应用前景:VR 与具身智能
- VR 原生渲染:直接生成双目视频,用户佩戴头显即可获得完美的深度沉浸感,无需任何深度图处理逻辑。
- 具身智能规划:通过给定的动作指令(如“put the lid on the teapot”),模型能准确生成具备真实物理遮挡和尺度感的后续序列,为机器人的离线策略训练提供高质量仿真环境。
总结与局限
StereoWorld 标志着生成式视频模型从“像素搬运”向“几何感知”的进化。尽管它在静态场景和规则基线下的表现非常惊艳,但作者也坦言:动态立体数据稀缺 依然是制约模型泛化能力的瓶颈。未来,如何利用更大规模的单目视频数据来反哺立体生成,将是该领域最具潜力的方向。
Takeaway: 立体视觉是通往真实物理世界模型的必经之路,StereoWorld 通过将几何约束隐式嵌入注意力机制,提供了一条优雅且高效的路径。