本文提出了 StreamingClaw,一个面向具身智能和实时流式视频理解的统一 Agent 框架。该框架集成了实时流式推理、多模态分层长效记忆和主动交互机制,在 Llama 及 Qwen 等多模态基座上实现了感知识别-决策-动作的闭环。
TL;DR
理想汽车(MindGPT-ov 团队)发布的 StreamingClaw 是一项旨在解决具身智能(Embodied AI)“实时感知滞后”与“长时记忆丢失”的研究。它不再将视频视为离线的切片,而是作为连续的时空流进行处理。通过主从 Agent 架构、分层记忆演化以及主动交互机制,该框架打通了从视觉流输入到物理动作输出的完整回路。
背景定位:由于“慢”而导致的具身困境
在自动驾驶、具身机器人或智能座舱场景中,环境是高度动态且非平稳的。传统的视频模型往往采用“离线理解”模式,这对实时决策而言太慢了。此外,Agent 往往“转头就忘”,因为它们的上下文窗口(KV Cache)在长视频面前会迅速溢出,导致决策缺乏连贯性。
核心架构:主从 Agent 协作模式
StreamingClaw 摒弃了单体模型的单功能设计,转而采用一种更具扩展性的 Main-Sub-Agent 架构:
- StreamingReasoning (主 Agent):负责实时的流式推理和任务编排。
- StreamingMemory (从 Agent):负责多模态信息的存储、演化与检索。
- StreamingProactivity (从 Agent):负责预测未来事件并启动主动交互(如:主动提醒、预警)。
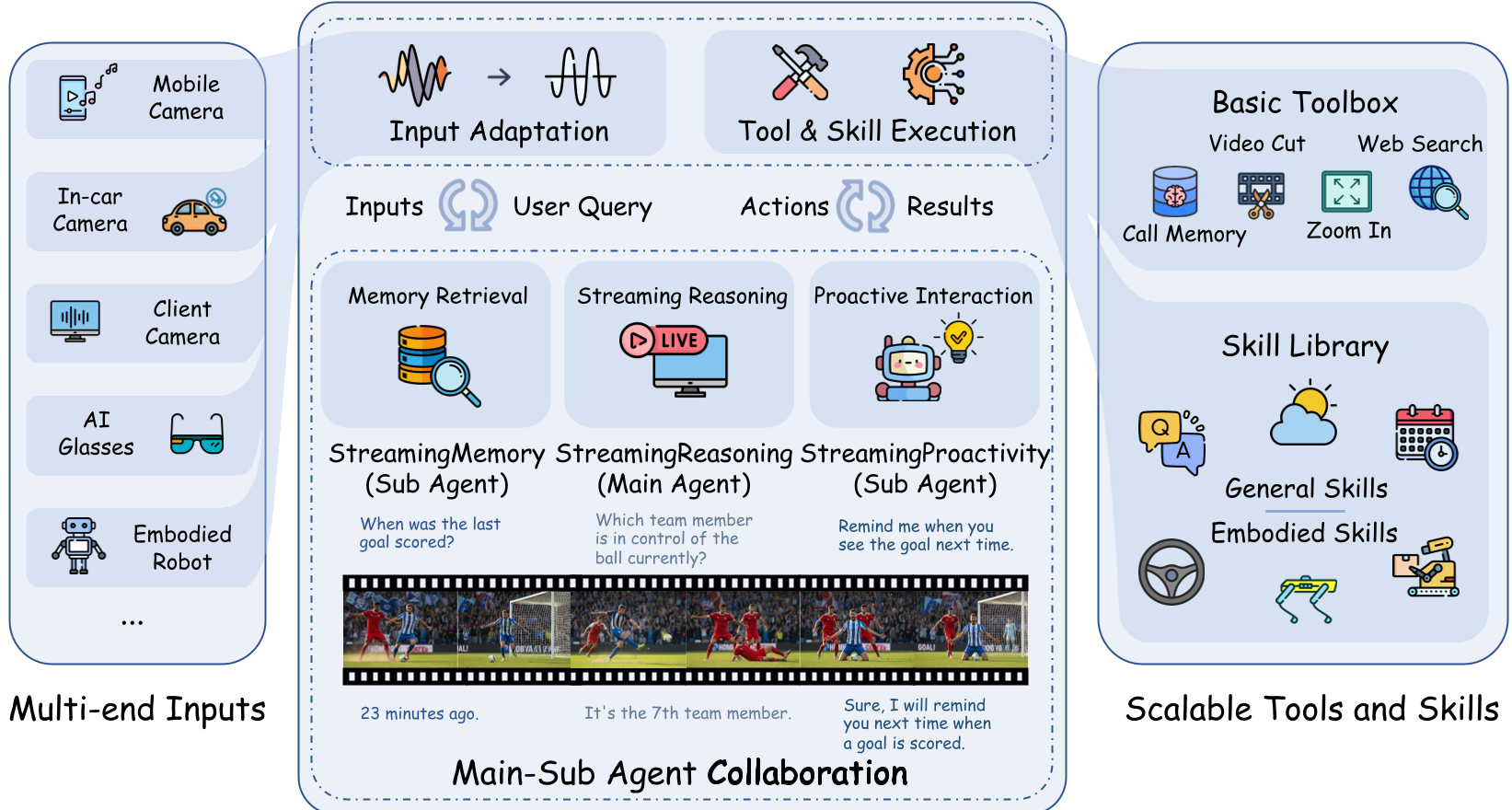 图 1:StreamingClaw 的整体 Pipeline,展示了从多端输入到 Agent 决策再到工具执行的闭环。
图 1:StreamingClaw 的整体 Pipeline,展示了从多端输入到 Agent 决策再到工具执行的闭环。
关键技术深挖:为什么它更高效?
1. 动态滑动窗口与 KV Cache 剪枝
为了在无限的视频流中保持低功耗运行,StreamingReasoning 引入了增量计算的概念。它只计算新到来视频块(Chunks)的 Token,并重用旧的 KV Cache。
- 重要性筛选:系统根据 Attention Score 只保留前 的高贡献视觉 Token,剔除冗余背景信息。
- 余弦相似度去重:如果新的一帧与缓存帧高度相似,则直接跳过更新,极大缓解了显存压力。
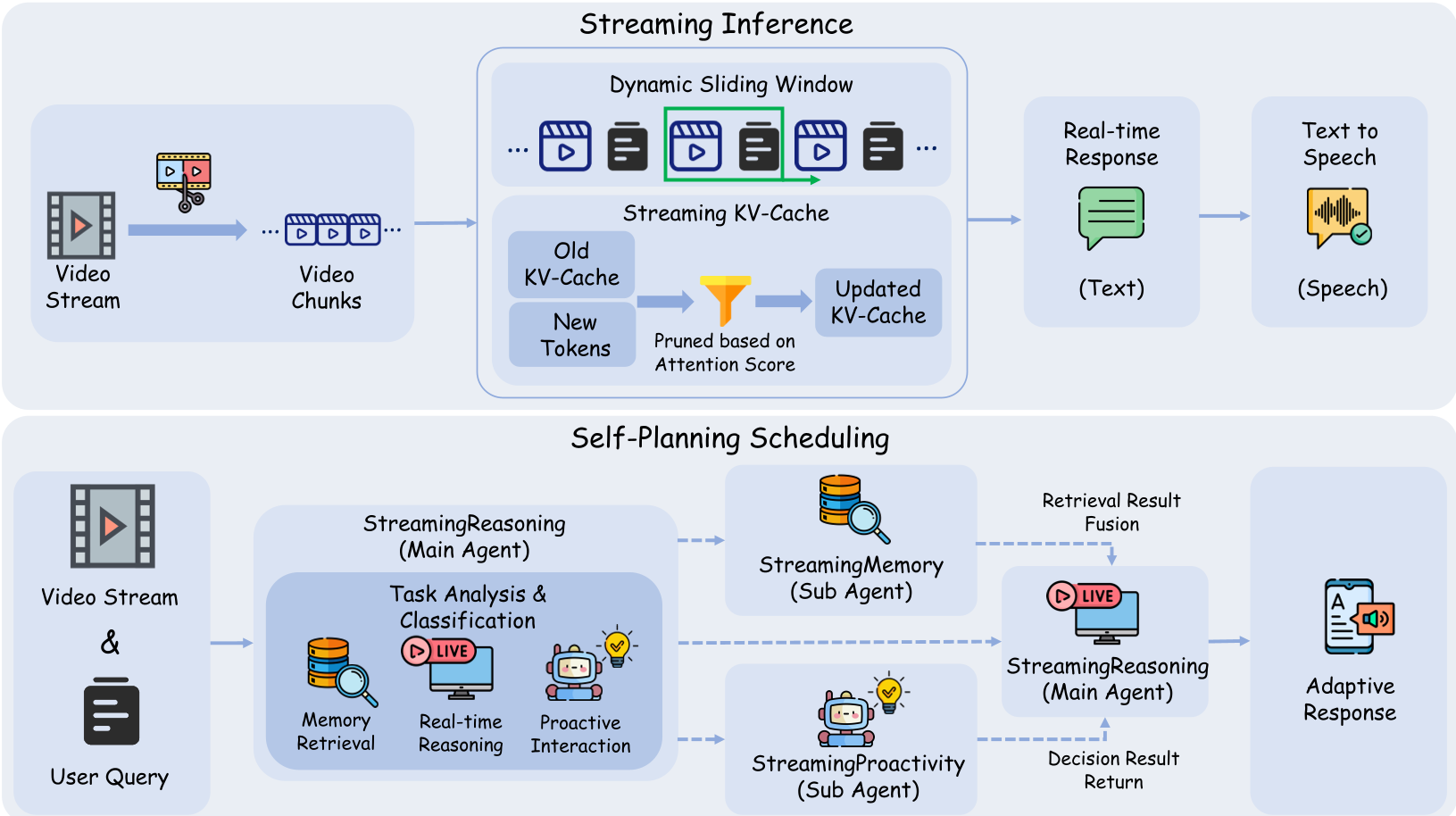 图 2:流式推理与自计划调度流程,展示了如何通过增量更新维持实时性。
图 2:流式推理与自计划调度流程,展示了如何通过增量更新维持实时性。
2. 像人一样“演化”记忆(HME)
传统的 RAG (检索增强生成) 往往只存文本摘要,容易丢失视觉细节。StreamingMemory 提出了 Hierarchical Memory Evolution (HME):
- 短时记忆:捕获原子动作(如:拿起杯子)。
- 长时记忆:将原子动作串联成更有语义的“事件”(如:在厨房准备咖啡)。 这种分层机制通过场景相似度进行合并,既压缩了数据,又保留了时空逻辑,让 Agent 能够回答“5分钟前发生了什么”这种跨时长的复杂问题。
主动交互:从“被动问答”到“前瞻预警”
这是 StreamingClaw 的一大亮点。StreamingProactivity 允许 Agent 在没有用户指令的情况下,基于视觉诱因主动介入。
- 时间感知交互:例如:“5分钟后提醒我下车”。
- 事件触发交互:例如:监测到驾驶员闭眼超过阈值,主动发出疲劳预警。
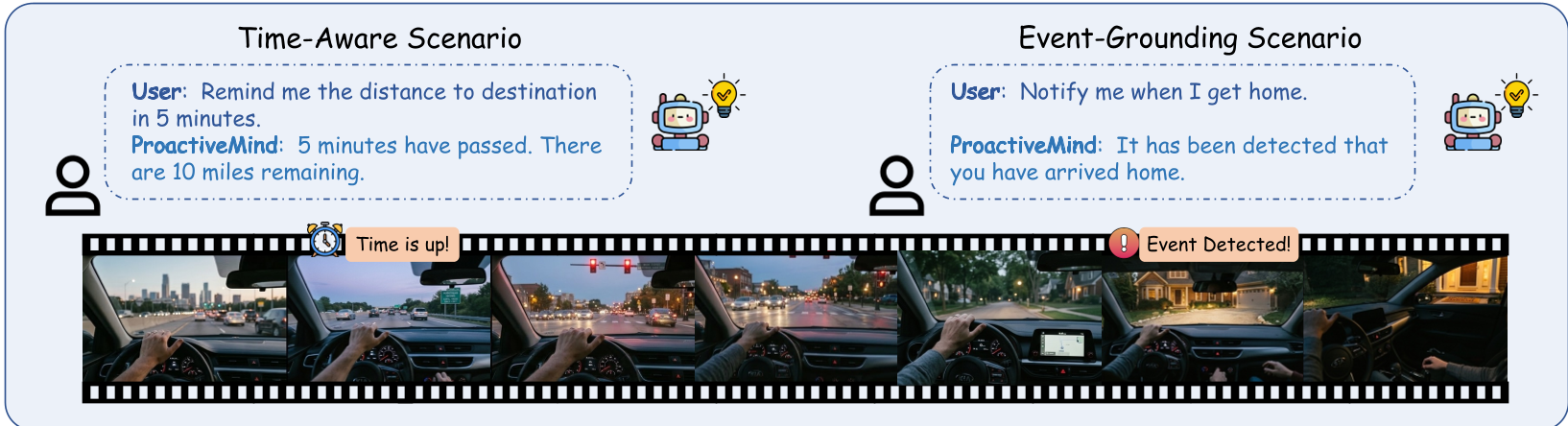 图 3:时间感知与事件驱动的主动交互场景示例。
图 3:时间感知与事件驱动的主动交互场景示例。
落地应用:具身闭环的最后一公里
StreamingClaw 预置了丰富的 Tools (工具) 和 Skills (技能)。
- Video Cut 工具:当主 Agent 发现某处细节模糊时,会调用此工具对局部视频进行精细化重采样和大型模型(如 Qwen-397B)深度分析。
- Embodied Skills:针对不同硬件定制了技能,如家庭看护机器人监测到老人摔倒会自动拨打急救电话并生成现场描述(Listing 2)。
总结与局限
StreamingClaw 成功地将多模态大模型从“离线静态智力”推向了“在线动态交互”。其分层记忆和主动交互的设计理念,对智能驾驶和家用机器人的落地具有极高的参考价值。
局限性:目前该框架主要聚焦于“视觉+文本”输入,语音主要作为输出手段。未来,迈向**全双工(Full-duplex)**的全模态(Omnimodal)实时闭环将是该团队的下一个进化方向。