本文提出了 TIGON,这是一个针对文本-图像双重条件 3D 生成任务的极简基线模型。通过结合特定模态的 DiT 骨干网络与轻量级跨模态融合机制,TIGON 在 Toys4K 等基准测试上显著超越了单模态 SOTA 方法。
TL;DR
在 3D 内容生成(AIGC 3D)领域,我们长期面临一个权衡:看图生成(Image-to-3D) 虽然纹理好但“背面”容易崩坏;文生 3D(Text-to-3D) 语义准但细节往往像“马赛克”。来自上海交大、华为和华中的研究团队提出了 TIGON,通过双支路流匹配(Rectified Flow)架构,首次系统性地实现了文本与图像的深度协同生成,让 3D 资产既有“视觉上的忠实度”,又有“语义上的合理性”。
1. 痛点:单模态的“视盲”与“脑补”
目前的 3D 生成网络(如 TRELLIS 或 UniLat3D)大多是单模态驱动的。研究者发现:
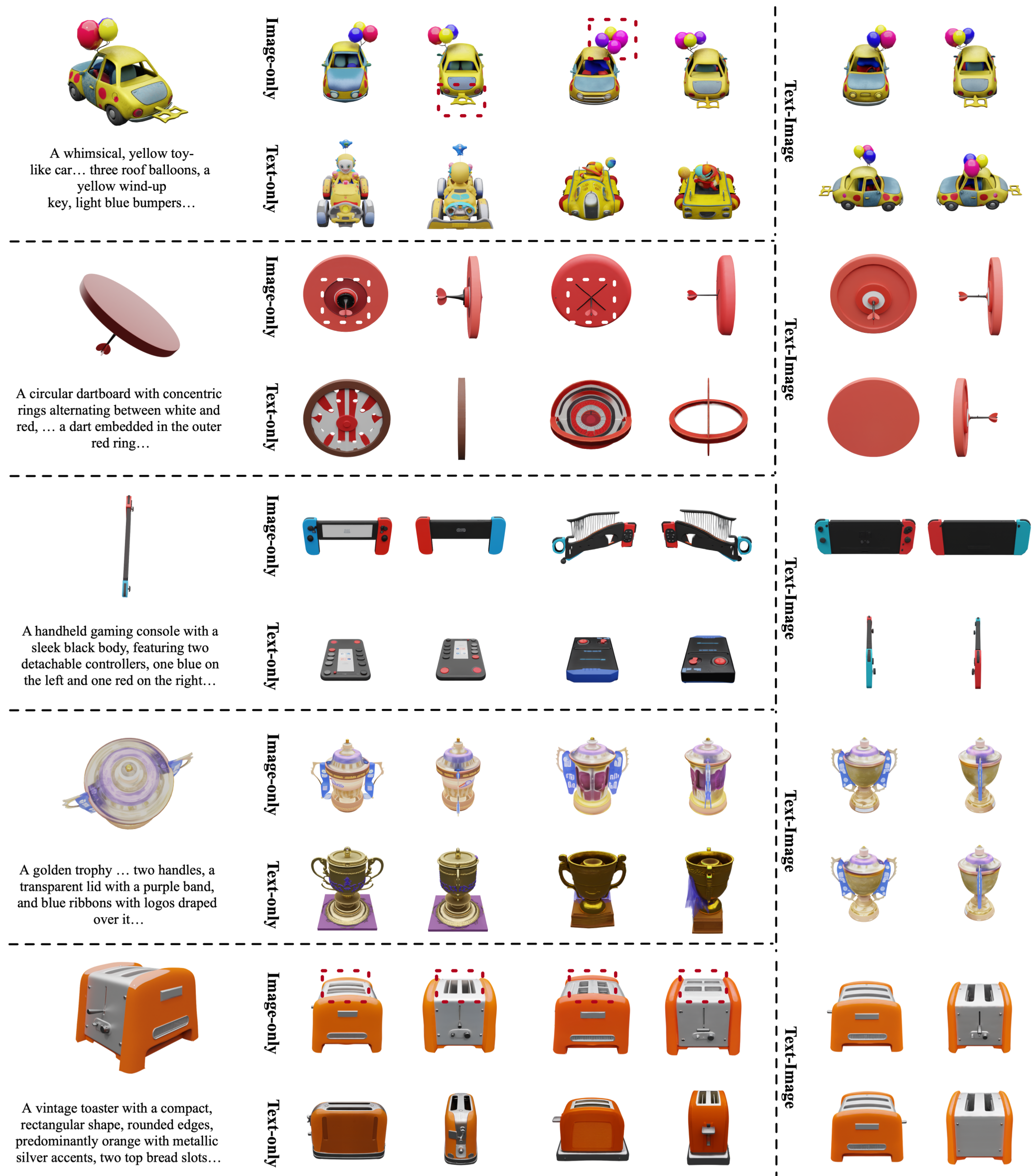
- 图像条件的脆弱性:当输入的参考图是仰视、俯视或存在严重遮挡时,模型必须在未观测区域进行大量的“幻觉(Hallucinate)”,导致生成的背面或侧面逻辑极其混乱(见图 1 中的杯托案例)。
- 文本条件的模糊性:仅凭文字,模型很难捕捉到具体的材质纹理和精确的几何比例。
核心直觉(Insight):图像提供像素级的“锚点”,而文本提供全局语义的“指导”。如果能让模型在生成过程中同时“看”和“听”,就能完美解决低信息视角下的 3D 重构难题。
2. TIGON 架构详解:极简即美
不同于强行将文本和图像特征拼接(Concatenate)的做法,TIGON 采用了逻辑严密的双支路 DiT 设计。
2.1 双支路骨干 (Dual-branch Backbone)
作者认为,图像 Token 是稠密且像素对齐的,而文本 Token 是稀疏且抽象的。将两者混在一个 Backbone 里会增加训练难度。因此,TIGON 保留了两个独立的 DiT 分支,分别处理对应的模态。
2.2 跨模态线性桥 (Early Fusion)
为了让两个分支步调一致,TIGON 在每个 DiT 块之间引入了跨模态线性桥(Linear Bridges)。
- 零初始化策略:借鉴了 ControlNet 的智慧,这些桥梁在训练初期是“关闭”的(权重为 0),确保预训练好的单模态能力不会被破坏。
- 协同去噪:随着训练进行,两个分支开始通过线性投影交换特征。
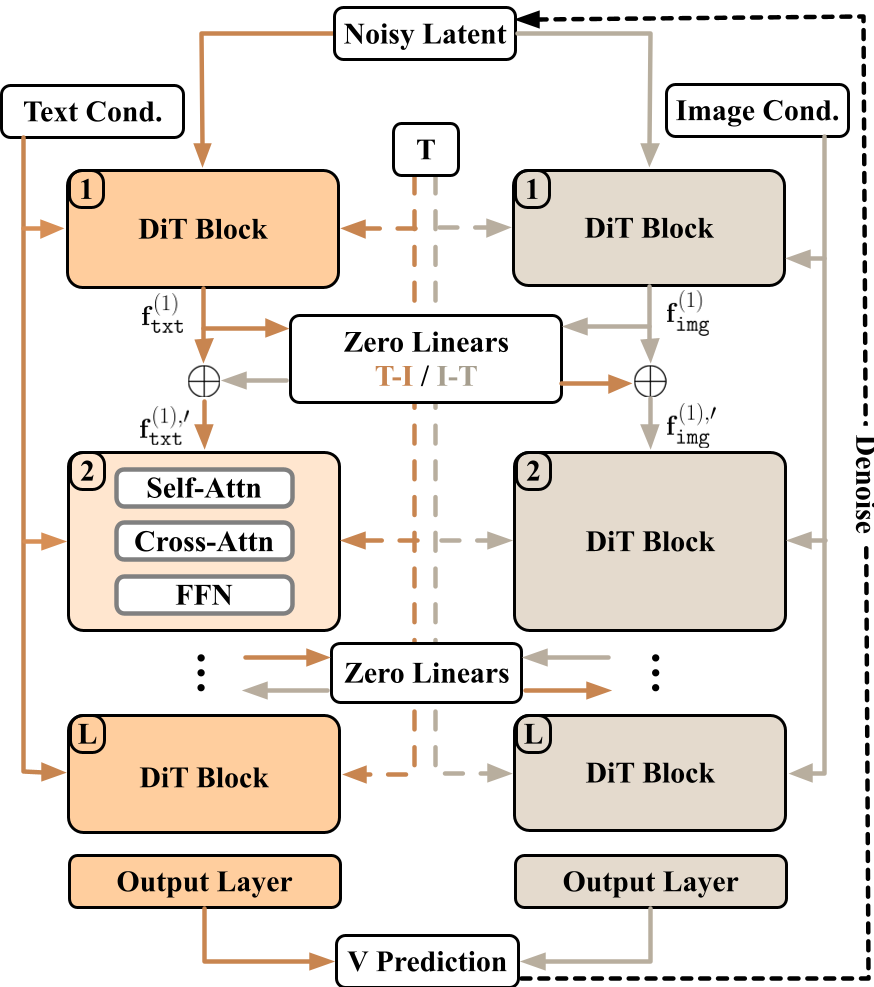
2.3 预测平均 (Late Fusion)
在推理阶段,TIGON 简单地将两个分支预测出的速度场(Velocity Field)进行加权平均。实验证明,得益于早期特征交换,这种简单的后期平均已经足够鲁棒,不需要复杂的注意力权重分配。
3. 实验战绩:低信息视角下的逆袭
在测试集 Toys4K 上,研究人员故意选择了信息量极低的视角(如物体的底部或极偏的角度)。
- 量化提升:在 UniLat3D 基础上,双模态介入后,反映视觉质量的 $FD_{DINOv2}$ 从 125.93 锐减至 61.59,提升效率近 50%。
- 可控性验证:如图 5 所示,通过固定图像、改变文本,用户可以精细控制资产的属性(例如把一个物体的底座纹理通过文字说明改为“大理石”或“复古色”)。
4. 深度洞察:为什么这种融合有效?
- Inductive Bias 的互补:图像分支负责捕捉 View-dependent 的局部特征,文本分支则像是一个全局正则项,约束几何形状不偏离常识。
- 训练稳定性:通过 Condition Dropout(25% 文本、25% 图像、25% 联合、25% 无条件),TIGON 变成了一个通用的 3D 生成引擎,不仅支持双模态,也能完美降级到任何单模态模式。
5. 局限性与展望
尽管 TIGON 表现优异,但在处理文本与图像极端冲突(例如图像是一个苹果,文字要求生成一辆车)时,模型依然倾向于倾向于图像信息,这反映了模型在模态竞争中的权重分配仍有优化空间。此外,目前的生成仍基于稀疏点云或高斯泼溅(3DGS),未来如何直接生成高密度的 CAD 级网格将是更具挑战的方向。
总结:TIGON 的成功标志着 3D 生成正从“尝试生成一张好看的图”转向“根据复杂的人类指令进行精确创作”。