Trace2Skill is a novel framework for the automated creation and optimization of Large Language Model (LLM) agent skills by distilling trajectory-local lessons into transferable, declarative artifacts. It utilizes a parallel multi-agent architecture to analyze execution experiences and hierarchically consolidates them into a single, conflict-free domain directory, achieving SOTA performance in spreadsheet manipulation and reasoning tasks.
TL;DR
Trace2Skill is a breakthrough framework that automates the "Human Expert" approach to skill authoring for LLM agents. By analyzing hundreds of execution trajectories in parallel and using hierarchical inductive reasoning to merge "patches," it creates highly transferable, declarative skills. It allows a 35B model to generate skills that boost a 122B model's performance by over 50%, requiring no parameter updates or external retrieval modules.
Why Current Agents "Forget" or "Overfit"
The industry currently faces a "Skill Gap." Human-written skills are high quality but don't scale. Conversely, automated "Online Learning" (updating skills one trajectory at a time) often leads to:
- Fragmentation: Creating thousands of tiny, specific rules that break retrieval systems.
- Sequential Bias: The model learns from Task A, changes its skill, and then misinterprets Task B because the underlying "textbook" changed mid-stream.
- Lack of Intuition: Most systems treat every error as a unique event rather than looking for the systemic reason why a specific tool (like
pandas) consistently fails in a specific environment.
Methodology: The "Many-to-One" Architecture
Trace2Skill replaces the reactive, sequential update loop with a Holistic Consolidation Pipeline.
1. Parallel Fleet of Analysts
Instead of one model thinking about one error, Trace2Skill dispatches a fleet of sub-agents.
- Success Analysts: Identify "Golden Paths."
- Error Analysts: Use an Agentic Loop (looking at files, testing fixes) to find the true root cause, preventing the hallucinated diagnoses common in single-pass LLM prompts.
2. Hierarchical Consolidation (Inductive Reasoning)
The core innovation is how these "patches" are merged. By merging patches in a tree-like hierarchy, the system performs Prevalence-Weighted Induction. If 50 independent agents all suggest a "Checklist for Formula Recalculation," the system promotes this to a "Global Standard Operating Procedure (SOP)."
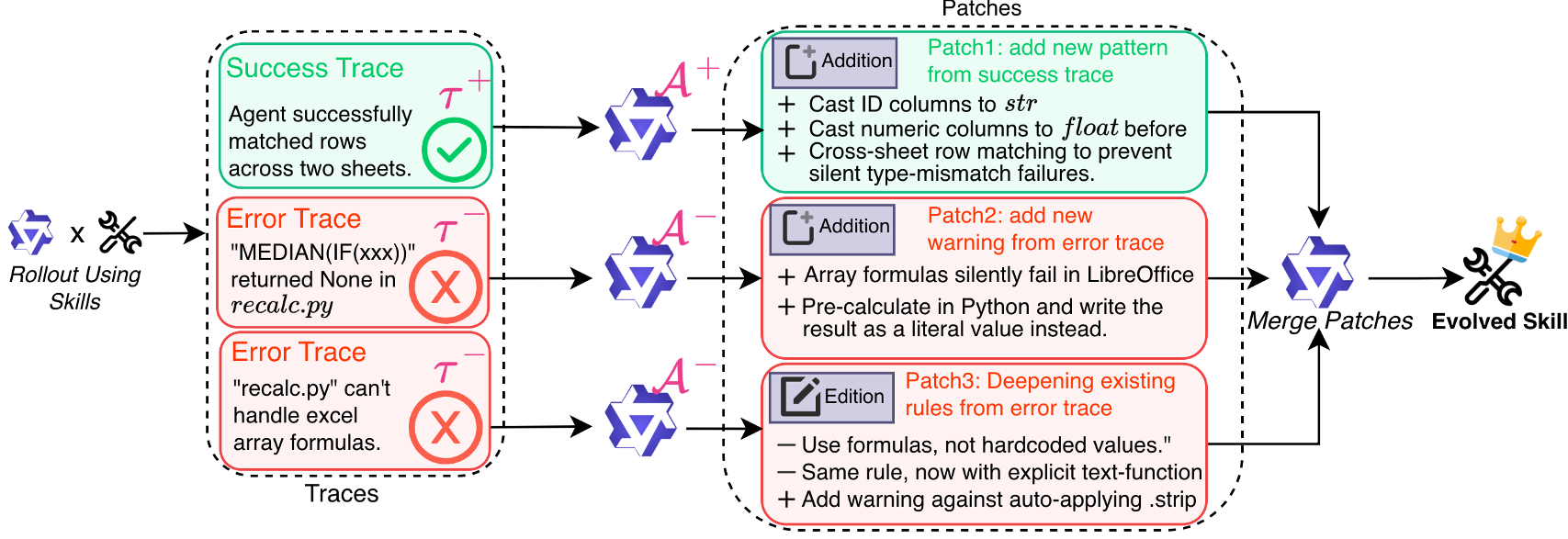 Figure 1: The Three-Stage Pipeline: Generation, Parallel Patching, and Hierarchical Consolidation.
Figure 1: The Three-Stage Pipeline: Generation, Parallel Patching, and Hierarchical Consolidation.
Experimental Evidence: Success Across Scales
The most striking result is Cross-Model Transferability. Traditionally, we assume a small model (35B) can't teach a large model (122B). Trace2Skill proves otherwise.
| Metric | 122B (No Skill) | 122B (w/ 35B-Authored Skill) | Delta | | :--- | :---: | :---: | :---: | | WikiTableQuestions (OOD) | 21.50% | 81.38% | +59.88% | | SpreadsheetBench (Vrf) | 27.67% | 65.00% | +37.33% |
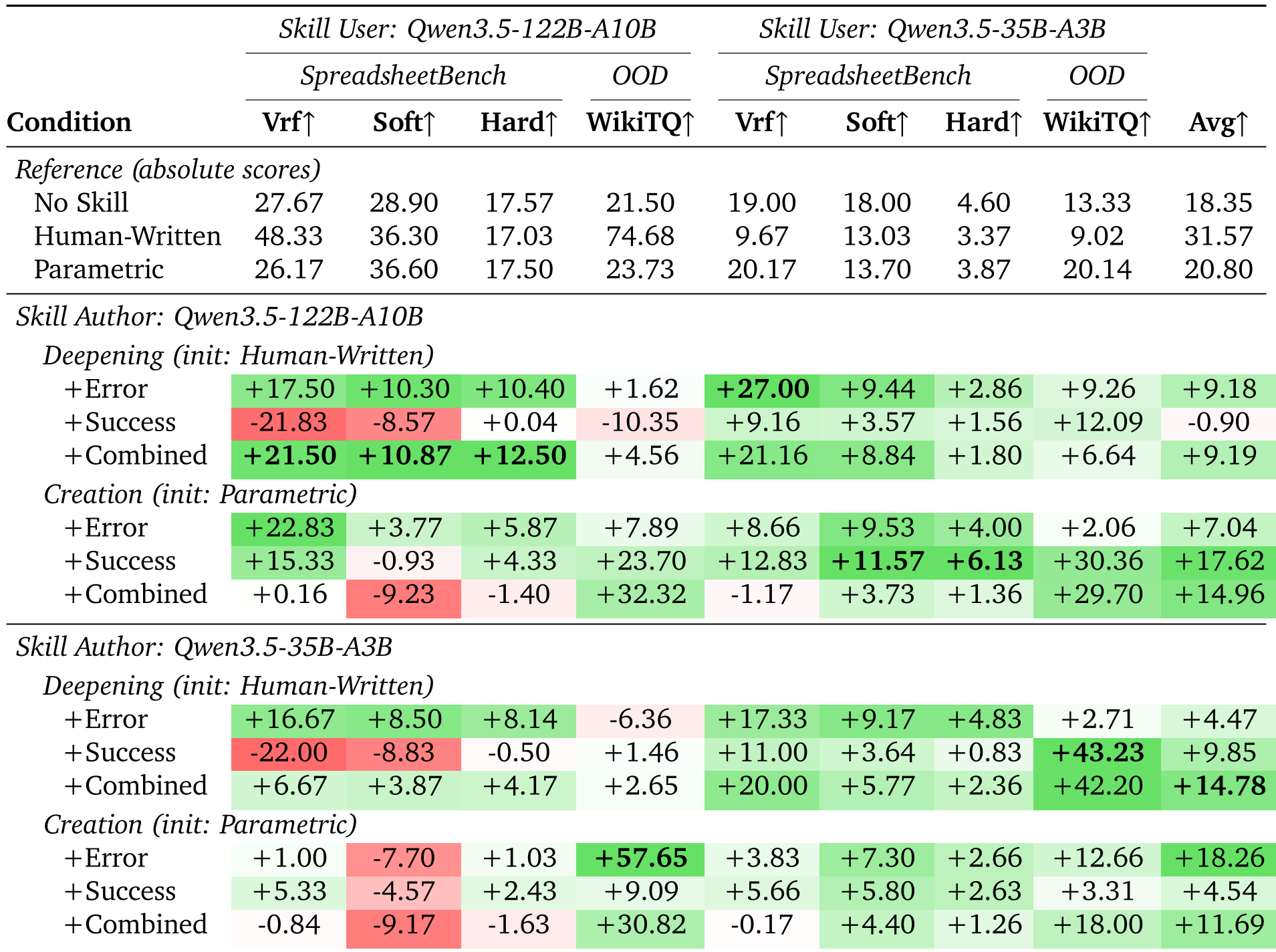 Table 1: Evolution results showing massive gains in OOD and Cross-Model scenarios.
Table 1: Evolution results showing massive gains in OOD and Cross-Model scenarios.
Key Insights from the Data:
- Agentic > Single Call: Using a loop for error analysis (allowing the analyst to "double-check" their fix) provided a massive +13.3% boost in helpulness.
- Parallel > Sequential: Parallel merging is not only 20x faster but also prevents "Parameter Drift," resulting in more stable and generalizable skills.
Real-World SOPs Discovered
The system didn't just find "tricks"; it distilled engineering best practices that even human experts sometimes overlook:
- Mandatory Recalculation: Always run
recalc.pyafter writing Excel formulas (prevents stale cells). - Tool Hierarchy: Prefer
openpyxloverpandasfor structural edits to avoid destroying cell formatting. - Bottom-Up Deletion: Delete rows in descending order to avoid index-shift corruption.
Conclusion: A New Paradigm for Agentic Memory
Trace2Skill shifts the focus from Retrieved Episodic Memory (storing thousands of old logs) to Distilled Procedural Knowledge (one clean, updated manual). This study proves that LLM experience can be "compressed" into declarative markdown that is architecture-agnostic, portable, and remarkably robust.
Future Directions: The authors suggest moving toward "Causal Attribution," where we can quantify exactly which trajectory-lesson led to the a 5% bump in accuracy.