本文提出了 2Xplat,一个用于 Pose-free 前向 3D Gaussian Splatting (3DGS) 的双专家框架。该方法通过将相机姿态估计(几何专家)与高保真高斯生成(外观专家)解耦,在无需已知相机参数的情况下,仅需 5K 次训练迭代即可达到 SOTA 性能。
TL;DR
传统的 Pose-free 前向 3DGS 方法往往将“算位置”和“画样子”和稀泥,导致渲染质量遇到瓶颈。本文提出的 2Xplat 采用了简单却极具冲击力的 “双专家 (Two-expert)” 架构:一个专家专门搞定几何位姿,另一个专家专攻外观渲染。结果是渲染质量大幅提升(PSNR +4dB),收敛速度快了近 30 倍。
背景定位:单体模型的局限
在 3D 视觉领域,从多张照片快速生成 3DGS 模型是当前热点。很多研究(如 YoNoSplat, NoPoSplat)追求 All-in-one 的极简设计,用一个 Backbone 同时预测相机在哪里(Pose)以及高斯点长什么样。
然而,作者指出这种纠缠 (Entanglement) 是有害的:
- 目标冲突:几何要求极高的物理一致性,而渲染有时需要一些“非几何”的属性来补偿透光、高频细节等复杂效果。
- 性能天花板:轻量级的单体模型难以集成高度专业的“位姿条件化”架构(如 Epipolar Transformer)。
- 训练效率低:从零开始让一个模型学会两项顶级技能非常耗时,且极易过拟合。
核心思路:让上帝的归上帝,凯撒的归凯撒
2Xplat 的核心逻辑是将任务拆解为两步流水线,但在训练上保持端到端优化。
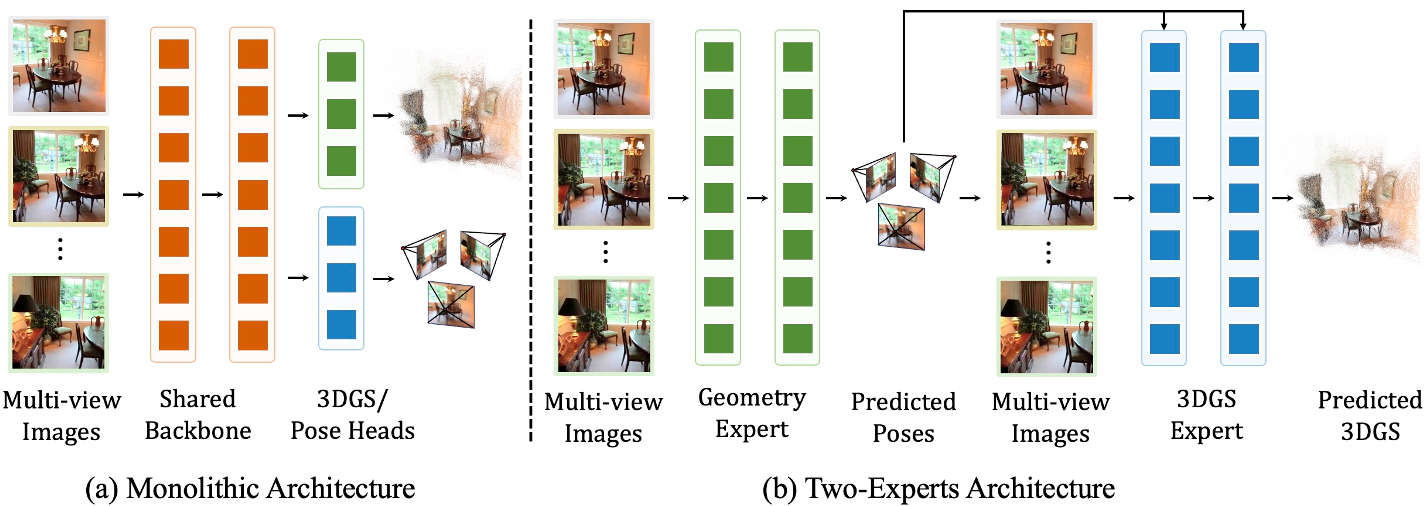
1. 几何专家 (Geometry Expert)
模型采用了例如 Depth Anything 3 (DA3) 这样的几何基座。它经过大规模 3D 数据预训练,能从无序图像中稳健地预测相机的内参和外参。
2. 外观专家 (Appearance Expert)
核心组件是 Multi-view Pyramid Transformer (MVP)。这个专家的精妙之处在于它不仅看图像特征,还显式地吃掉几何专家算出的 Pose。通过 PRoPE (Relative Positional Encoding),模型能把不同视角的特征对齐,极大地降低了模型自学空间的负担。
实验战绩:大力出奇迹
在 DL3DV 和 RE10K 等大规模数据集上,2Xplat 的表现几乎是统治级的。
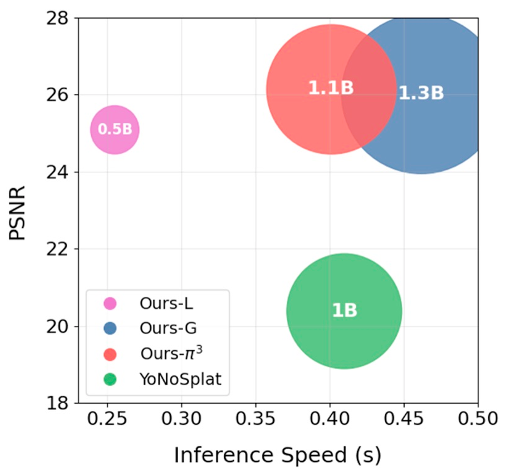
- 渲染质量:在 12 个输入视图的情况下,2Xplat 的 PSNR 达到了 27.24,而之前的 SOTA 只有 23.28。甚至在没有真值 Pose 的情况下,预测出的 Pose 渲染效果已经比肩那些给定真值 Pose 的方法。
- 视图可扩展性:传统方法随着输入图增加,误差会累积导致性能下降;而 2Xplat 的 PSNR 随视角数量(6->24->128)增加保持稳健上升。
- 效率:在 H200 上仅需 5K 次迭代即可收敛,相比 YoNoSplat 的 150K 次,计算成本降了一个数量级。
深度洞察:为什么有效?
- 解耦的 Inductive Bias:显式地将 Pose 作为中间接口,实际上是给模型注入了一个强大的先验——3D 点云的分布应受相机视点约束。
- 鲁棒性训练:虽然由第一个专家预测 Pose,但通过端到端的 Render Loss 反向传播,外观专家学会了如何“容忍”偏差的位姿,并在属性生成中进行补偿。
- 利用预训练分红:直接复用两个领域的顶级预训练权重,避免了从像素开始学习几何的痛苦过程。
总结与启示
2Xplat 告诉我们:在 3D 生成领域,Modular Design (模块化设计) 仍然具有极大的生命力。这种“解耦预测、端到端细化”的范式,可能比追求纯粹的单体网络更能适应复杂的现实场景。
局限性:目前 Pose 预测仍作为中间瓶颈,如果几何专家在极端视角下失效,外观专家也难以回天。未来的方向可能是引入更强的反馈机制,让外观渲染的质量反过来优化初始 Pose 估计。