本文提出了 BeTTER,一个用于诊断 Vision-Language-Action (VLA) 模型真实具身推理能力的基准测试平台。通过对 π0.5、GR00T-N1.6 等 SOTA 模型进行因果干预实验,揭示了当前模型在看似高分的背后,存在严重的语义塌陷和行为惯性。
TL;DR
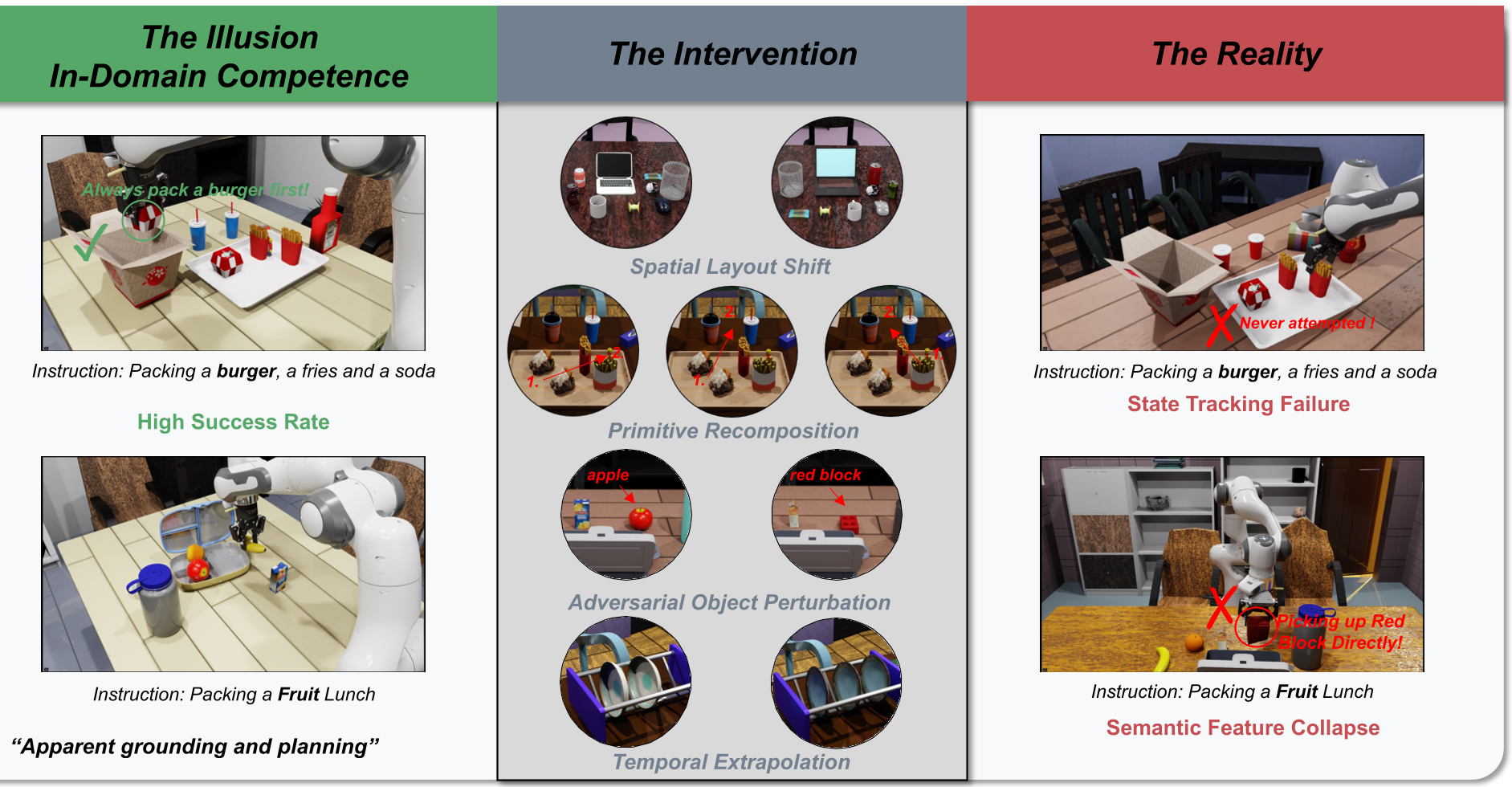
尽管当前的 Vision-Language-Action (VLA) 模型在标准机器人榜单上刷出了惊人的成功率,但本文作者通过全新的诊断基准 BeTTER 泼了一盆冷水:这些模型实际上并不理解指令,而是靠“背诵”训练集的视觉轨迹来作弊。一旦环境出现微小的逻辑偏移,模型就会陷入行为惯性,产生“隔空抓取”等荒唐行为。
背景定位:繁荣背后的“推理幻觉”
在机器人领域,π0, OpenVLA 等模型的出现让人们离通用物理智能更近了一步。然而,学术界开始反思:高基准分真的代表模型会“思考”吗?本文一针见血地指出,现有的评估协议奖励的是行为熟练度而非潜在推理能力。模型表现得像个专业工人的原因,可能仅仅是因为它记住了摄像头的角度和物体的坐标。
痛点深挖:为什么现有的 VLA 会“破功”?
作者发现,当前的 VLA 模型普遍利用了三种“捷径”:
- Lexical-Kinematic Shortcut:看到“红色”就直接映射到“向下移动”的动作,而不去验证红色物体在哪。
- Behavioral Inertia (行为惯性):如果训练集里都是先抓 A 再抓 B,当你要求先抓 B 时,它依然会习惯性地去抓 A。
- Semantic Feature Collapse:在复杂的办公桌清理任务中,模型分不清什么是“垃圾”(废纸巾)什么是“工具”(鼠标),表现出一种“盲目抓取”的回发性。
核心方法:BeTTER 诊断基准
为了拆穿这些幻觉,作者构建了 BeTTER。其核心逻辑在于:隔离执行能力,专注诊断推理。
- 模版化任务生成:利用 Gemini 等强 VLM 生成物理上合理的任务说明,并从 Objaverse 检索海量 3D 资产,确测试集的多样性。
- 因果干预:在测试时故意改变物体布局、重组任务动作顺序、加入视觉相似的干扰项。
- 特权状态记录:记录精确的 3D 边界框和分割掩码,生成真相(Ground Truth)VQA 问答对,直接剖析模型的视觉理解是否在线。
深度洞察:推理能力去哪儿了?
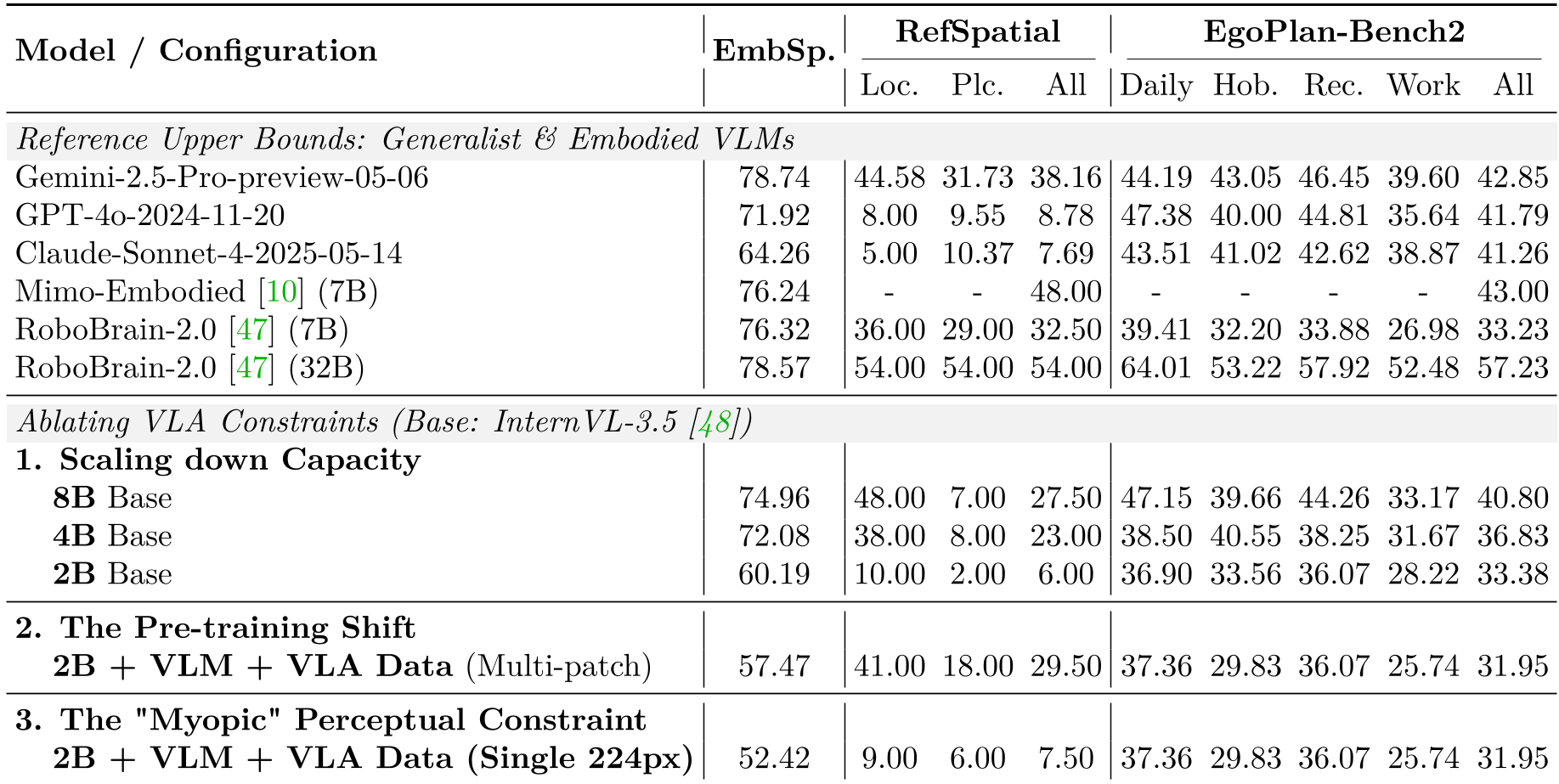
为什么强大的 VLM(如 InternVL)一变成 VLA 就不聪明了?作者通过消融实验给出了三个冷酷的结论:
- 容量压缩的代价:为了上机部署,模型从 8B 压到 2B,语义带宽严重受损。
- 协同训练的不对称:在动作数据 (VLA) 和语义数据 (VLM) 混合训练时,有限的参数空间被低频的动作控制 (za) 占据,挤走了高层的因果推理 (z)。
- “近视”的感知约束:VLM 习惯看高分辨率多切片图,而实时 VLA 常被限制在 224px 的单图输入,导致细粒度语义特征直接消失。
实验战绩:真实世界的残酷考验
在真机 SO101 平台上的测试验证了仿真的准确性。
- 行为惯性实验:在“把所有水果放进篮子”任务中,如果第一目标(柠檬)已在篮内,模型往往会“冻住”或者在空中乱挥,因为它无法将当前的视觉反馈与内部的记忆轨迹对齐。
- 失败模式:模型甚至会出现“相位冲突”,即视觉告诉它任务完成了,但它的关节状态还在 t=0 的初始位置,导致预测出零速度,机器人直接“宕机”。

总结与展望
本文精辟地指出:目前的 VLA 实际上是在用“推理能力”换取“控制频率”。 这种牺牲语义底座的建模方式在静态 Benchmark 上很受用,但在复杂的开放世界中极其危险。
作者呼吁,未来的具身架构必须解决高频控制与高层推理之间的结构性张力。也许,下一代的物理智能不应该是端到端的单体模型,而需要更精细的模块化解耦,或者更强大的特征保持机制,才能真正告别“推理幻觉”。