本文提出了 SAVER(Self-Audited Verified Reasoning)框架,旨在提升 LLM Agent 在复杂决策任务中的推理诚实度(Faithfulness)。该方法通过 persona 驱动的多样化信念生成、结构感知选择以及对抗式审计与微调修正,在 HotpotQA 等六大基准测试中显著降低了错误推理率,同时保持了 SOTA 级别的任务准确度度。
TL;DR
在 LLM Agent 系统中,我们往往只看结果(Action)是否正确,却忽略了支持结果的推理轨迹(Reasoning Trajectory)是否逻辑自洽且证据充足。本文提出的 SAVER (Self-Audited Verified Reasoning) 框架,通过引入“ Persona 采样 -> 对抗审计 -> 逻辑修复 -> 验证提交”的闭环流程,彻底解决了 Agent 在长程决策中因中间推理错误导致的“行为漂移”问题。
痛点深挖:共识不等于真相
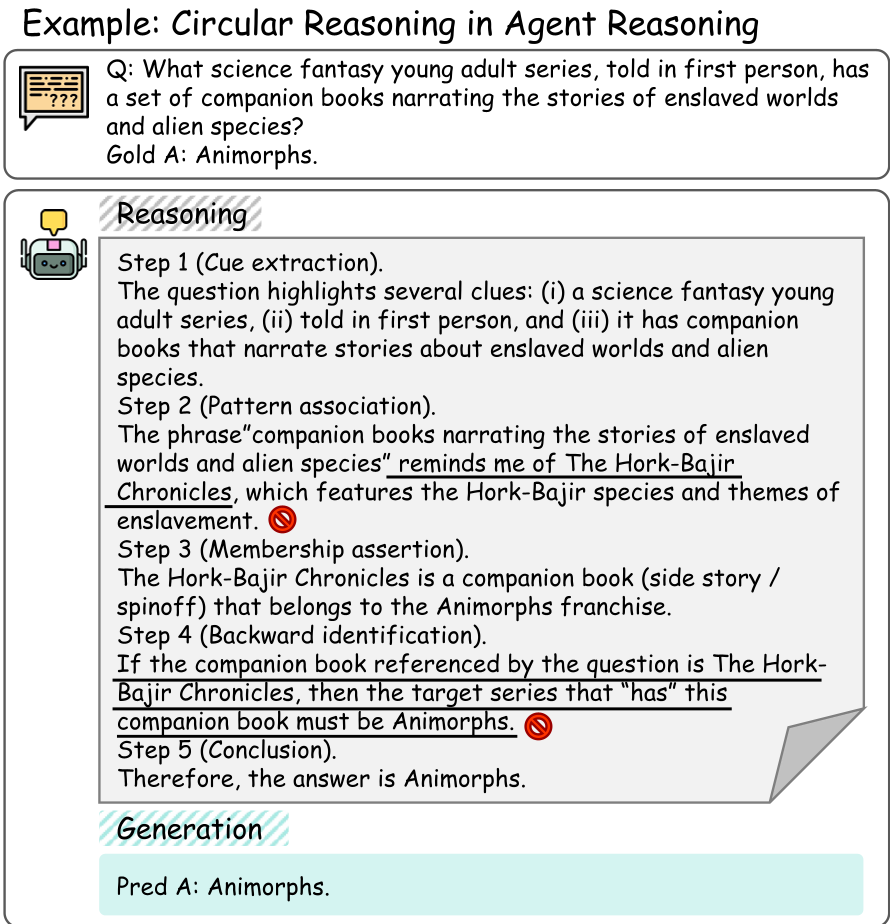
当前的 LLM Agent 普遍使用 Chain-of-Thought (CoT) 或多智能体辩论(Multi-agent Debate, MAD)来优化策略。然而,作者观察到一个致命缺陷:Agent 经常生成看起来很连贯、结果也正确,但推理过程完全是乱编的“伪逻辑”(如图 1 所示)。
更糟糕的是,现有的 Self-consistency 方法依赖“多数投票制”,如果多个候选回复都陷入了同一种常见的逻辑谬误(如循环论证),系统会因为“达成共识”而强化这一错误。这种不可信的信念一旦写入 Agent 的长期记忆,就会像雪球一样在后续决策中引发系统性偏差。
方法论详解:如何实现“逻辑硬约束”?
SAVER 的核心价值在于它不再把推理看成黑盒文字生成,而是将其建模为可审计的内部状态。
1. Persona-based 多样化采样
为了打破单一推理模板的束缚,SAVER 模拟了一个内部“合议庭”,让具有不同偏好的角色(如:证据优先型、假设驱动型)生成候选推理。通过 k-DPP (k-Determinantal Point Process) 采样,系统可以在结构特征空间中选出最具互补性的推理路径,从而更容易捕捉到隐藏的失效模式。
2. 对抗式推理审计 (Adversarial Auditing)
这是 SAVER 的灵魂模块。它并不直接重新回答问题,而是作为一个严厉的审查者,对每一行推理进行“压力测试”。它会识别以下 6 类违规:
- Missing_Assumption: 缺少必要前提。
- Unjustified_Inference: 无证据支撑的推断。
- Circular_Reasoning: 循环论证。
- ...以及矛盾和过度泛化等。
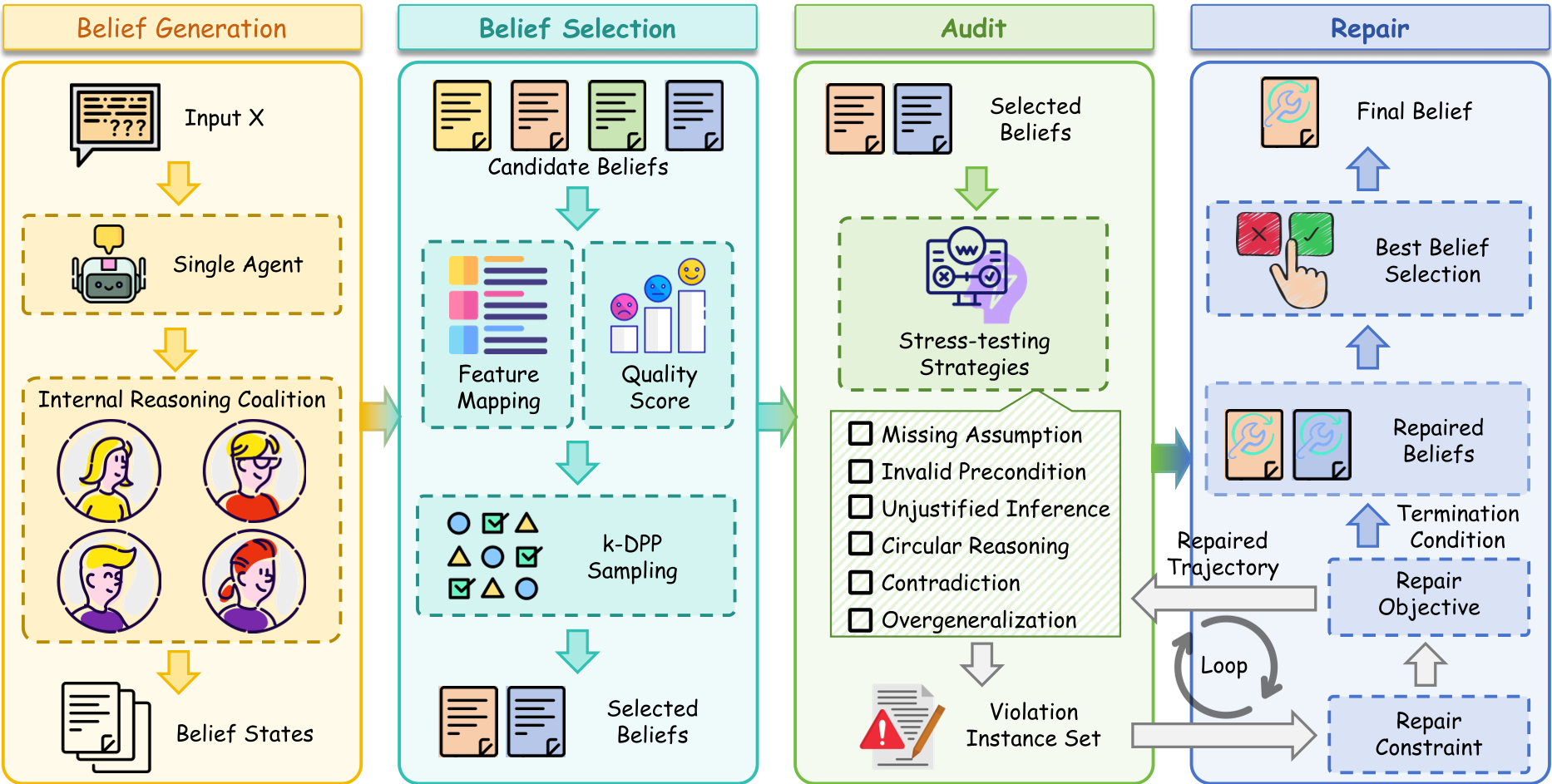
3. 约束引导的最小修复 (Minimal Counterfactual Repair)
不同于粗暴的“重写”,SAVER 遵循最小干预原则。它仅定位受损的逻辑片选(Slices)进行 counterfactual 修改,同时保持其他正确步骤的稳定。这种迭代直至 V(r) = ∅(即违规清零)的机制,确保了提交给环境或记忆的每一条信念都是经过验证的。
实验与结果:不仅更准,而且更“稳”
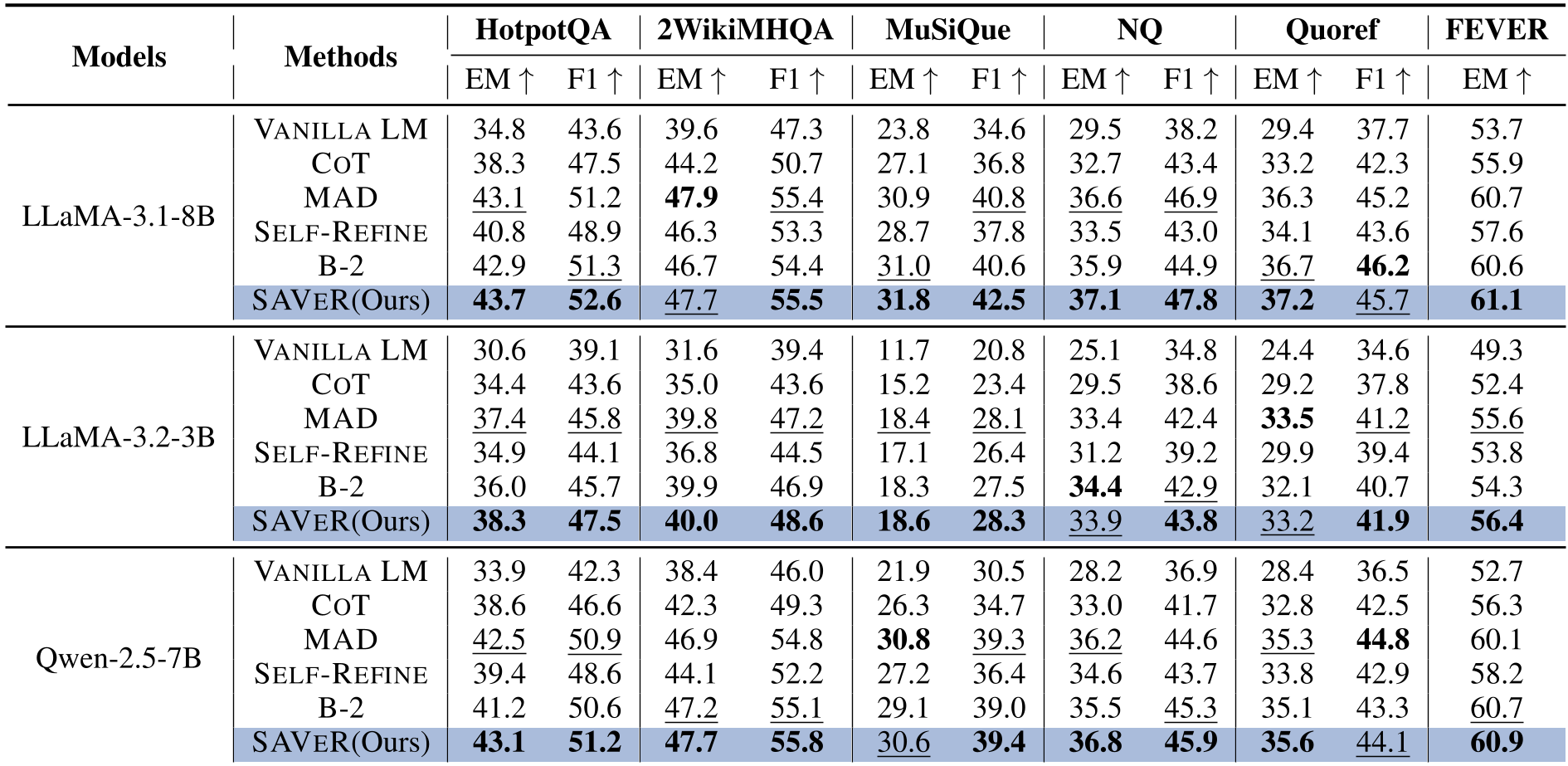
在 HotpotQA, 2WikiMHQA 等多跳推理任务上,SAVER 展示了强大的性能:
- 诚实度飙升:在 LLaMA-3.1-8B 上,SAVER 的未验证步骤率(USR)远低于 MAD 和 Self-Refine。
- 收敛极快:图 3 展示了审计-修复轨迹,SAVER 仅需极少次的迭代即可将违规率降至近乎为零,而传统的辩论式方法往往在多次互动后仍存在逻辑黑洞。
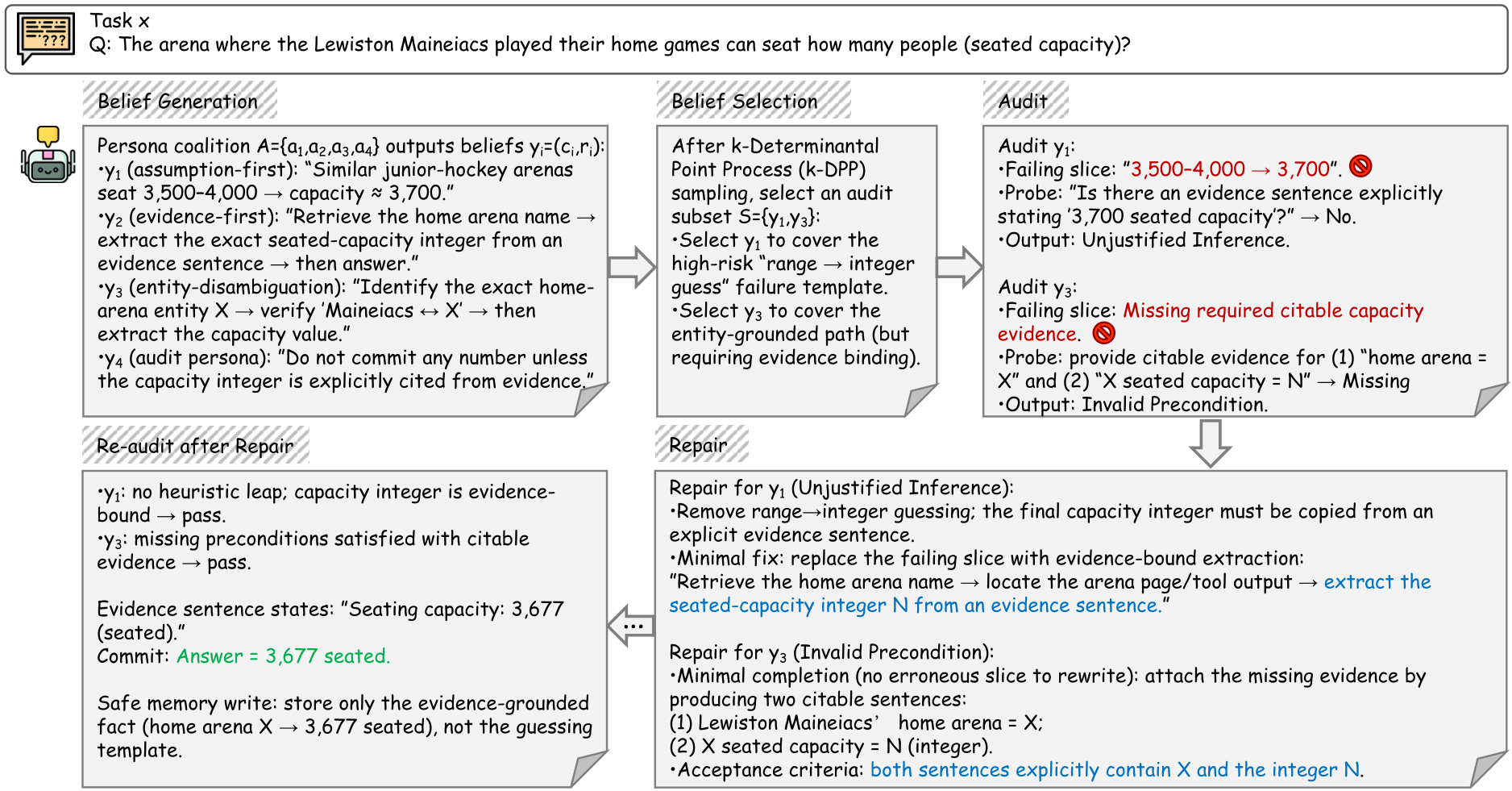
案例分析:从“瞎猜”到“证据闭环”
论文中给出的 Case(图 4)非常典型:Agent 最初在询问体育馆容量时,通过本体知识“瞎猜”了一个数字(3700),虽然接近正确答案,但没有任何引用支撑。在 SAVER 审计后,系统强制其回溯检索,定位到确切的文本句子,并最终将推理修复为基于证据的严格推导。
深度洞察与总结
SAVER 的价值不仅在于刷榜,它为构建可靠 Agent 提供了一个新的范式:Verify Before You Commit。
- 优点:它在内部逻辑层面建立了可防御性,特别适合 RAG 系统、科研助手或任何需要中间决策透明度的 Agent 场景。
- 局限性:额外的 A-R (Audit-Repair) 循环会增加推理延迟。对于极简单的任务(Single-hop),这种“大炮打蚊子”的做法可能会降低系统效率。
- 展望:未来的方向可能是根据问题的复杂程度或模型的不确定性,动态决定审计的深度。
总之,这篇工作提醒我们:通往通用人工智能(AGI)的路径,不应只是更大规模的概率拟合,更应是像人类专家一样,在行动前对自己的思想进行严格的逻辑审查。