本文提出了 VideoSeek,一种面向长视频理解的自主 Agent 框架。该方法通过“思考-行动-观察”的循环机制,利用视频逻辑流主动搜寻关键证据,在 LVBench 和 Video-MME 等长视频基准测试中刷新了 SOTA 记录。
TL;DR
传统的视频 AI 模型通常是个“耐心的观众”,试图看清每一帧;而 VideoSeek 则是个“聪明的侦探”。它不再暴力拆解每秒视频,而是利用 视频逻辑流 (Video Logic Flow),通过主动搜寻(Active Seeking)仅提取 5% 以内的关键帧,就在长视频理解任务上全面超越了密集采样的方法,性能提升高达 10% 以上,计算成本却下降了一个数量级。
背景定位:从“暴力解析”到“逻辑驱动”
在处理长达一小时的视频时,即便是目前最强的 Multimodal LLM(如 GPT-4o 或 Gemini 1.5 Pro)也面临两难:要么采样太稀疏丢掉细节,要么采样太密导致 Context Window 爆炸。
作者观察到一个有趣的物理直觉:人类在做视频问答时,绝不会从头看到尾。我们会先扫一眼进度条,根据剧情逻辑定位到相关片段,最后再放大细节。VideoSeek 的核心贡献就是将这种由逻辑驱动的搜寻行为流程化为一个可操作的 Agent 框架。
痛点深挖:预处理的“金钱陷阱”
目前的视频 Agent(如 DVD 或 DrVideo)通常需要将视频预先转化为数万字的文档或复杂的向量数据库。
- 效率极低:在 LVBench 等测试集中,80% 的问题只需要看不到 5% 的内容就能回答。
- 非自适应:预处理是静态的,无法根据具体 Question 动态调整关注点。
核心方法论:多粒度工具包与逻辑循环
VideoSeek 采用了经典的 ReAct (Think-Act-Observe) 闭环,但其核心竞争力在于精心设计的三个工具:
1. 架构拆解
- <overview> (全局概览):以极低频率采样,建立初步的剧情地图。
- <skim> (粗略跳读):当定位到某个几分钟的区间时,进行快速扫描,确定证据是否存在附近。
- <focus> (深度聚焦):一旦锁定秒级片段,开启高帧率(1 FPS)模式,捕捉如文字、微表情或特定动作等关键细节。
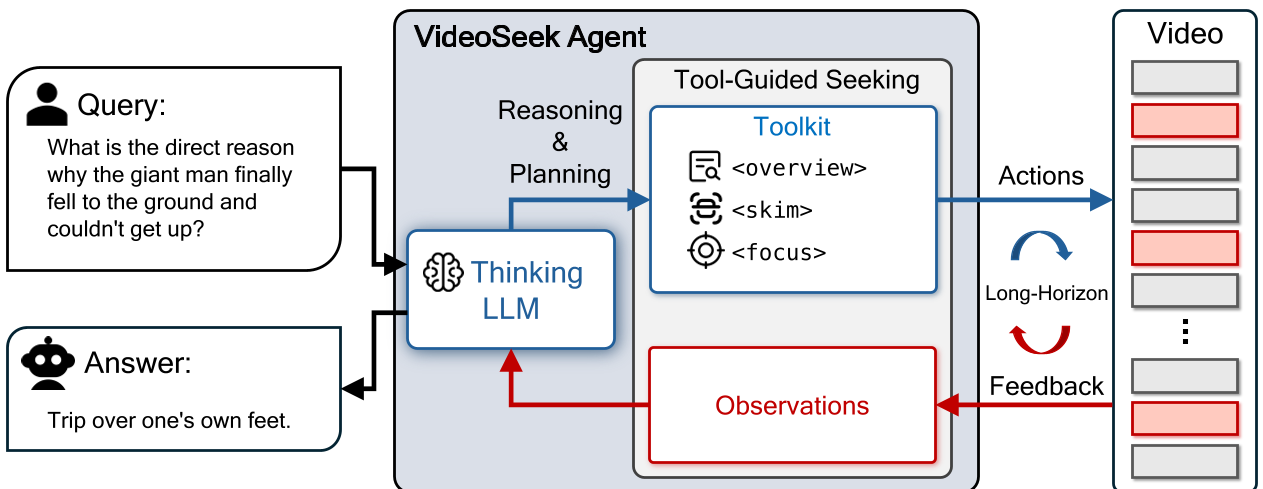 图 1: VideoSeek 的工作流程:思考-行动-观察。Agent 根据历史观察积累证据,逐步缩小搜索范围。
图 1: VideoSeek 的工作流程:思考-行动-观察。Agent 根据历史观察积累证据,逐步缩小搜索范围。
2. 逻辑流的力量
VideoSeek 不仅仅是搜索,它在推理。例如,如果问题询问“主角什么时候买的车”,Agent 会先看 <overview> 发现主角在开头很穷,结尾在开车,于是它会主动去视频中段搜寻“赚钱”或“4S店”的逻辑节点。
实验战绩:以少胜多的典范
VideoSeek 在四大长视频基准测试(LVBench, Video-MME, LongVideoBench, Video-Holmes)中均表现出色。
- LVBench 奇迹:在有字幕辅助下,VideoSeek 仅处理 27 帧 就在 LVBench 上跑出了 76.7% 的高分,而对比模型 GPT-5 处理 384 帧仅为 66.5%。
- 极端高效:如图 2 所示,VideoSeek 位于坐标系的左上角——用最少的帧数(约其他 Agent 的 1/300)实现了最高的准确率。
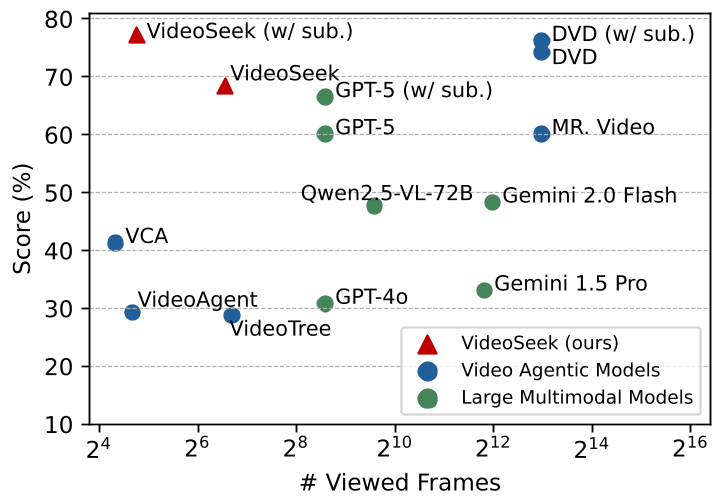 图 2: 准确率 vs 帧数对比。VideoSeek(三角形标注)在功耗比上实现了断层领先。
图 2: 准确率 vs 帧数对比。VideoSeek(三角形标注)在功耗比上实现了断层领先。
深度洞察:为什么推理能力比感知更重要?
论文的消融实验给出了一个扎心的结论:Agent 的“脑子”(LLM 本身的推理能力)比“眼睛”更重要。
- 当使用 GPT-4.1 替换 GPT-5 作为大脑时,即使给同样的帧,模型也会因为“过度自信”而过早停止搜寻,导致精度暴跌。
- 实验证明,强推理模型能意识到“目前的证据还不够”,从而驱动工具去挖掘更深层的视觉信息。
总结与未来展望
Takeaway: VideoSeek 的成功标志着长视频理解已从“感知竞赛”转向“推理竞赛”。
局限性:尽管逻辑搜寻非常强大,但它在处理突发性、无逻辑关联的视觉事件(如监控视频中的异常瞬间)时可能力有不逮,因为这些事件无法通过逻辑流预测。
未来,如何将这种主动搜寻机制扩展到多模态实时交互,甚至部署到端侧设备(低算力环境),将是该领域极具潜力的研究方向。