本文对多模态大模型(VLM)中的视觉编码器进行了系统性评估,挑战了 ViT 的主导地位,提出并验证了状态空间模型(SSM)架构(如 VMamba)作为视觉背骨(Backbone)的强大潜力。通过在控制变量环境下进行对比,SSM 在定位(Grounding)和视觉问答(VQA)任务中展现出比同等规模 ViT 更优的性能。
TL;DR
在视觉语言模型(VLM)领域,Transformer 架构及其变体 ViT 一直是视觉特征提取的不二之选。然而,来自石溪大学的研究团队通过一项严谨的受控实验发现:状态空间模型(SSM,如 VMamba)在多模态任务中表现甚至优于 ViT。特别是在物体定位(Grounding)能力上,SSM 后发先至,证明了即便不堆参数、不刷 ImageNet 榜单,优秀的架构设计依然能带来质的飞跃。
1. 深度迷思:ImageNet 高分等于 VLM 强吗?
长期以来,社区存在一个潜规则:视觉背骨在 ImageNet 上的 Top-1 准确率越高,它作为 VLM 插件的效果就越好。但本文作者通过实测泼了一盆冷水——ImageNet 准确率与 VLM 最终性能并不总是正相关。
作者发现,随着模型参数规模(Scaling)的简单增加,一些大型 ViT 背骨虽然分类更准了,但在物体定位任务中却出现了“性能倒挂”,甚至发生定位崩溃(Localization Collapse)。这种现象揭示了分类任务本质上在迫使模型放弃空间细节以换取全局语义。
2. 核心挑战:Transformer 的空间缺失
ViT 之所以面临这一瓶颈,源于其置换不变性(Permutation Invariance)。在 Transformer 结构中,空间结构主要靠位置编码支撑。一旦经过深度层级的抽象,这种细粒度的空间定位信息极易丢失。
相比之下,VMamba (SSM) 采用的是路径依赖的扫描机制。如图所示,VMamba 的 SS2D 层在二维 Token 网格上进行四个方向的扫描。这意味着空间结构在架构层面就被“锁死”在计算过程中。
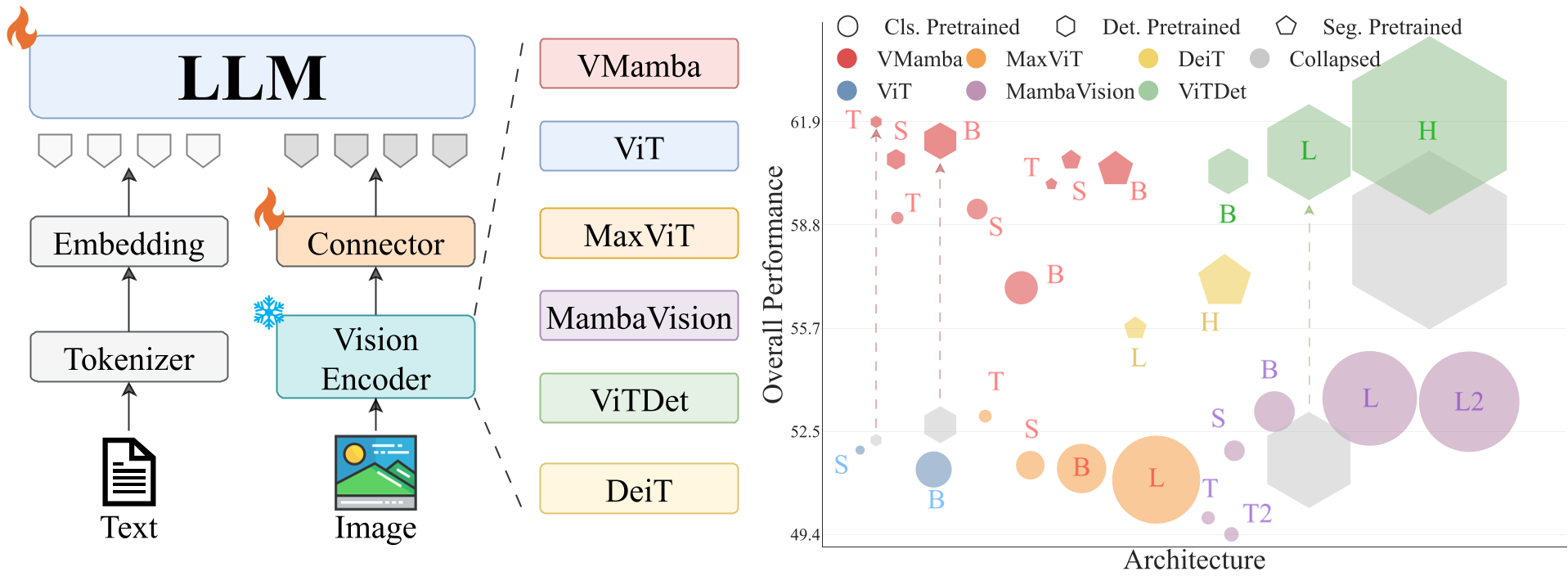 图 1:受控视觉编码器研究概览。作者将研究拆解为三个维度:架构(ViT vs SSM)、预训练目标(分类 vs 检测/分割)、以及接口(分辨率与连接器设计)。
图 1:受控视觉编码器研究概览。作者将研究拆解为三个维度:架构(ViT vs SSM)、预训练目标(分类 vs 检测/分割)、以及接口(分辨率与连接器设计)。
3. 实验对决:VMamba 的降维打击
为了公平对比,作者在相同的 LLaVA 式框架(Vicuna-7B)下,仅更换视觉背骨。
3.1 定位能力的质变
定量实验显示,在同等 Token 预算(196个 Token)和 ImageNet 初始化下,VMamba-T 在 RefCOCO 等定位基准上的评分远超 ViT-S。通过视觉特征图与文本 Token 的相似度可视化(如图 2 所示),我们可以直观地看到:
- ViT-S:反响弥散,在定位特定身体部位时(如“嘴巴”)会牵连整个上半身。
- VMamba-T:响应极度尖锐且精准,能锁定到具体的像素级区域。
 图 2:VMamba 展现出更清晰、更具空间选择性的文本-视觉对齐,其预测框(蓝色)比 ViT(红色)更接近 Ground-Truth(绿色)。
图 2:VMamba 展现出更清晰、更具空间选择性的文本-视觉对齐,其预测框(蓝色)比 ViT(红色)更接近 Ground-Truth(绿色)。
3.2 密集任务预训练的红利
如果说 VMamba 架构自带“导航”属性,那么使用目标检测(Detection)或语义分割(Segmentation)数据集预训练背骨,则能进一步激活这种能力。实验表明,经过分割训练的 VMamba 在保持轻量化尺寸的同时,性能足以叫板大它几倍的背骨。
4. 故障诊断:如何拯救“定位崩溃”?
在实验中,作者观测到一些高分辨率架构(如 ViTDet-L)在 VLM 中表现极不稳定。作者将其诊断为接口瓶颈:
- 传输瓶颈:Connector 层数太少,空间信号传不到 LLM。
- 利用瓶颈:非正方形的输入几何形状让 LLM “晕头转向”。
稳定方案 (Stabilization Strategy):
- 加深 Connector:将 2 层 MLP 升级为 3 层。
- 固定几何形状:统一采用 $512 imes 512$ 的正方形输入。 通过这两手操作,原本“瘫痪”的定位性能奇迹般地恢复了,这提示开发者:VLM 的稳定性往往不在于背骨本身,而在于背骨与 LLM 的衔接处。
5. 效率分析:SSM 的分辨率优势
对于开发者最关心的推理成本,实验显示:在相同的 VLM 环境中,VMamba 相比 ViT 对高分辨率输入的扩展性更友好。
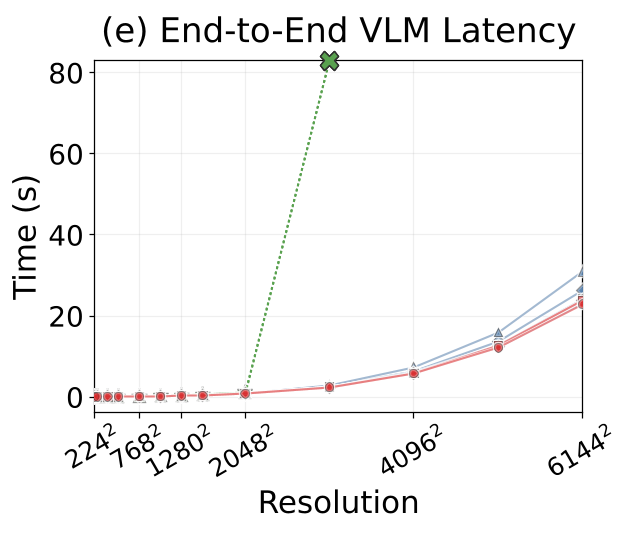 图 3:随着分辨率提升,VMamba 在 GPU 视觉阶段的延迟(图 c)增长比 ViT 更平缓,内存消耗也更具优势。
图 3:随着分辨率提升,VMamba 在 GPU 视觉阶段的延迟(图 c)增长比 ViT 更平缓,内存消耗也更具优势。
6. 总结与洞察
本研究最深刻的启示在于:VLM 并不一定要绑定在 Transformer 战车上。 SSM 模型凭借其内置的 2D 归纳偏置,在物体定位这种依赖空间结构的细粒度任务中展现了天然优势。
未来的 VLM 设计不应盲目执着于背骨的分类精度,而应寻找像 SSM 这样具有高效空间表征能力的组件,并匹配以容量足够的连接器与合理的图像输入协议。