阿里巴巴万网团队推出了 Wan-Image,这是一个将大语言模型(LLM)的认知能力与 Diffusion Transformer (DiT) 的高保真合成能力相结合的统一视觉生成系统。该系统实现了专业级的图像生成、交互式编辑和一致性序列图生成,在多项人类评估中超越了 Seedream 5.0 Lite 和 GPT Image 1.5。
TL;DR
阿里巴巴团队发布的 Wan-Image 不仅仅是一个刷榜的高质量画图模型,它是一套旨在重塑专业设计工作流的视觉智能系统。通过将 **MLLM(多模态大模型)的“大脑”**与 **DiT(扩散变换器)的“画笔”**深度融合,Wan-Image 攻克了超长文本渲染、多主体一致性、原生透明通道生成等专业领域的顽疾,在 4K 超清效率和精细编辑上达到了 SOTA 水平。
1. 痛点:为什么 SOTA 模型在专业设计面前“失灵”?
在Midjourney或DALL-E 3时代,我们赞叹于 AI 的美学表现。但在专业设计(如电商海报、排版设计、UI/UX)中,这些模型往往表现出“不听指挥”:
- 文本渲染: 无法准确处理长段文字,常出现拼写错误或布局混乱。
- 身份一致性: 在多图连环画或系列海报中,同一个角色往往“千人千面”。
- 编辑精度: 交互式修改时经常破坏全局背景,无法做到像素级的精确替换。
- 格式支持: 缺少原生的 Alpha 透明通道支持,导出后仍需人工抠图。
Wan-Image 的出现,正是为了将生成式 AI 从“娱乐化生成”推向“专业化生产”。
2. 核心架构:Planner + Visualizer 的协同进化
Wan-Image 摒弃了简单的 Text-to-Image 映射,而是采用了一种 “语义规划-视觉实现” 的解耦架构。
2.1 架构拆解
- Planner (MLLM): 作为大脑,负责深度语义推理。它能理解用户的纠结意图,并将其拆解为精确的视觉指令(如布局、色彩比例等)。
- Visualizer (DiT): 负责高质量像素生成。它继承了 Planner 的语义语义对齐能力,并在 DiT 框架下利用 Rectified Flow 范式进行训练。
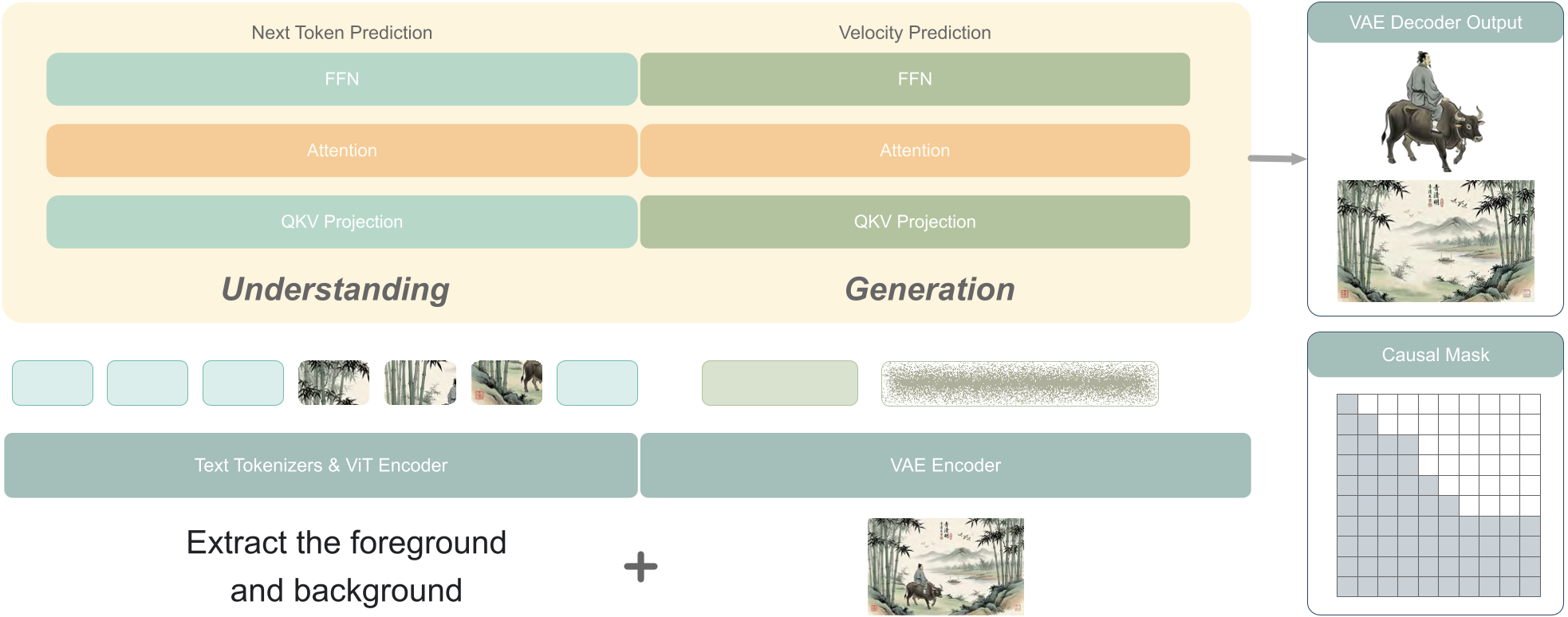
2.2 原生 4 通道 VAE 的降维打击
Wan-Image 研发了全新的高保真 VAE,不仅处理 RGB,还原生建模 Alpha 透明通道。这意味着它可以直接生成带透明背景的专业素材,模型在 16x16 压缩下依然能保持极高的文本边缘清晰度。

3. 专业级能力:不仅仅是画得像
Wan-Image 的核心竞争力体现在以下几个“硬核”能力上:
- 超长文本排版: 能够精确理解多行复杂的排版需求,文字清晰可见(见 Figure 6)。
- 极端长宽比: 支持高达 1:8 的比例,完美适配手机长图或电影感宽幅全景图。
- 逻辑序列生成: 一次性生成多达 12 张具有严格风格与角色一致性的系列图。
- 色板引导: 支持用户通过 Hex 颜色代码和比例精确控制画面色调。
4. 实验与实战表现
在人类偏好评估中,Wan-Image 展现了极强的统治力。相较于 GPT Image 1.5,它在编辑成功率和文本渲染上具有显著优势。
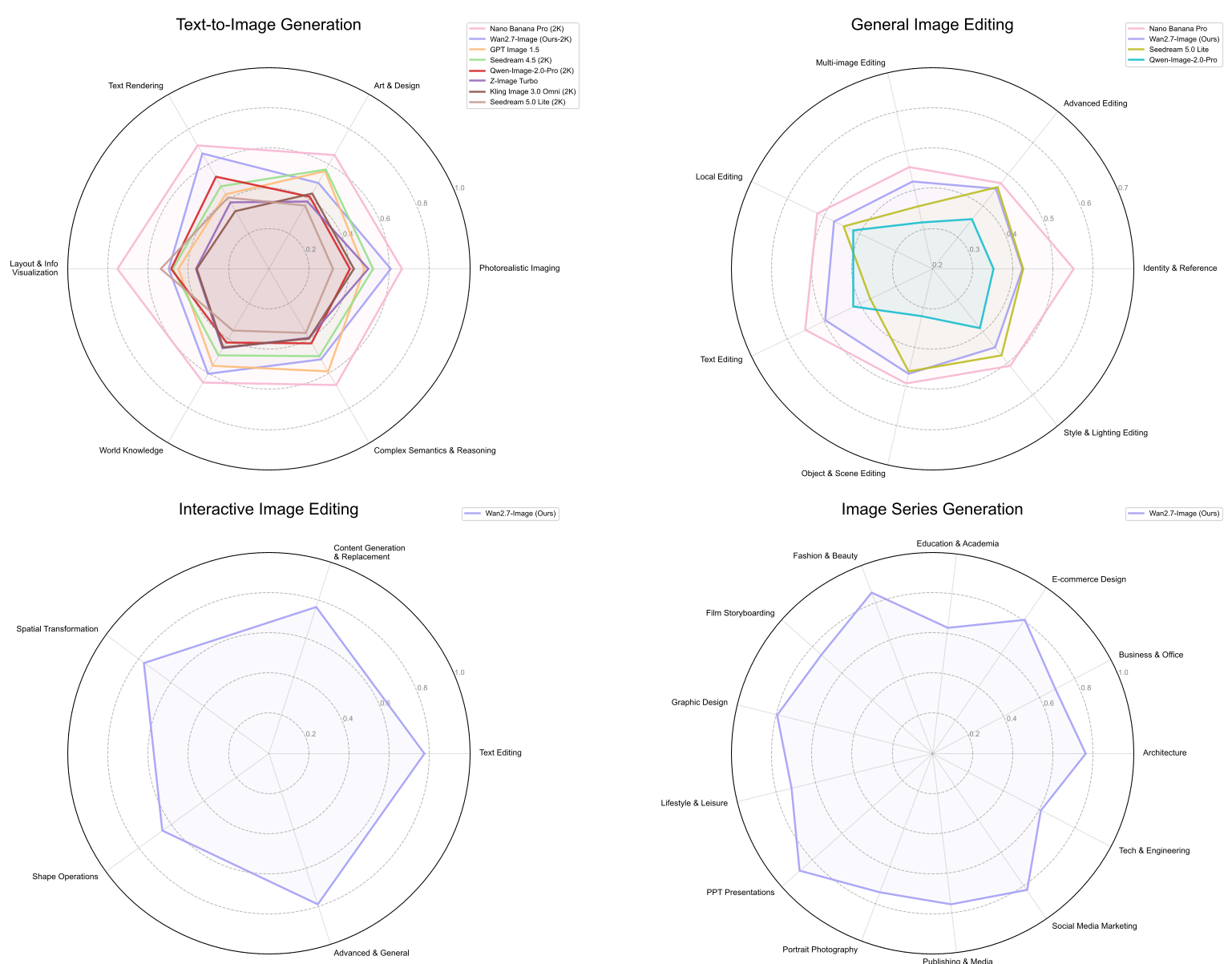
此外,通过 Cascade RL(级联强化学习) 框架,模型在 SFT 基础上进一步优化了人体结构(如手指)和美学表现,解决了不少扩散模型的通病。
5. 深度洞察:大模型对视觉生成的“软重构”
Wan-Image 的成功证明了一个观点:图像生成的未来不再是纯粹的像素分布拟合,而是语义认知的延伸。 引入 Prompt Enhancer(基于 Qwen3 控制的 CoT 推理)使得模型能像专业设计师一样“思考”空间布局与光影逻辑。
局限性与未来
尽管 Wan-Image 在专业领域迈出了一大步,但在极大规模主体的空间拓扑逻辑上(如 50 个人同时复杂的交互)仍有优化空间。此外,4K 超清模式下的资源开销仍是工业界需要持续优化的课题。
总结
Wan-Image 通过统一架构、大规模逻辑数据训练以及原生的 4 通道 VAE,成功将 AI 绘画从“随机抽卡”升级为“精准设计”。对于电商、设计及内容创意行业,这无疑是一个重大的生产力拐点。