本文提出了 λ-RLM,一种基于 λ-演算(λ-Calculus)的长文本推理框架。该方法将长文本处理转化为由确定性组合子(如 SPLIT, MAP, REDUCE)构成的结构化函数程序,显著提升了递归语言模型(RLM)的可靠性与效率。
TL;DR
面对超长文本,大语言模型(LLM)往往会陷入“上下文腐烂”——哪怕窗口够大,模型也会遗忘中间信息。本文提出的 λ-RLM 放弃了让模型自己写 Python 代码来搞递归(传统的 RLM 做法),转而采用数理逻辑中的 λ-演算 (λ-Calculus) 构建了一个硬核的函数式运行时。它通过确定性的算子(如 Y-Combinator)来接管程序的控制流,只让 LLM 负责最核心的原子级推理。结果是:8B 的模型跑出了 70B 的效果,且速度快了 4 倍。
痛点深挖:为什么让 LLM 掌控控制流是危险的?
目前的长文本处理方案(如 RLM)尝试让模型在一个 REPL 环境中通过生成代码来拆解问题。这种 “随机控制流” (Stochastic Control) 存在三大致命缺陷:
- 非终止性:LLM 可能会生成导致死循环的代码,推理停不下来。
- 编码税 (Coding Tax):小模型(如 7B/8B)代码生成能力弱,经常因为代码语法错误导致任务崩盘。
- 不可预测性:执行逻辑黑盒化,无法在运行前估算成本和深度。
作者的 Insight 在于:推理内容应该是神经的,但控制逻辑应该是符号的。
核心方法论:λ-RLM 的函数式美学
λ-RLM 的核心是将 LLM 推理表达为一个递归函数: $$ \lambda - \mathrm{RLM} \equiv ext{fix} (\lambda f. \lambda P. \mathbf{if} |P| \leq au^* \dots) $$
1. 组合子库 (Combinator Library)
系统弃用了任意 Python 代码,只允许使用一组预定义、经过形式化验证的组合子:
- SPLIT: 确定性分割文本。
- MAP: 将推理任务并行分发到各个分片。
- REDUCE: 按特定逻辑(如合并计数、排序筛选)聚合结果。
- M (Neural Oracle): 唯一的神经原语,仅处理能塞进 Context Window 的叶子片段。
2. Y-Combinator 实现无名递归
通过引入理论计算机科学中的 Y-Combinator,λ-RLM 实现了在不依赖外部函数命名的情况下“手动打结”完成递归。这意味着控制流被固化在了一套数学严谨的框架内。
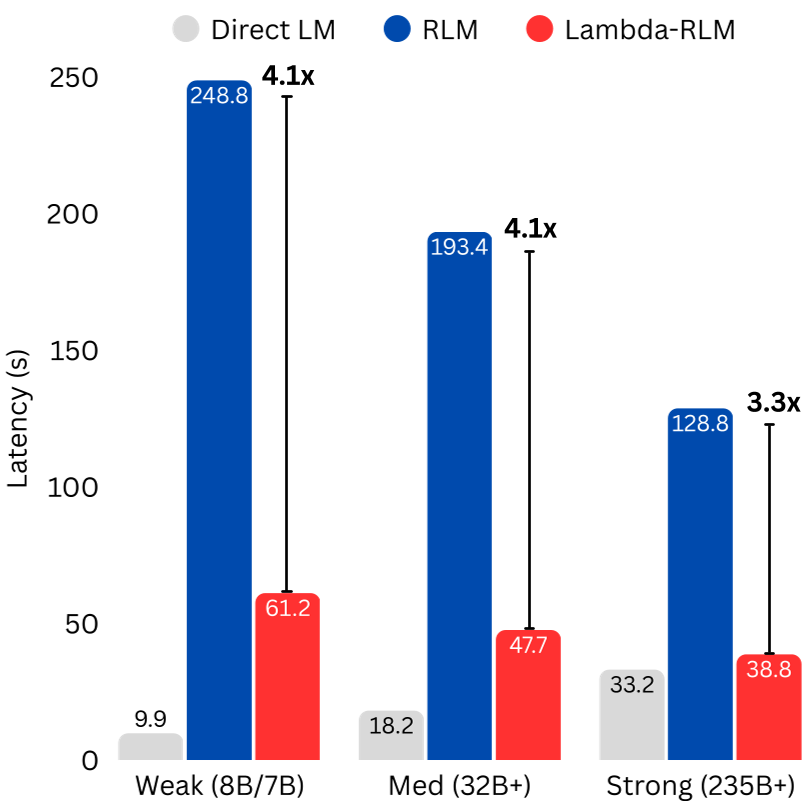 图 1:λ-RLM 与传统 RLM 的对比,可见其结构化的分发聚合流程。
图 1:λ-RLM 与传统 RLM 的对比,可见其结构化的分发聚合流程。
理论保证:从指数衰减到幂律平衡
作者证明了 λ-RLM 的几个关键数学特性:
- 终止性证明:通过定义 Rank 函数并证明每次 SPLIT 操作都会严格降低 Rank,保证了算法必然停止。
- 成本界限 (Cost Bound):总推理成本 $T(n)$ 是输入长度 $n$ 的确定性函数,可以在任务启动前精确计算。
- 准确率缩放:直接调用 LLM 处理长文本,准确率随长度 指数级衰减;而 λ-RLM 通过递归分解,将衰减控制在 幂律水平 (Power-law),甚至在可分解任务中保持准确率恒定。
实验与战绩
研究团队在 Llama-3、Qwen-3 和 Mistral 等多个模型家族上进行了压力测试,覆盖了从 $O(1)$ 到 $O(n^2)$ 复杂度的长文本任务。
核心发现
- 小模型逆袭:搭载了 λ-RLM 的 Qwen-3-8B(准确率 35.7%)直接击败了直接推理的 Llama-3.1-405B(准确率 27.2%)。
- 效率飞跃:在 OOL-Pairs(平方级复杂度任务)中,λ-RLM 实现了 6.2 倍 的加速。
 表 1:各模型在不同任务下的性能表现,λ-RLM (P3) 几乎全线飘红。
表 1:各模型在不同任务下的性能表现,λ-RLM (P3) 几乎全线飘红。
深度洞察与展望
λ-RLM 的成功揭示了一个重要的产业趋势:Agent 的可靠性不应寄希望于 LLM 的自觉,而应通过“类型化的脚手架”进行强约束。
局限性
- 灵活性牺牲:对于需要极高策略灵活性的任务(如动态修改搜索策略的 CodeQA),固定的組合子库可能显得过于死板。
- 规划器依赖:系统依赖一个非神经的 Planner 来决定最佳分割参数 $k^*$。
未来启示
λ-RLM 为未来的“高可靠大模型系统”提供了一套蓝图——将 LLM 视为一台执行原子β-归约的存储设备,而由 lambda 演算构建的符号逻辑层则充当操作系统。这种 Neuro-Symbolic 的深度融合,或许才是通往 AGI 推理的稳健之路。
关键词: #LLM #LongContext #LambdaCalculus #NeuroSymbolic #RecursiveReasoning