The paper introduces 3DCity-LLM, a unified framework for 3D city-scale vision-language perception and understanding. It leverages a coarse-to-fine feature encoding strategy and a massive 1.2M-sample dataset to achieve SOTA performance across tasks ranging from object analysis to urban planning.
TL;DR
While Large Language Models (LLMs) have mastered indoor "Object-Centric" tasks, the sheer scale of a city—with its thousands of entities and complex spatial dependencies—remains a frontier. 3DCity-LLM breaks this barrier by introducing a unified framework that can "see" and "reason" about cities. By combining a 1.2M-sample dataset with a coarse-to-fine feature encoding strategy, it achieves new SOTA results in urban perception, analysis, and goal-oriented planning.
The Challenge: Why Cities are Harder than Rooms
In an indoor setting, an LLM might identify a "chair" or a "table." In a city, the model must understand the functional role of a building, its precise 3D coordinates, and its relationship to landmarks.
Current 3D-VL (Vision-Language) models face three major bottlenecks:
- Scale Discrepancy: Moving from dozens of objects (indoor) to thousands (city-scale).
- Data Scarcity: Lack of 3D-grounded instructions that include numerical spatial data.
- Evaluation Gap: Traditional metrics like BLEU-4 penalize valid but differently-worded spatial descriptions (e.g., "45m Southwest" vs. "Next to the parking lot").
Methodology: Coarse-to-Fine Perception
The core innovation of 3DCity-LLM is its Coarse-to-fine Feature Encoding. Instead of a single global feature, it splits perception into three parallel branches that feed into an LLM backbone (like LLaVA-v1.5-7B):
- Object Encoding: Extracts visual patches (CLIP), 3D shapes (Uni3D), and landmark names (BERT).
- Relationship Encoding: Uses K-Nearest Neighbor (KNN) and attention mechanisms to calculate the geometric relevance between a target object and its surroundings.
- Scene Encoding: Provides a "God’s Eye View" via Bird’s-Eye View (BEV) images and global landmark maps to capture urban layout.
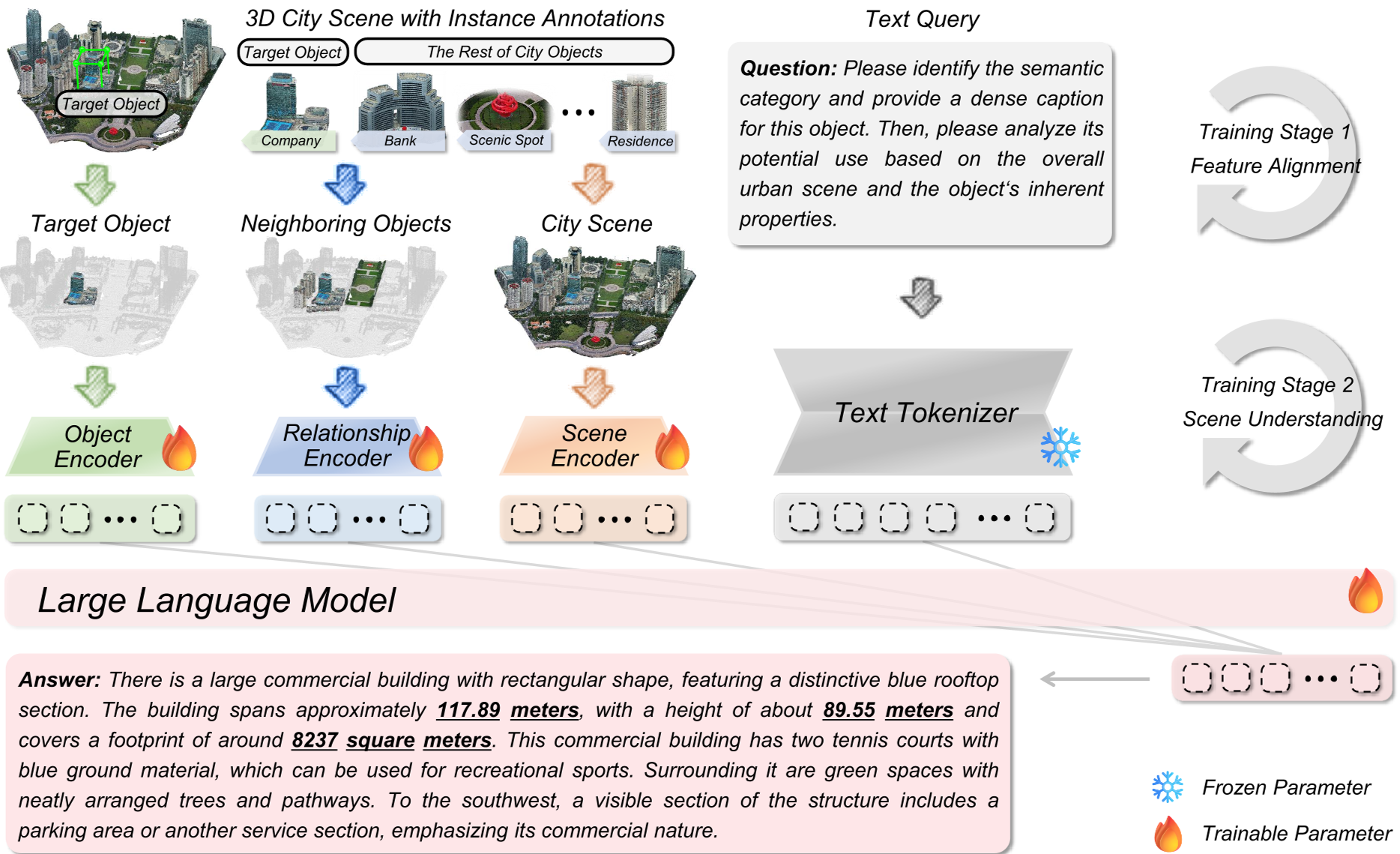
The 3DCity-LLM-1.2M Dataset
To power this architecture, the authors built the largest 3D city-scale instruction-tuning dataset to date.
- 7 Categories: Object Caption, Localization, Analysis, Relationship Computation, Scene Caption, Scene Analysis, and Scene Planning.
- Contextual Simulation: Questions are generated using different "personas" (e.g., a tourist vs. a government official) to ensure linguistic diversity.
- Numerical Precision: Unlike many VQA datasets, this one includes explicit 3D numerical information (coordinates/distances) to prevent model "hallucinations."

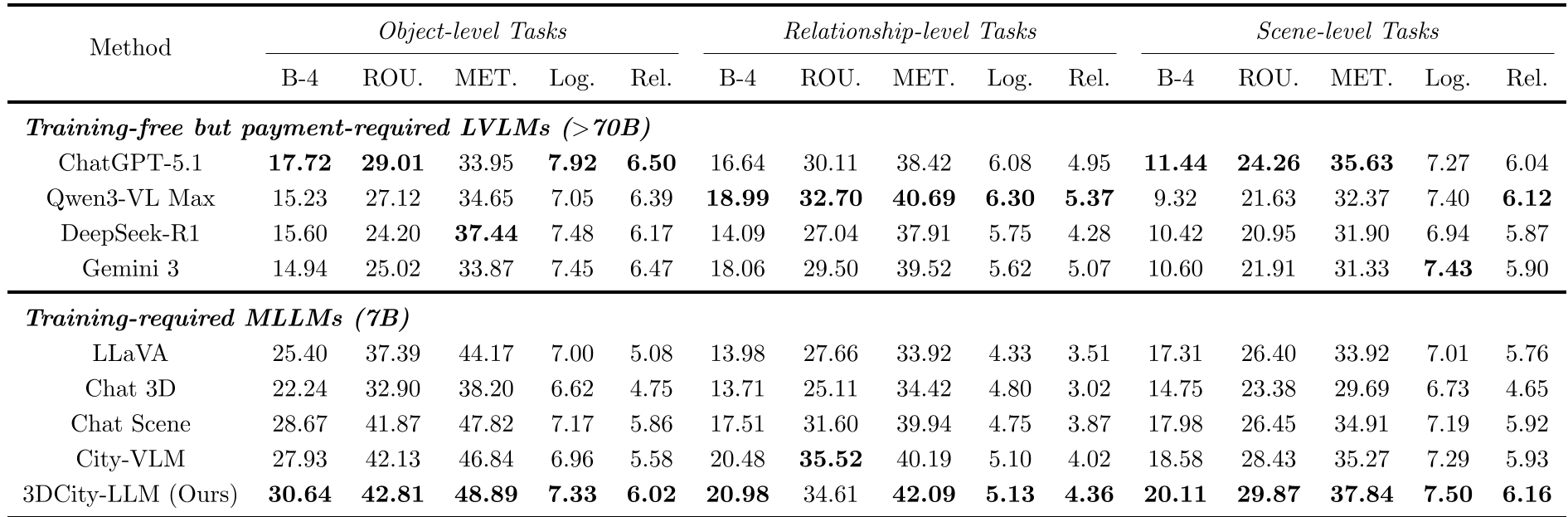
Experimental Performance & SOTA Comparisons
3DCity-LLM was evaluated against heavyweights like ChatGPT-5.1, Qwen3-VL, and specialized models like City-VLM.
- Quantitative Wins: It outperformed LLaVA-v1.5 by over 5.0 in BLEU-4 on object-level tasks and demonstrated superior Reliability scores in LLM-based evaluations.
- Spatial Reasoning: In the "Relationship Computation" task, the model accurately inferred orientations and distances where general-purpose LLMs often failed.
- Urban Planning: The model showed a unique ability to propose "Feasible interventions," such as adding pedestrian crossings or green corridors based on the actual layout of the processed city scene.
Evaluation Re-engineeered: Logicality & Reliability
A standout feature of this research is the transition away from purely text-similarity metrics. The authors used GPT-5 and DeepSeek-V3 as independent evaluators to score:
- Logicality: Internal coherence of the argument.
- Reliability: Factual alignment with the 3D scene evidence. This ensures that a model isn't just "mimicking text" but is actually "understanding space."
Critical Insights & Future Outlook
While 3DCity-LLM is a massive leap forward, its primary limitation lies in its backbone size (7B). The authors acknowledge that scaling to 13B or 34B models could further reduce errors in multi-hop spatial reasoning.
Takeaway: 3DCity-LLM proves that by structuring city data into a hierarchical "Object-Relationship-Scene" format, we can transform standard LLMs into sophisticated urban thinkers capable of assisting in real-world city planning and navigation.
Conclusion
3DCity-LLM provides both the "brain" (architecture) and the "books" (1.2M dataset) for the next generation of urban AI. It represents a significant step towards autonomous agents that can truly navigate and manage the complexities of human cities.