本文提出了 3DCity-LLM,这是一个专门为 3D 城市级场景设计的统一多模态大语言模型框架。通过引入“从粗到细”的特征编码策略和包含 120 万个样本的 3DCity-LLM-1.2M 大规模数据集,该模型在城市感知、空间推理和规划任务上刷新了 SOTA 纪录。
TL;DR
3DCity-LLM 是首个针对 城市尺度(City-scale) 优化的统一多模态大模型框架。它通过一套**从粗到细(Coarse-to-fine)**的特征编码体系,成功将万级别物体的复杂空间关系注入 LLM。配合其发布的 1.2M 规模高质量城市感知数据集,该模型在城市解析、关系计算及场景规划任务中均展现出超越 GPT-4 级模型的专业性。
1. 痛点:为什么 LLM 在城市面前会“走丢”?
目前的 MLLMs(如 LLaVA)在处理室内物体(如椅子、杯子)时表现优异,但在面对一个真实的城市时却显得力不从心:
- 实体海量化:一个典型的城市点块包含成千上万的实体,传统的全局特征编码会丢失微小但关键的目标。
- 关系复杂化:判断“哪家医院离火车站最近且急诊室在哪”不仅需要识别物体,还需要精准的坐标计算和拓扑语义推理。
- 数据稀缺性:现有的 3D 数据集多为室内或特定任务(如视觉定位),缺乏涵盖“目标-关系-场景”全维度的指令数据。
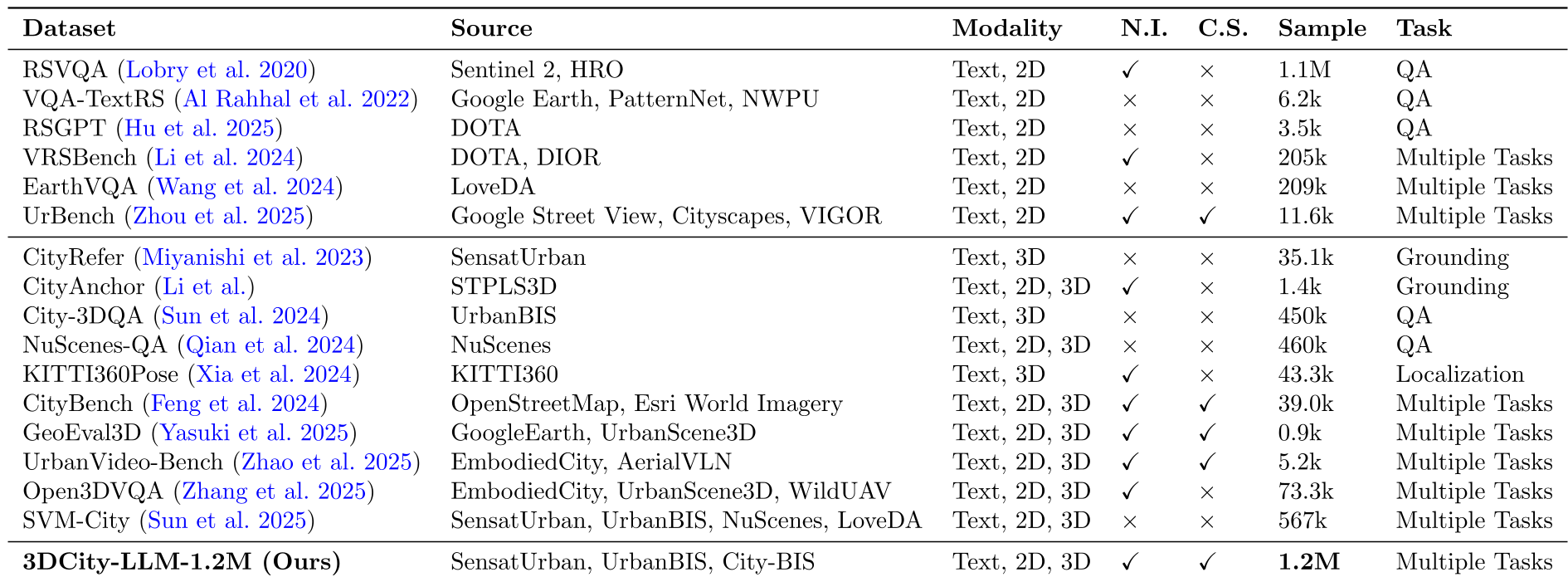 表 1:3DCity-LLM-1.2M 与现有主流数据集的对比,可见其在任务多样性和 3D 数值信息上的绝对性优势。
表 1:3DCity-LLM-1.2M 与现有主流数据集的对比,可见其在任务多样性和 3D 数值信息上的绝对性优势。
2. 核心机制:从粗到细的“三级跳”编码
为了让模型既能看清路牌,又能理解街区布局,3DCity-LLM 摒弃了单一的 Visual-Tokens 方案,采用了三支并行的编码策略:
A. 物体编码 (Object Branch)
对每一个目标,模型不仅抓取其被剪裁后的 2D 局部视觉特征(CLIP),还通过 Uni3D 提取其原始 3D 点云的几何形状特征,并辅助以 BERT 转换的地标语义(如“市政厅”)。
B. 关系编码 (Relationship Branch)
这是本文的精华所在。模型通过 KNN 搜索找到目标周边的邻居,利用注意力机制(Attention Strategy)计算目标与邻居间的偏移向量 ,从而让 LLM 真正意识到“左转 50 米”这种空间概念。
C. 场景编码 (Scene Branch)
利用 2D 鸟瞰图(BEV)和场景图谱捕捉宏观布局,为诸如“该社区是否需要增加人行横道”等规划类任务提供全局 Context。
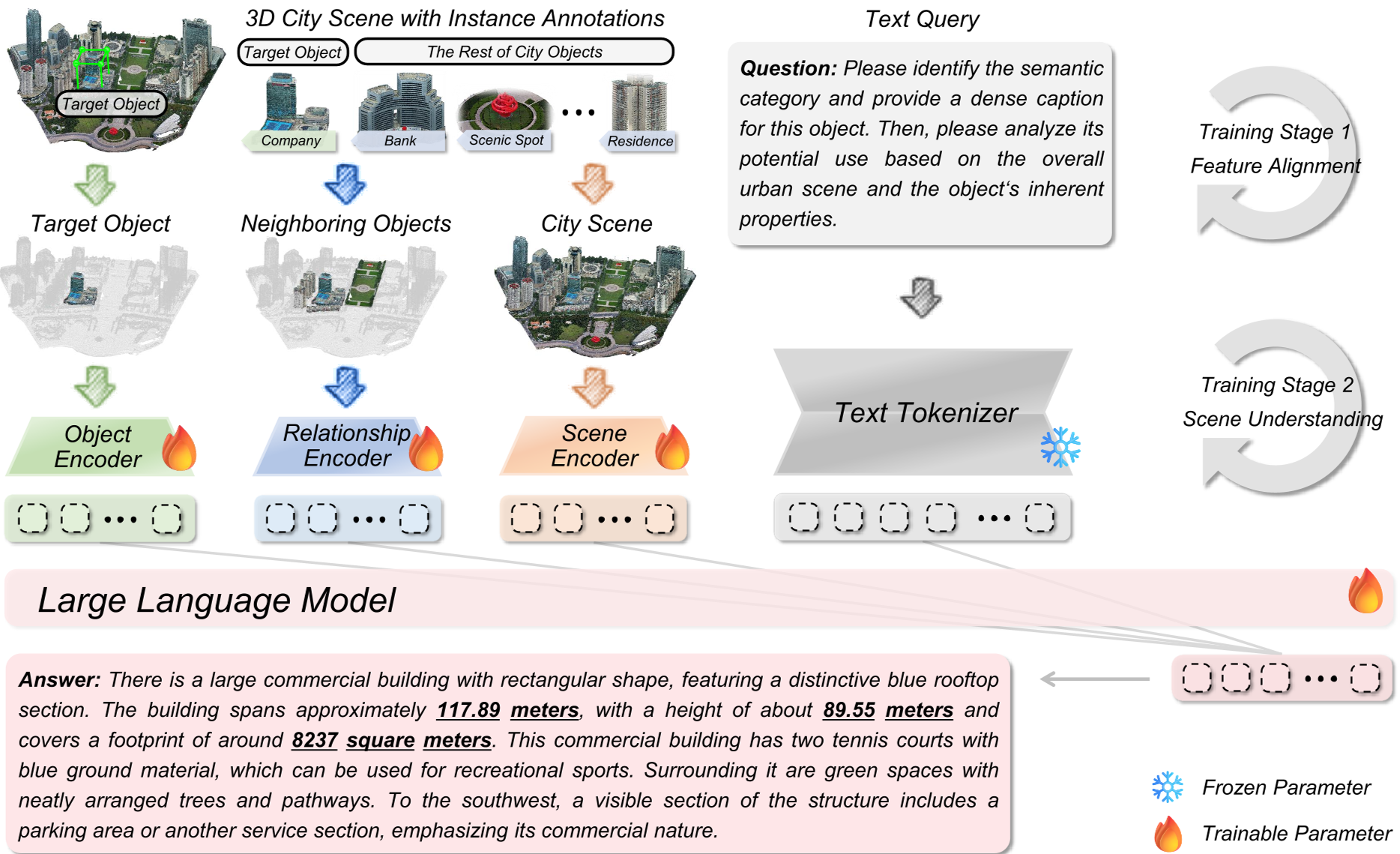 图 1:3DCity-LLM 整体架构,展示了从点云分割到多分支特征融合的过程。
图 1:3DCity-LLM 整体架构,展示了从点云分割到多分支特征融合的过程。
3. 3DCity-LLM-1.2M:城市级感知的大数据基石
作者利用 ChatGPT-5 和自动化管线构建了目前规模最大的城市指令数据集:
- 七大任务维度:涵盖物体描述、定位、分析、关系计算、场景描述、分析及终极的场景规划。
- 角色模拟定制:生成的 QA 不再是机械的描述,而是模拟游客、政府官员、建筑师等不同人设,使回答的语境更符合真实世界应用场景。
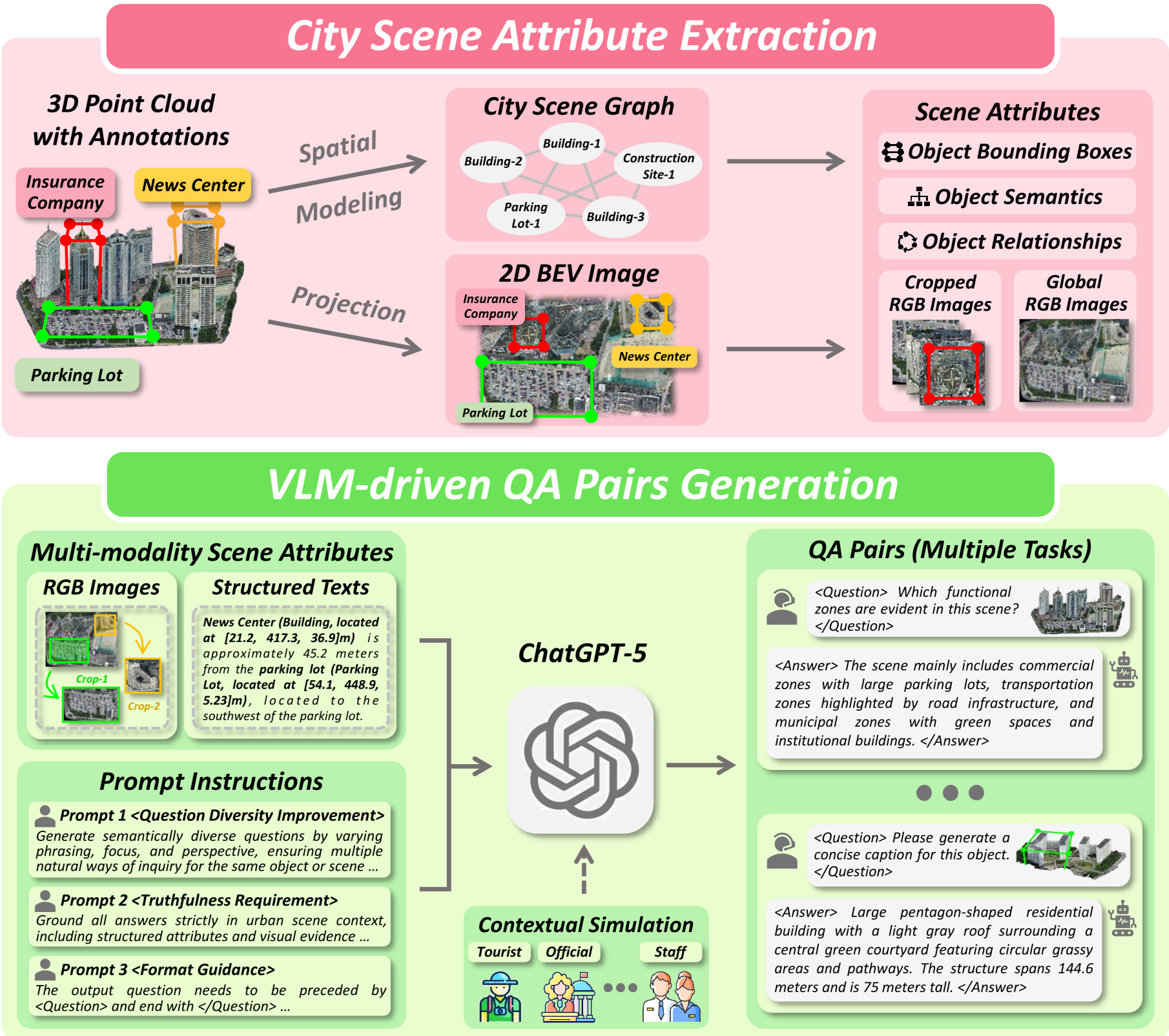 图 2:自动化数据生成管线,确保了数据的高多样性与 3D 事实一致性。
图 2:自动化数据生成管线,确保了数据的高多样性与 3D 事实一致性。
4. 实验:它真的懂城市吗?
在与 LLaVA、Chat 3D 以及商业级闭源模型(如 DeepSeek-R1, Gemini 3)的对比中:
- 精度屠榜:在 City-3DQA 测试中,3DCity-LLM 的准确率达到了 68.55%,显著超过同规模的基准。
- 评估进化:作者引入了基于 LLM 的 Logicality(逻辑性) 和 Reliability(可靠性) 评估。结果显示,3DCity-LLM 在解释“为什么选择这个位置进行开发”时,逻辑链路更清晰且更符合 3D 地形事实。
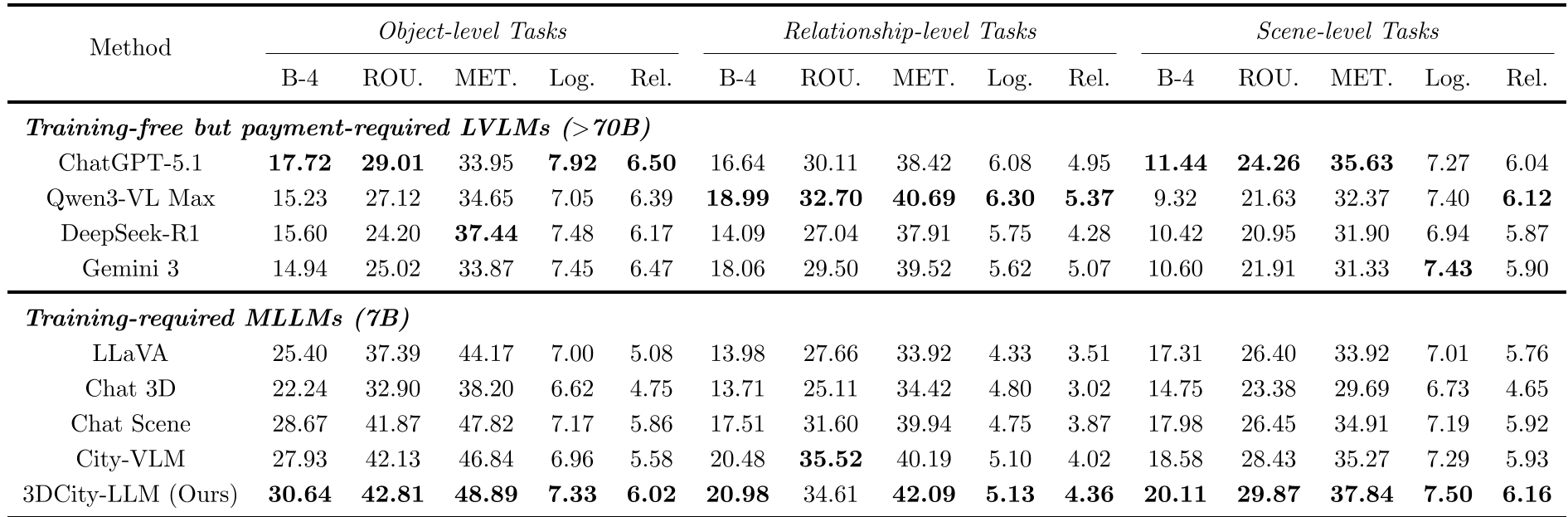 表 2:在物体级、关系级和场景级任务上的定量对比。
表 2:在物体级、关系级和场景级任务上的定量对比。
5. 深度洞察与展望
为什么 3DCity-LLM 有效? 其本质是在 LLM 的语义空间中植入了一个显式的 3D 坐标系坐标。传统模型是“看图说话”,而 3DCity-LLM 是在“查表推理”。
局限性: 目前的实验主要受限于显存限制,仅在 7B 参数规模上进行了验证。如果未来扩展到 70B 甚至更大的模型,其对城市尺度下发生的复杂多跳推理(Multi-hop Reasoning)能力可能会有爆炸式提升。
总结: 3DCity-LLM 不仅仅是一个模型,它为数字化双生、城市治理和智慧出行提供了一个能够“读懂城市”的通用大脑。