本文提出了 3DrawAgent,这是一个免训练(Training-free)的语言驱动 3D 草图生成框架。它将大语言模型(LLM)作为空间规划器,通过顺序生成 3D Bezier 曲线来构建物体,并在无需参数更新的情况下,通过对比经验优化(CKE)实现了 SOTA 性能。
TL;DR
3DrawAgent 是一个通过**免训练(Training-free)**方式教大语言模型(LLM)绘制 3D 草图的新颖框架。它不依靠梯度下降更新参数,而是借鉴了 GRPO(群组相对策略优化) 的思想,通过自我生成的优劣对比经验来“进化”其空间规划能力。它能将简单的文本指令转化为复杂的 3D Bezier 曲线集合,其表现甚至超越了一些需要重度生成的商业 SOTA 模型。
痛点深挖:从 2D 画布到 3D 空间的跨越
目前的 AI 绘画(如 DALL-E 3)已经很强,但在 3D 矢量草图领域仍面临两大鸿沟:
- 现有方法太重:像基于 Score Distillation Sampling (SDS) 的方法需要长时间的迭代优化(往往超过 60 分钟),成本极高且缺乏灵活性。
- 缺乏空间直觉:现有的 LLM 画图代理(如 SketchAgent)多局限于 2D 平面坐标,它们懂“形状”,但不理解“透视”、“深度”和“空间对称”。
核心机制:对比经验优化 (Contrastive Experience Optimization)
3DrawAgent 的核心在于它不是僵硬地执行指令,而是通过一种**“反思-总结-改进”**的黑盒强化过程来提升性能。
1. 语言驱动的空间规划
LLM 被赋予了 3D 艺术家的角色,它输出的是结构化的 Python 列表,定义了 3D Bezier 曲线的控制点。为了确保它不画出“纸片人”,Prompt 中显式定义了 Z 轴规则和坐标系限制。
2. 借鉴 GRPO 的对比学习
这是本文最出彩的地方。作者没有使用绝对的 Ground-truth 监督(这在艺术创作中很难定义),而是采用了成对比较:
- 生成候选集:针对同一个 Prompt 采样多个结果。
- 混合奖励模型:利用 CLIP 评估视觉对齐度,利用 LLM-as-a-judge 评估结构的逻辑合理性。
- 提炼经验库:将“为什么 A 比 B 好”的逻辑沉淀为文本经验(如“保持桌腿左右对称”),并将其作为下一轮生成的 In-context 约束。
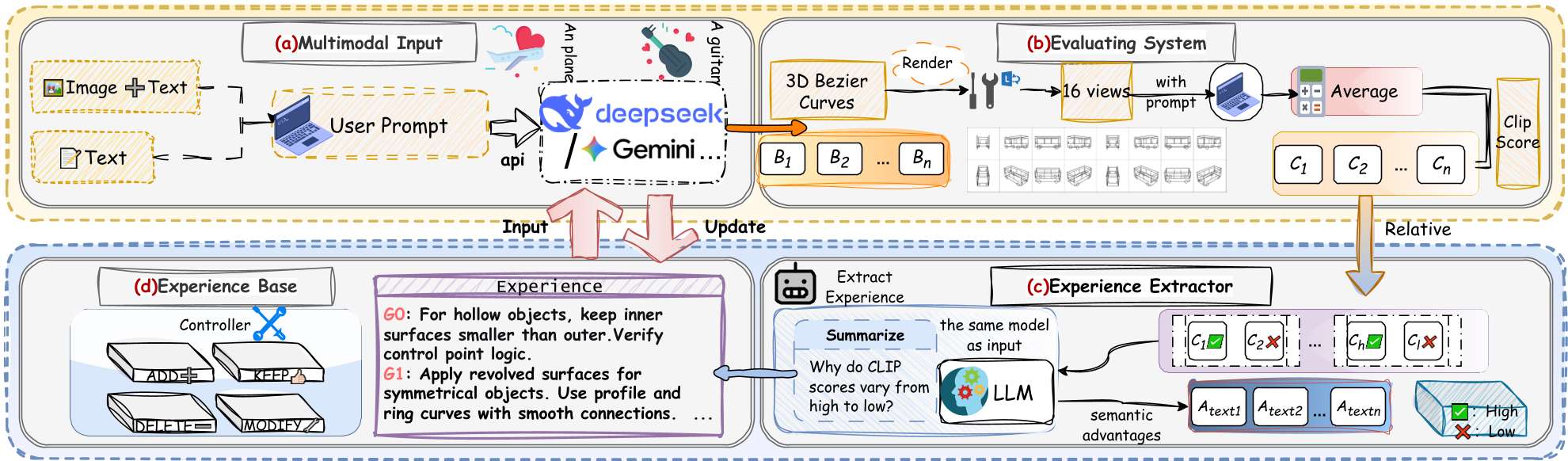 图1:3DrawAgent 框架流程:从文本生成、CLIP 评分到经验库迭代。
图1:3DrawAgent 框架流程:从文本生成、CLIP 评分到经验库迭代。
实验战绩:速度与质量的降维打击
在我们的实验中,3DrawAgent (基于 Gemini-2.5 Pro 或 DeepSeek-V3.2) 展现出了惊人的效率:
- 推理时间:从 SOTA 方法的 1-2 小时缩短至 2 分钟。
- 成本:单张草图生成仅需 0.09 美元。
- 主观评价:用户研究显示,其生成的线条比目前顶尖的 Diff3DS 更加干净、具有逻辑性,能有效避免“线条乱炖”现象。
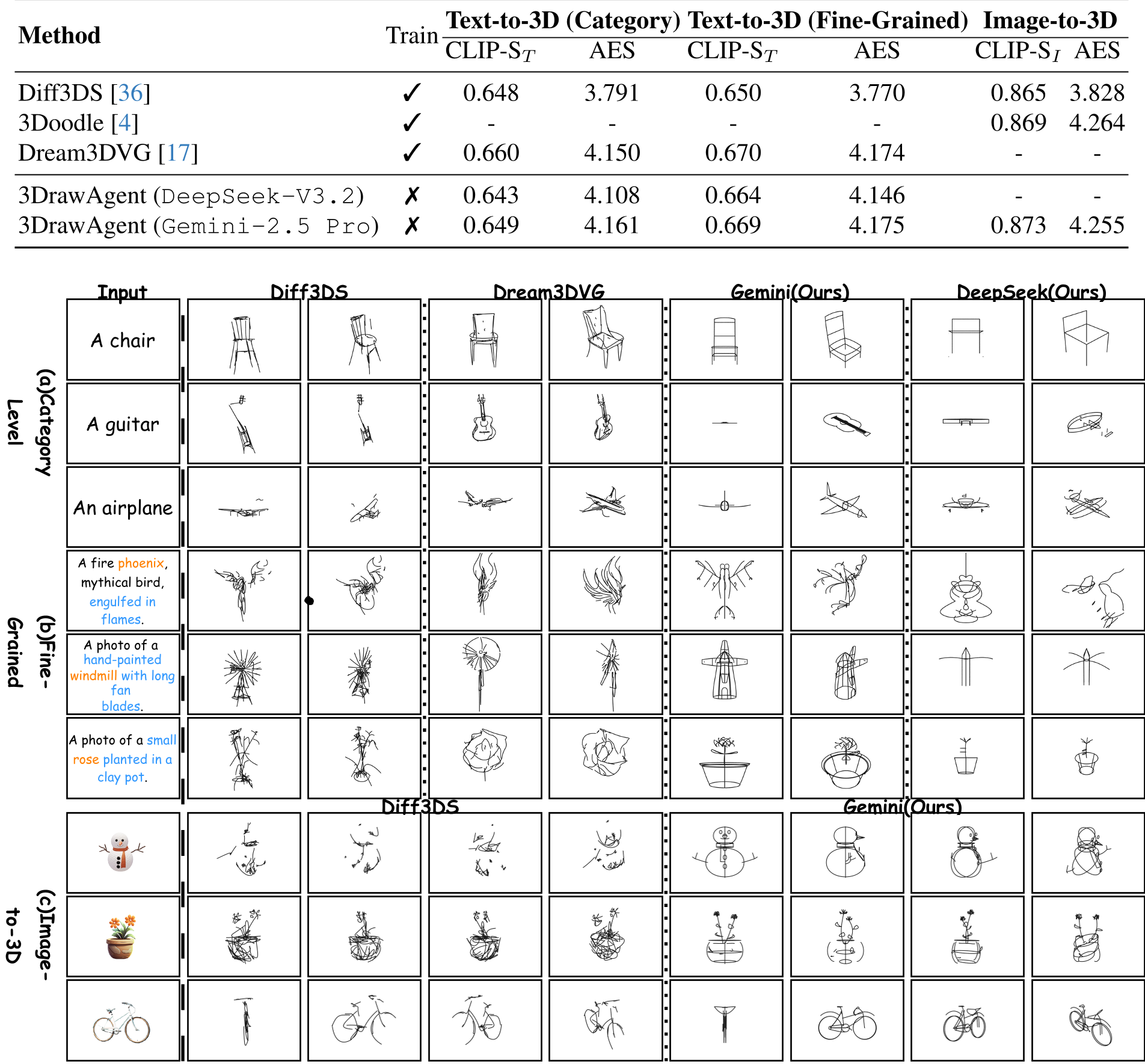 表1:与训练化基线(Diff3DS, Dream3DVG)的性能对比,3DrawAgent 在免训练模式下依然保持竞争力。
表1:与训练化基线(Diff3DS, Dream3DVG)的性能对比,3DrawAgent 在免训练模式下依然保持竞争力。
深度洞察:LLM 真的懂几何吗?
通过对“萃取经验”的变化分析,我们可以清晰地看到 LLM 的进化过程:
- 初期:关注基本的形状闭合和语法格式。
- 中期:开始留意部件分解和对称性。
- 后期:产生全 3D 空间意识,刻意避免平面坍缩(Planar Collapse),学会利用 Z 轴分配控制点。
这种从“形似”到“空间感知”的跨越,并非来源于权重微调,而是来自于语言空间的语义反馈。
局限性与未来展望
尽管表现惊艳,3DrawAgent 在局部细节连接上偶尔会失手(例如桌腿与桌面的微小断裂)。这说明完全依赖高层语义(CLIP)可能无法解决像素级的拓扑约束。
总结 (Takeaway): 3DrawAgent 标志着 LLM 在 3D 领域的应用进入了新阶段。它告诉我们:“反思可能比训练更高效”。未来,这种基于经验累积的免训练推理,可能成为生成式模型在多模态理解方向的主流范式。