本文提出了一种用于足式机器人的主动形态识别(Active Embodiment Identification)方法,通过强化学习联合训练信息寻求行为与显式形态预测。该方法基于改进的 URMA 架构,使机器人(如 Unitree Go2, ANYmal C, G1 等)能够通过与环境的交互动作,主动推断自身的关节级及全局物理参数。
TL;DR
在机器人控制中,如果机器人不了解自己的“身体”(如质量分布、关节惯量),它的动作就会因保守而显得笨拙。本文提出了一种 Active Embodiment Identification 方法,让足式机器人学会通过特定的“试探性”动作(主动感知)来推断自身的物理特质。通过强化学习,机器人不仅学会了走路,还学会了如何通过运动来“认识”自己。
背景:被动适应与主动认知的鸿沟
在传统的强化学习训练中,我们通常使用 域随机化 (Domain Randomization)。这意味着机器人在模拟器中需要应对成千上万种形态各异的身体参数(比如有的腿重、有的电机阻塞)。
- 痛点:为了在所有随机环境中生存,机器人策略往往变得极其保守 (Conservative)——它不敢跑太快,因为不知道当前的电机是否撑得住。
- 直觉 (Insight):如果机器人能像运动员在赛前热身一样,通过几个动作抖动一下关节、感受一下重心,就能瞬间锁定当前的物理参数,从而切换到性能最强的运动模式。
核心方法:URMA 架构的高级形态
作者采用了 Unified Robot Morphology Architecture (URMA) 这一能够处理不同关节数量和结构的统一架构。但这篇论文更进一步,引入了“主动”的逻辑:
-
形态预测网络 (Identification Network):
- 这是一个带有 GRU 记忆模块的循环神经网络。
- 它接收历史交互序列(动作、传感器回传),输出预测值。
- 双头设计:一个预测全局参数(如总质量、重心位置),另一个预测关节级参数(如定子惯量、旋转范围)。
-
主动策略 (Information-Seeking Policy):
- 不同于寻常的“行走”任务,这个策略的目标是最大限度降低预测误差。
- 奖励函数设计: 这个公式强制策略寻找那些最能暴露物理特征的动作。
 图 1:从 Unitree Go2 到人形机器人 Booster T1,算法需要适配多种形态。
图 1:从 Unitree Go2 到人形机器人 Booster T1,算法需要适配多种形态。
实验结果:精准“称重”与动态学习
实验覆盖了四足(ANYmal C)和双足人型机器人。通过在 MJX 物理引擎中 20 亿步的疯狂训练,研究者观察到了惊人的现象:
- 质量识别极其精准:对于一台总重 100 kg 的 ANYmal C,预测误差仅为 0.25 kg。
- 维度捕捉:机器人可以精准推断出自己躯干的物理形状和质心位置(毫米级精度)。
- 行为表现:为了识别参数,训练出的策略会维持一个稳定的站姿,并伴随中小幅度的各关节抖动——这正是它在“感受”自身的物理响应。
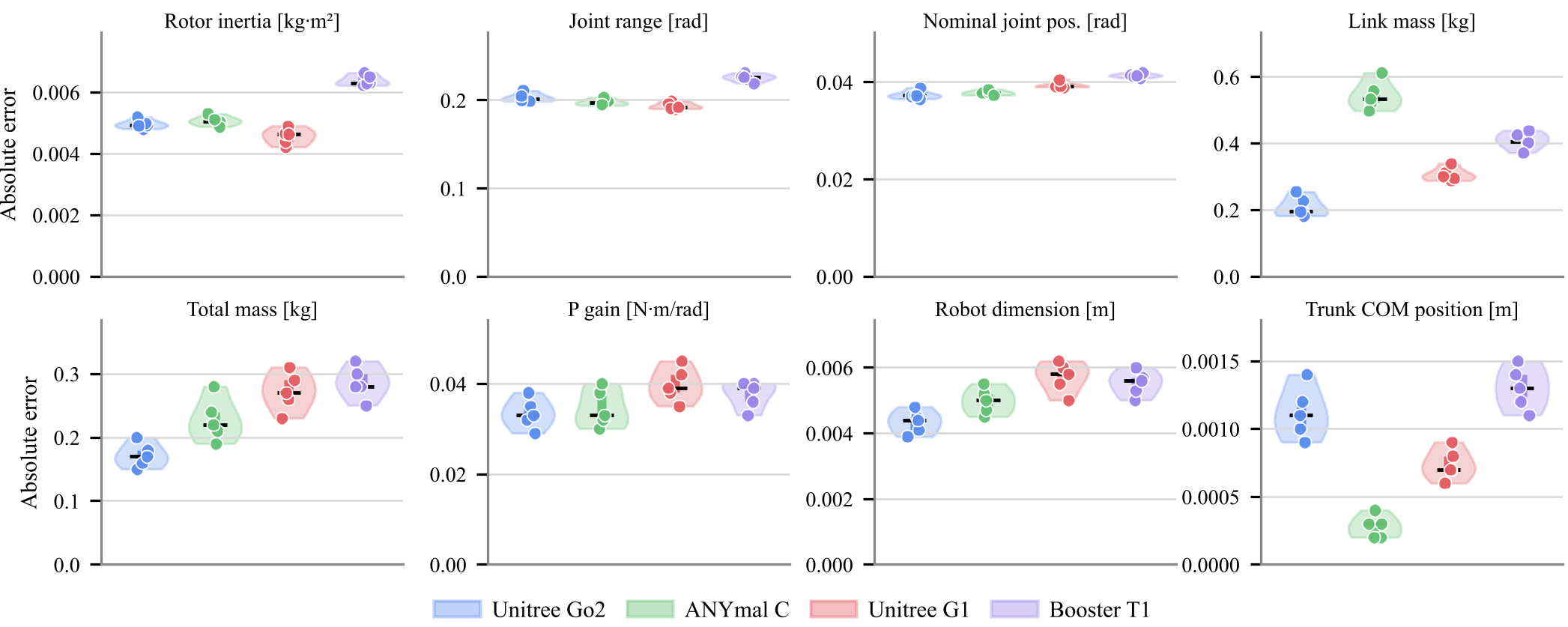 图 2:不同参数的预测误差统计。下行显示的全局参数识别精度远高于上行的微观关节参数。
图 2:不同参数的预测误差统计。下行显示的全局参数识别精度远高于上行的微观关节参数。
深度洞察:瓶颈在哪里?
尽管全局参数预测完美,但作者也坦诚指出:最大扭矩 (Max Torque) 和最大速度 极其难测。
- 逻辑分析:要识别最大扭矩,机器人必须做出极限动作。然而在 RL 训练中,由于存在摔倒终止(Termination)的惩罚,策略倾向于保持稳定。这种“安全本能”限制了机器人探索硬件极限的能力。这就如同一个不敢踩油门到底的司机,永远无法确定这台车的马力极限是多少。
总结与展望
这篇论文展示了足式机器人在复杂动态环境下的一种新型演化路径。未来的研究方向在于如何将这些在线预测的参数即时反馈回控制闭环(Closed-loop control),实现真正的“形态自适应运动”。
对于具身智能领域而言,这提供了一个重要启示:智能不应只是对环境的反应,更应是对自身边界的探索。