[ICLR/OpenReview] AdaCubic:突破参数调优瓶颈,二阶自适应优化器的实用化飞跃
本文提出了 AdaCubic,一种新型自适应三次正则化(Cubic Regularization)二阶优化器。该方法通过求解一个带三次约束的辅助优化问题来动态调整正则化权重,并结合 Hutchinson 方法高效估算 Hessian 矩阵对角线,实现了在深度学习任务中的可扩展应用。
TL;DR
在深度神经网络的非凸景观(Loss Landscape)中,寻找最优解如同在迷雾森林中穿行,鞍点(Saddle Points)是阻碍收敛的主要陷阱。本文提出的 AdaCubic 优化器通过自适应控制三次正则化(Cubic Regularization)项的权重,不仅在理论上继承了牛顿法逃离鞍点的能力,更在工程上实现了无需手动调节学习率的高效收敛。
背景定位:为何现有的优化器还不够好?
尽管 Adam 和 SGD 统治了深度学习领域,但它们本质上是利用一阶梯度信息的。二阶优化器(如牛顿法)虽然理论收敛极快,但面临两大痛点:
- 计算爆炸:存储和计算 的 Hessian 矩阵在千万级参数的模型中是不现实的。
- ** saddle points 困境**:标准的牛顿法在鞍点处表现极为挣扎。
虽然 Nesterov 等人提出的 Cubic Regularization (CR) 理论上解决了鞍点问题,但其正则化参数 的选择却成了一门黑艺术,严重依赖人工微调。
核心直觉:将正则化转为自适应约束
AdaCubic 的作者提出了一个巧妙的转化:不再设定固定的 ,而是引入一个辅助约束优化问题: 通过拉格朗日乘子理论,作者证明了三次正则化参数 本质上对应于这个约束问题的对偶变量。这意味着,通过动态调整约束半径 ,模型可以自动计算出最合适的 。
算法流程
- Step 1: 利用 Hutchinson 方法通过 Hessian-vector product 估算 Hessian 的对角线。
- Step 2: 调用
RootFinder过程(Algorithm 2),基于当前的曲率信息找到满足最优性条件的步长 。 - Step 3: 根据实际损失下降值与预测下降值的比例(Trust Region 机制)来决定是否接受更新。
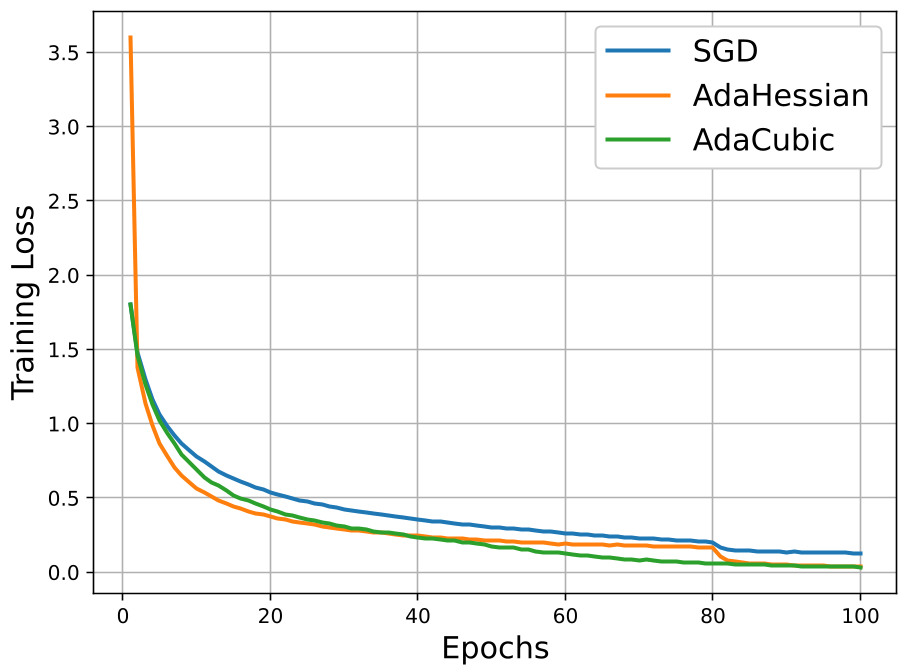
实验战绩:性能与效率的平衡线
1. 收敛速度的降维打击
在 CIFAR-10 训练 ResNet20 的测试中,AdaCubic 展示了惊人的收敛质量。正如实验图表所示,它在不到 60 个 Epoch 时就达到了其他优化器 80 个 Epoch 后的 Loss 水平。
2. 多领域普适性
尤其值得注意的是,AdaCubic 在 CV、NLP(GLUE 任务)和信号处理任务中使用的是完全相同的一套超参数。在 NLP 任务中,即使是对抗精细调优(Fine-tuned)过的 SGD 和 Adam,AdaCubic 依然能占据第二名或最佳的位置。
| 任务类型 | 关键结果提升对比 | | :--- | :--- | | 视觉识别 (CIFAR) | 接近 SOTA 二阶优化器 AdaHessian,远超传统 SGD | | 语言模型 (WikiText) | 在 BERT 模型上 Perplexity 显著低于 AdaHessian (5.75 vs 16.15) | | 相机模型识别 (CMI) | 相比 Adam,准确率稳定提升了 0.78% - 2.57% |
深度洞察:为什么它有效?
AdaCubic 的成功在于它找到了“二阶信息的精度”与“计算成本”之间的 Sweet Spot:
- 对角线近似 (Diagonal Approximation):虽然丢失了 Off-diagonal 的参数交互信息(这解释了为什么在某些高度复杂的 Transformer 任务中略逊于精调的一阶方法),但极大地降低了内存足迹(仅为 )。
- 自适应 M 的动态范围:在 Loss Landscape 平坦处, 会自动减小以加速推进;在剧烈震荡区, 增大以增强约束。
总结与展望
AdaCubic 是第一个将三次正则化成功规模化应用到深度学习中的优化器。它最吸引人的价值在于其 “Low Sensitivity” —— 对学习率等超参数极低的需求。对于那些计算资源有限、无法进行大规模 Grid Search 进行调参的开发者来说,AdaCubic 提供了一个极其诱人的“点火即用”的选项。
未来的研究方向可能在于如何更好地捕获 Transformer 块级(Block-wise)的非对角曲率信息,同时保持这种优雅的自适应特性。
主编点评:在过度依赖人工调参的深度学习时代,AdaCubic 这种回归数学直觉、追求算法自动化适应性的工作,才是真正推动 AI 基础设施向“自动驾驶”进化的力量。