AdaMem is an adaptive user-centric memory framework designed for long-horizon dialogue agents, organizing history into working, episodic, persona, and graph structures. It achieves State-of-the-Art (SOTA) results on the LoCoMo and PERSONAMEM benchmarks by utilizing a multi-agent collaborative pipeline for target-aware retrieval and reasoning.
TL;DR
As LLM agents move toward "infinite" interaction horizons, the bottleneck has shifted from context window size to memory retrieval precision. AdaMem introduces a sophisticated, multi-layered memory framework that organizes dialogue into working, episodic, persona, and graph structures. By replacing monolithic retrieval with a specialized multi-agent pipeline (Research, Memory, and Working Agents), AdaMem achieves a staggering +23.4% F1 improvement in temporal reasoning and sets new SOTA records on the LoCoMo and PERSONAMEM benchmarks.
The "Semantic Trap" in Modern Memory Systems
Most current agent frameworks (like MemGPT or Zep) treat memory as a flat pool of text chunks. This leads to three critical failures:
- The Similarity Blindspot: If a user previously mentioned a preference that isn't lexically similar to a new question, traditional semantic search (Vector DBs) will miss it.
- Fragmentation: Storing "events" as isolated chunks destroys the causal and temporal links (the why and when).
- Rigid Granularity: A simple fact-check and a complex temporal reasoning task are often treated with the same retrieval strategy, leading to either noise or insufficient context.
AdaMem’s core insight is that memory must be structured like human cognition: distinguishing between what is happening now (Working), what happened (Episodic), who the person is (Persona), and how it’s all connected (Graph).
Methodology: The "Agentic" Approach to Memory
AdaMem abandons the "one-size-fits-all" retrieval model in favor of a specialized triple-agent architecture.
1. Hierarchical Memory Construction
Instead of raw text, the Memory Agent normalizes every utterance into a structured record (topic, attitude, facts, attributes).
- Working Memory: A 20-message FIFO buffer.
- Episodic & Persona: Consolidated records that merge similar events into "themes" to prevent redundancy.
- Graph Memory: A heterogeneous scaffold where nodes (messages, topics, facts) are connected by typed edges (mentions, supports, temporal_next).
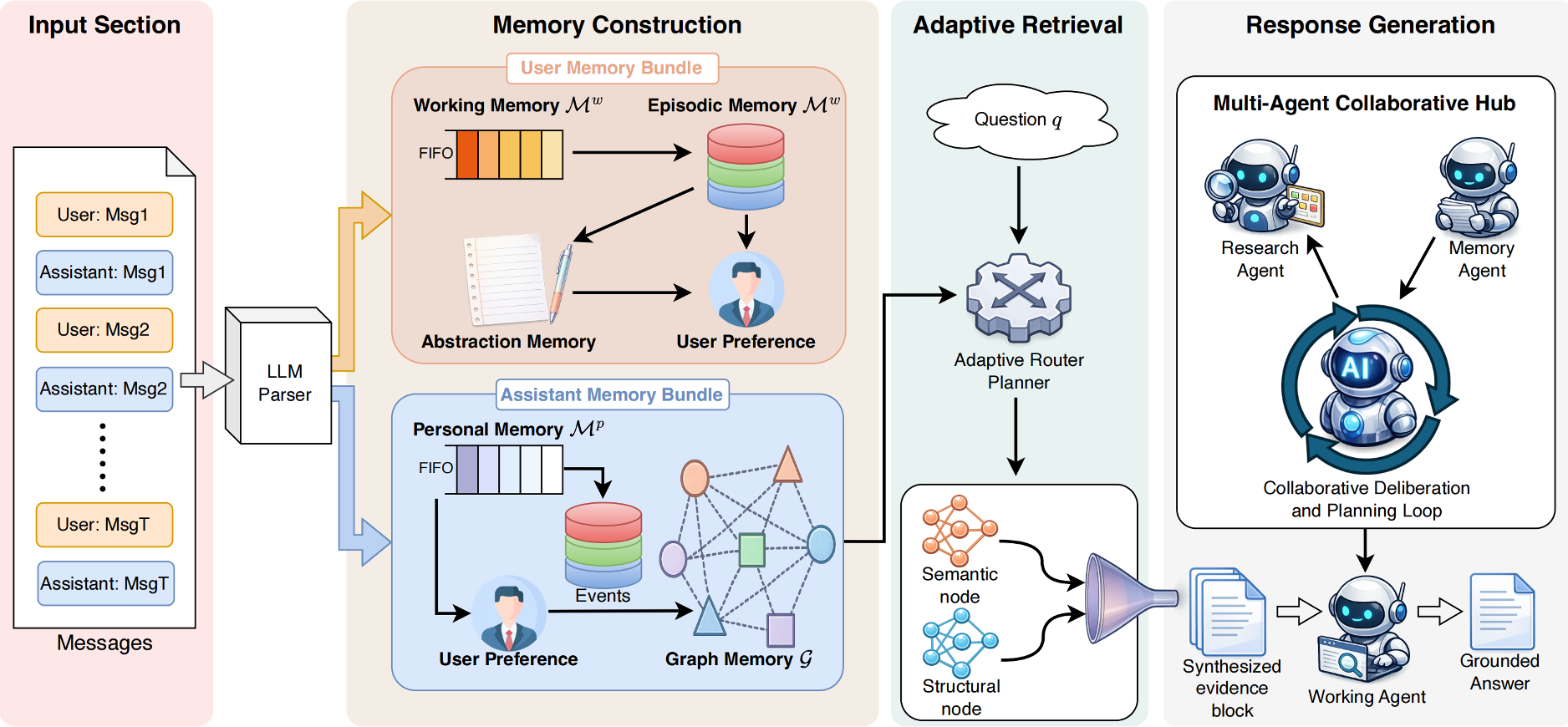 Figure 1: The AdaMem Pipeline—From dialogue processing to multi-agent synthesis.
Figure 1: The AdaMem Pipeline—From dialogue processing to multi-agent synthesis.
2. Question-Conditioned Route Planning
When a question arrives, AdaMem doesn't just "search." It plans.
- It identifies the Target Participant (User vs. Assistant) to narrow the search space.
- The Route Planner detects cues (e.g., "Why" or "Before") to decide if it needs a simple semantic lookup or a multi-hop Graph Expansion. This prevents computational waste on simple queries while providing deep context for complex ones.
3. Multi-Agent Synthesis
- Research Agent: Iteratively gathers evidence, reflects on whether it has "enough" info, and issues follow-up queries.
- Working Agent: Finalizes the answer, ensuring it is grounded in the "Research Summary" rather than hallucinated from model weights.
Experimental Results: Dominating Long-Horizon Benchnarks
AdaMem was tested against industry-standard baselines (MemGPT, Mem0, Zep) across two massive benchmarks: LoCoMo (long-term reasoning) and PERSONAMEM (user profiling).
 Figure 2: Superior performance of AdaMem across Multi-hop, Temporal, and Single-hop categories.
Figure 2: Superior performance of AdaMem across Multi-hop, Temporal, and Single-hop categories.
Key Metrics:
- Overall Performance: Reached 44.65% F1 on LoCoMo (+4.4% to +12.8% relative gain).
- Temporal Reasoning: The graph-based approach yielded a massive +23.4% improvement, proving that relational edges are superior to flat chunks for "when" questions.
- User Generalization: On PERSONAMEM, AdaMem showed a 27.3% lead in "generalizing to new scenarios," highlighting the power of the Persona memory module.
Critical Analysis & Takeaways
AdaMem proves that structure is the new scale. While it introduces higher latency (~4.7s vs Mem0’s ~3.7s) due to its multi-agent loop, the trade-off in accuracy is decisive.
Why it works:
- Participant-Awareness: By separating user and assistant memory "bundles," the model avoids the identity confusion common in multi-turn chats.
- Evidence Fusion: Combining semantic rank, graph rank, and recency priors creates a much more robust "confidence score" for retrieved evidence.
Limitations:
The system still struggles with Temporal Normalization (e.g., converting "last year" to "2022" if the absolute date wasn't explicitly grounded during the "Write" phase). Future work will likely need to focus on hard symbolic grounding at the moment of memory consolidation.
Final Verdict: AdaMem is a blueprint for the next generation of "Personal AI" that needs to actually know the user over months or years of interaction, rather than just reciting the last 10 minutes of conversation.