The paper introduces an Adaptive Greedy Frame Selection method for long-video understanding, which optimizes a submodular objective balancing query relevance and semantic coverage. By routing questions to specific trade-off presets via a lightweight classifier, it achieves new SOTA performance on the MLVU benchmark, significantly outperforming uniform sampling and previous methods like AKS.
TL;DR
As video context grows, VLMs struggle to stay within token limits without losing critical info. Purdue researchers have developed an Adaptive Greedy Frame Selector that treats frame sampling as a submodular optimization problem. By switching between "Relevance" and "Coverage" modes based on the question type, they've set a new standard for efficient long-video understanding without retraining the underlying VLM.
Background: The Sampling Bottleneck
In the era of Long-Video Understanding (LVU), the primary bottleneck isn't just the model's parameters, but the visual token budget. If you sample uniformly, you miss "needle-in-a-haystack" moments. If you sample by relevance alone, you get five nearly identical frames of the same action, wasting slots that could have been used to cover the rest of the video. This work identifies two core failure modes: Redundancy Collapse and Coverage Collapse.
Methodology: The Best of Both Worlds
The authors transform frame selection into a mathematical subset selection problem. They utilize two distinct embedding spaces to evaluate candidates:
- SigLIP Space: Measures how well a frame answers the specific question (Relevance).
- DINOv2 Space: Measures the semantic "uniqueness" of a frame relative to the whole video (Representativeness).
The core objective function combines a modular relevance term with a Facility-Location Coverage term. Because this function is monotone and submodular, a simple greedy algorithm can find a near-optimal set of frames with a guaranteed bound.
 Note: The system first builds a 1 FPS candidate pool before applying the greedy selector.
Note: The system first builds a 1 FPS candidate pool before applying the greedy selector.
The "Secret Sauce": Question-Adaptive Routing
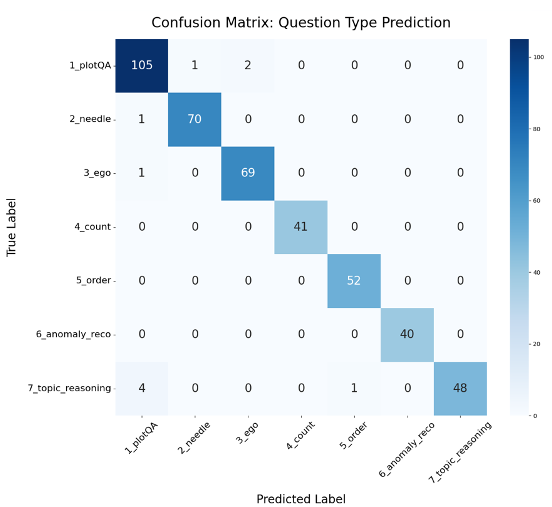
Perhaps the most insightful contribution is the Query-Adaptive nature of the system. The paper argues that a "Summary" question needs broad coverage, while an "Action Counting" question needs high relevance to specific movements. They trained a lightweight text-only classifier (97.7% accuracy) to identify the question type and automatically adjust the and weights.
Experimental Validation
Testing on the MLVU benchmark, the method proved its worth particularly when the "frame budget" was tight.
 The "Optimized" curve (the adaptive method) stays consistently above uniform sampling and the previous SOTA, AKS.
The "Optimized" curve (the adaptive method) stays consistently above uniform sampling and the previous SOTA, AKS.
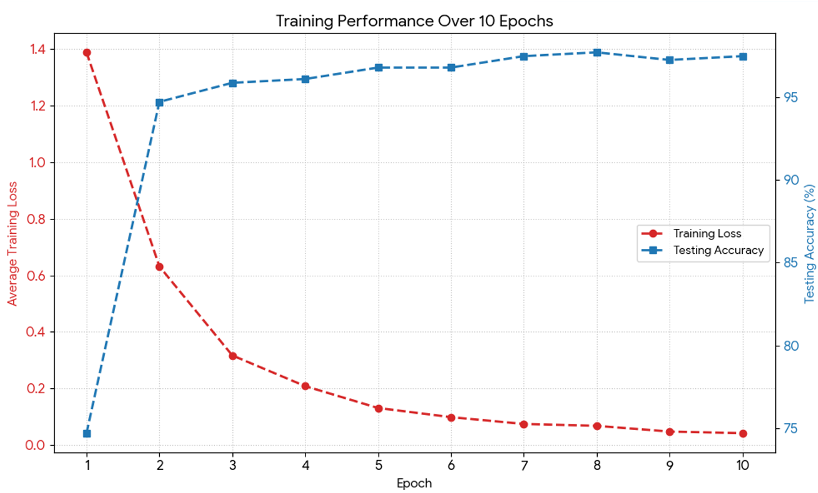
The training of the classifier is remarkably efficient, stabilizing in fewer than 10 epochs, proving that the intent behind a video query is easily extractable from text alone.
Deep Insight & Conclusion
This paper shifts the focus from "scaling the context window" to "smartly curating the context." By providing a theoretical framework (submodularity) for frame selection, the authors offer a more robust solution than empirical heuristics.
Takeaway: Future VLM pipelines should not treat visual inputs as static sequences. Instead, the input pipeline should be a dynamic "search and cover" mission dictated by the user's query.
Limitations: The current framework relies on precomputed embeddings for the candidate pool (capped at 1000 frames). For infinitely streaming video or ultra-long security footage, further hierarchical compression or sliding-window submodular optimization might be required.