本文提出了 Adaptive Greedy Frame Selection,一种针对长视频理解的即插即用型帧选择方法。通过在固定预算下联合优化查询相关性和语义代表性,并在 MLVU 榜单上超越了均匀采样和 AKS 等强基线,显著提升了大型视觉语言模型(VLM)的处理效率。
TL;DR
在长视频理解中,如何用最少的帧传递最关键的信息?普渡大学的研究者提出了一种自适应贪婪帧选择方法。它不仅能够智能调配查询相关性(Relevance)与语义覆盖度(Coverage),还能根据问题的类型(如找细节还是总结中心思想)自动切换筛选逻辑。实验证明,该方法在 MLVU 榜单上显著优于传统的均匀采样和最新的 SOTA 采样算法。
背景定位:不仅仅是“抽帧”那么简单
随着大视觉语言模型(VLMs)的发展,处理数十分钟甚至数小时的视频成为可能。然而,计算资源的限制(VRAM 和 Context Window)迫使我们必须进行Token Reduction(Token 减枝)。
目前的策略主要存在两个痛点:
- 冗余坍塌 (Redundancy Collapse):如果只看相关性,系统会选出一堆长得几乎一样的关键帧,白白浪费了 Token 位。
- 覆盖坍塌 (Coverage Collapse):如果只看多样性,系统为了“撒大网”可能会漏掉虽然局部但决定性的瞬间(Decisive Moments)。
核心直觉:亚模性(Submodularity)的优雅应用
作者认为,帧选择不应该是简单的 Top-K 排序,而是一个集合优化问题。他们设计了一个目标函数 :
- (Relevance):利用 SigLIP 嵌入,确保选出的帧跟用户的问题对得上。
- (Coverage):利用 DINOv2 嵌入,通过 Facility-Location 算法确保选出的帧能代表整个视频的语义分布。
最精妙的地方在于,这个函数是**单调且亚模(Monotone Submodular)**的。在数学上,这意味着“边际回报递减”。这使得我们可以通过简单的贪婪算法(Greedy Algorithm)获得至少 的最优解保证。
 图 1:算法通过 SigLIP 和 DINOv2 双空间嵌入,构建候选池并进行贪婪筛选。
图 1:算法通过 SigLIP 和 DINOv2 双空间嵌入,构建候选池并进行贪婪筛选。
方法论:问题感知的智能路由
并不是所有问题都需要同样的筛选逻辑。
- 总结类问题:需要更高的 Coverage(覆盖度),看遍全片才能总结。
- 寻物类问题 (Needle-in-a-haystack):需要更高的 Relevance(相关性),盯着那一秒钟看最重要。
为此,作者训练了一个轻量级的文本分类器(准确率达 97.7%),将问题自动分发到四种策略:纯相关性、纯覆盖度、相关性导向、覆盖度导向。
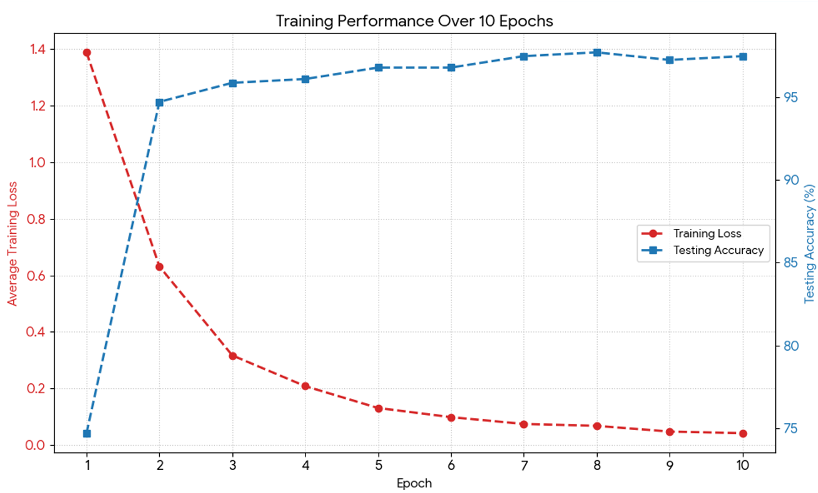 图 2:问题分类器的训练曲线与混淆矩阵,显示了极高的分类准确性。
图 2:问题分类器的训练曲线与混淆矩阵,显示了极高的分类准确性。
实验结果:用更少的帧,干更漂亮的活
在 MLVU 基准测试中,研究者对比了 Uniform Sampling(均匀采样)和 AKS (CVPR 2025)。
核心发现:
- 低预算优势:在仅使用 10-20 帧的情况下,该方法性能提升最显著,这意味着它能极大地压缩推理成本而不损失精度。
- 始终领先:随着帧数增加,该方法的性能曲线(下图深蓝/绿色线)始终压制基线模型。
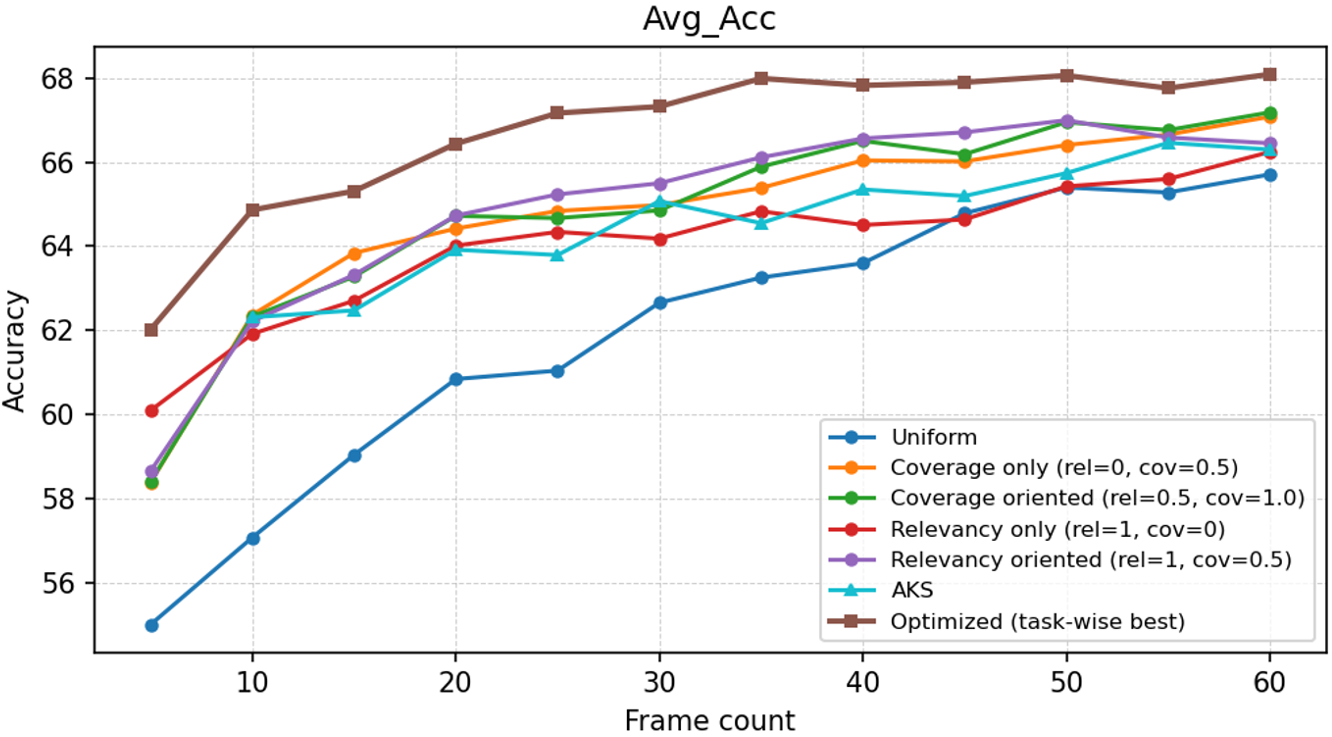 图 3:不同帧预算下的准确率对比,显示了自适应策略(Optimized)的统治力。
图 3:不同帧预算下的准确率对比,显示了自适应策略(Optimized)的统治力。
总结与启示
这篇论文告诉我们,解决长视频理解不一定非得堆算力或改模型架构,在数据入口处进行“高质量的质量把控”可能是性价比更高的方式。通过将数学上的亚模优化与 NLP 领域的问题分类相结合,Adaptive Greedy Frame Selection 为智能 Token 压缩提供了一个极具吸引力的范式。
局限性:目前该方法依赖于预计算的特征池(1 FPS),对于实时性要求极高的场景(如实时监控报警)可能仍有待优化。
Takeaway:未来的 VLM 视频应用中,一个“懂问题”的采样器可能比一个更大的模型更管用。