AgentFactory is a self-evolving framework that builds LLM-based agents by decomposing complex tasks into executable Python subagents. Unlike previous methods that store experiences as textual prompts, AgentFactory accumulates a library of reusable code modules that are continuously refined through execution feedback, achieving SOTA efficiency in task re-execution.
TL;DR
AgentFactory is a paradigm shift in agent autonomy. Instead of just "remembering" what it did via text logs, it writes, saves, and refines its own Python tools (subagents). This creates a library of robust, reusable, and portable capabilities that allow the agent to solve similar tasks in the future with 60%+ higher efficiency.
Background: Beyond Verbal Reflection
Most current LLM agents are "forgetful." Even those with "self-evolution" capabilities (like Reflexion) usually store their lessons as text prompts. While useful for high-level reasoning, text prompts are fragile for complex, multi-step procedures like "booking a meeting via Playwright" or "scraping specific data."
AgentFactory treats agent capabilities as software engineering artifacts. If an agent solves a problem once, it shouldn't just talk about it; it should ship a working, documented Python module that can be called by itself or other agents later.
Methodology: The Three-Phase Lifecycle
The core of AgentFactory lies in its ability to transform raw task requirements into a permanent library of skills. It operates in three distinct phases:
1. Phase 1: Install (From Scratch to Code)
When faced with a novel task, the Meta-Agent decomposes it into sub-tasks. It doesn't just execute them; it generates a specialized Python script for each. These are saved in a "Subagent Pool" with a SKILL.md file for documentation.
2. Phase 2: Self-Evolve (The Feedback Loop)
This is where the "growth" happens. If a saved subagent fails or encounters an edge case (e.g., a website layout changed), the Meta-Agent analyzes the error logs and rewrites the subagent's code. It moves from hardcoded fallbacks to robust logic (like switching from string parsing to Regex), making the subagent stronger over time.
3. Phase 3: Deploy (Portability)
Because the subagents are "Pure Python," they are framework-agnostic. You can train an agent in AgentFactory and then "export" its skills to Claude Code or LangChain simply by letting the new system read the generated documentation and execute the scripts.
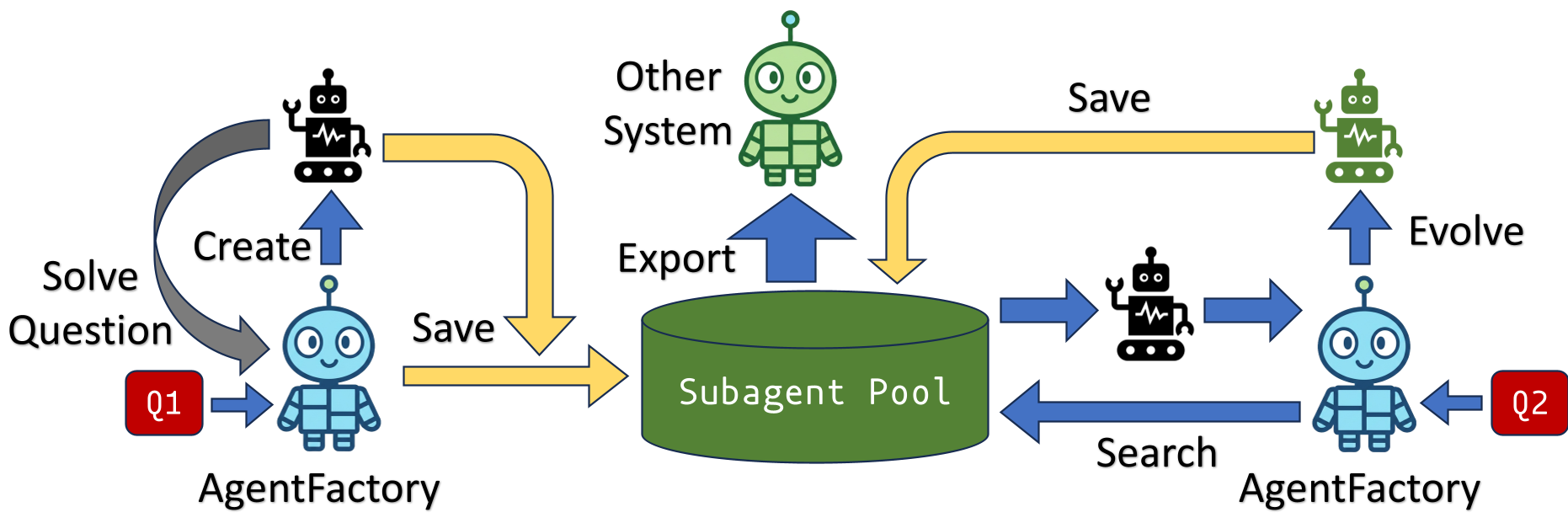 Figure 1: The AgentFactory pipeline showing how Q1 (new task) creates new code, while Q2 (similar task) evolves existing code.
Figure 1: The AgentFactory pipeline showing how Q1 (new task) creates new code, while Q2 (similar task) evolves existing code.
Experiments: Measuring Efficiency
The researchers tested AgentFactory against standard ReAct and "Textual Experience" baselines.
- The Batch Test: They created two batches of tasks ( and ). tasks were similar in structure to but with different details.
- Performance: Using Claude Opus 4.6, AgentFactory reduced the "Orchestration Tokens" (the effort the brain has to spend) from 8298 tokens (ReAct) to just 2971 tokens on the second batch.
 Table 1: Token consumption comparison across different models and task settings.
Table 1: Token consumption comparison across different models and task settings.
Cross-System Reuse
One of the most impressive demonstrations showed an agent in AgentFactory creating a "QQ Music Player" tool, which was then successfully utilized by Claude Code—a completely different agent system—just by reading the automatically generated SKILL.md.
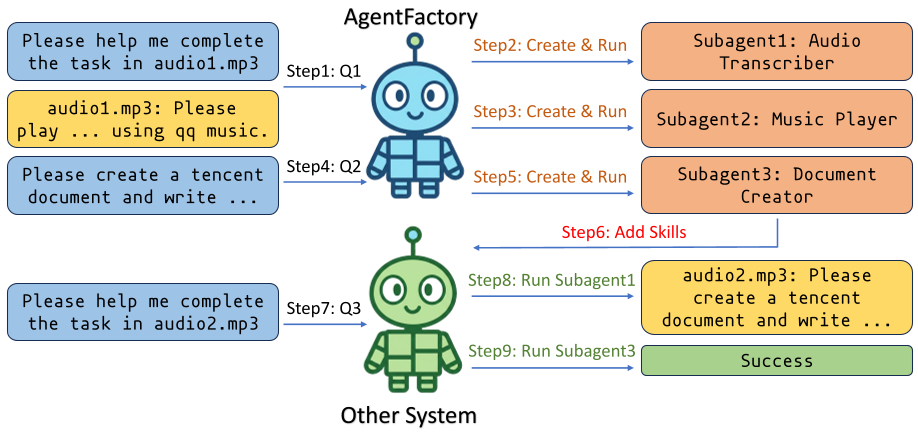 Figure 2: Trajectory showing how subagents created in one system are successfully deployed and reused in another.
Figure 2: Trajectory showing how subagents created in one system are successfully deployed and reused in another.
Critical Insights & Future Outlook
The genius of AgentFactory is its alignment with the Agent Skills open standard. It treats the development of AI agents like the development of a software library.
Key Takeaways:
- Inductive Bias: By forcing the agent to output Python code rather than just text, the framework introduces a strong inductive bias toward structured, logical, and debuggable problem-solving.
- Scalability: As the library grows, the cost of solving new tasks approaches a constant "lookup and call" cost rather than the "reason and act" cost of 0-shot prompting.
- Limitation: Currently, the framework is heavily focused on web and shell-based tasks. The authors suggest that integrating Vision-Language Models (VLMs) will be necessary to expand this self-evolution into complex Graphical User Interfaces (GUIs).
In conclusion, AgentFactory moves us closer to a future where AI doesn't just represent knowledge—it accumulates executable wisdom.