BLF (Bayesian Linguistic Forecaster) is an agentic system designed for binary forecasting that achieves SOTA performance on the ForecastBench benchmark. It utilizes an iterative tool-use loop to maintain a semi-structured linguistic belief state, combined with hierarchical multi-trial aggregation and calibration techniques, matching the performance of human superforecasters.
In the realm of geopolitical and financial forecasting, the difference between a 0.5 and a 0.7 probability can mean millions of dollars or shifts in international policy. While Large Language Models (LLMs) have shown promise, they often struggle with the "messiness" of real-world evidence. Enter BLF (Bayesian Linguistic Forecaster), a new agentic framework that doesn't just read the news—it maintains a rigorous, evolving internal "belief state" that mimics the cognitive process of human superforecasters.
TL;DR
BLF is an agentic system for binary forecasting that has claimed the top spot on the ForecastBench leaderboard. By treating forecasting as a sequential Bayesian update process and using a semi-structured "Linguistic Belief State," BLF effectively matches the performance of human superforecasters (ABI 71.0 vs 70.9). Its success stems from a combination of iterative web search, multi-trial aggregation, and sophisticated hierarchical calibration.
The Problem: The "Context Dump" Limitation
Most current AI forecasters follow a simple pattern: search the web, dump the snippets into a prompt, and ask for a probability. This faces three fatal flaws:
- Context Saturation: As more evidence is gathered, the signal-to-noise ratio drops, and models lose track of crucial contradictions.
- Single-Shot Bias: LLM reasoning is stochastic; a single "bad" search result can derail an entire prediction.
- Miscalibration: LLMs are notoriously overconfident, especially when the "base rate" (the historical frequency of an event) is near 0% or 100%.
Methodology: Thinking in Probabilities
The heart of BLF is the Linguistic Belief State. Instead of just keeping a chat history, the agent maintains a JSON object that tracks:
- Current Probability: A numerical estimate (e.g., 0.65).
- Confidence Level: Low, Medium, or High.
- Evidence Summaries: Prose-based arguments for and against the outcome.
- Open Questions: What the agent needs to find next.
The Agent Loop
At each step, the LLM decides whether to search the web, fetch time-series data (from FRED or Yahoo Finance), or "submit." Crucially, every time it sees new info, it updates its "belief" before choosing the next action.
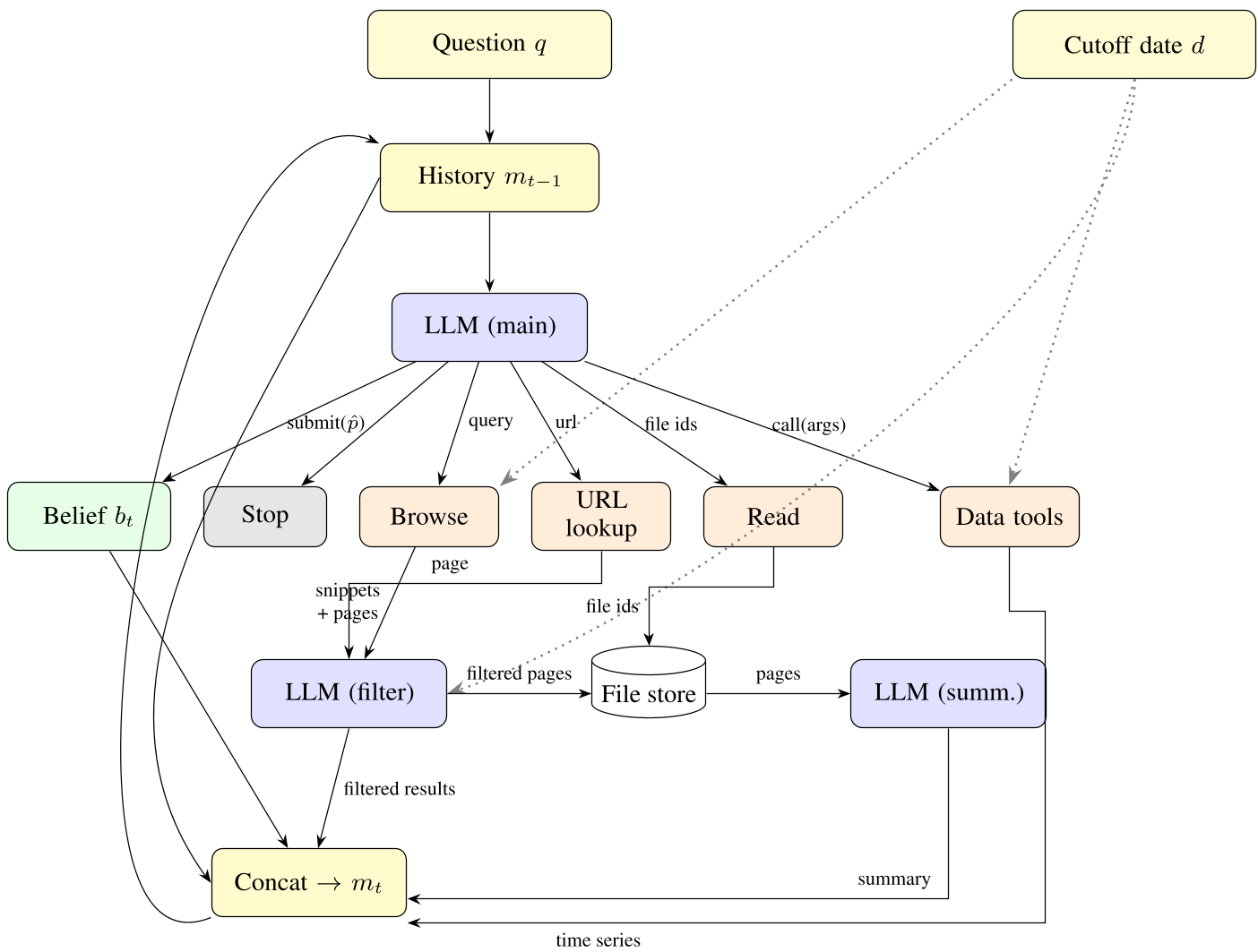 Figure 1: The BLF agent loop. Note how the "Updated Belief" is a core output of every single step.
Figure 1: The BLF agent loop. Note how the "Updated Belief" is a core output of every single step.
Turning Noise into Signal: Aggregation and Calibration
To combat LLM variance, BLF runs 5 independent trials per question. It doesn't just average the numbers; it uses Logit-Space Mean Aggregation.
For calibration, the authors use Hierarchical Platt Scaling. Traditional calibration often "shrinks" extreme predictions toward 0.5. However, if you're predicting whether a vaccine for Sepsis will exist next month, a 0% prediction is actually well-calibrated. BLF’s hierarchical approach learns per-source offsets, allowing it to stay bold on easy questions and cautious on hard ones.
Experimental Results: Beating the Crowd
On 400 backtesting questions from ForecastBench, BLF didn't just beat other AI models—it was the only system to significantly outperform the "Crowd" (market prices) on market-based questions.
Key Ablation Insights:
What actually makes BLF work? The researchers broke it down:
- Belief State: Removing the structured belief state dropped the Brier Index (BI) by 3.0.
- Search: Losing web access dropped BI by 4.6.
- Sequential vs. Batch: Doing everything in one shot instead of iteratively dropped BI by 3.8.
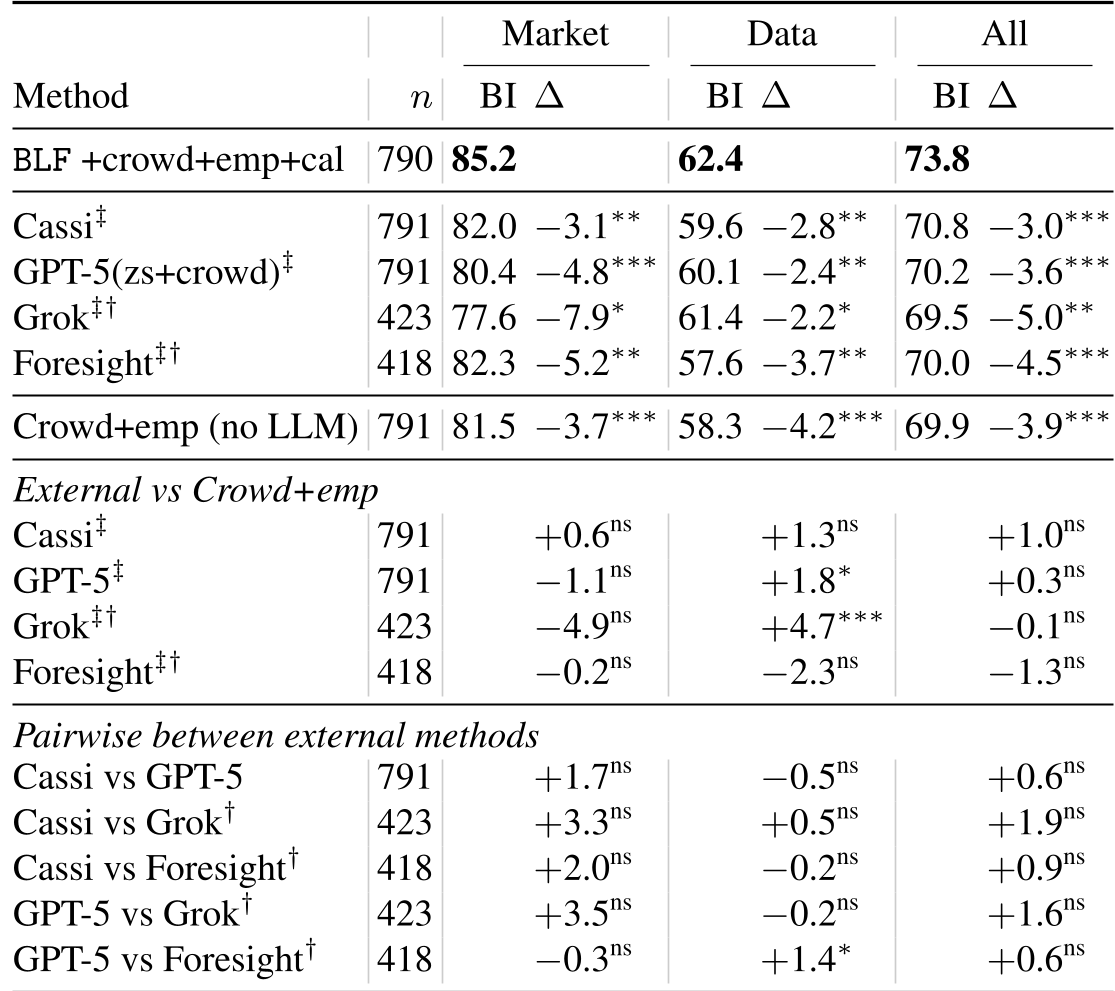 Table 1: BLF (top row) consistently outperforms specialized models like Cassi and frontier models like GPT-5.
Table 1: BLF (top row) consistently outperforms specialized models like Cassi and frontier models like GPT-5.
A Glimpse into the "Thinking" Process
Below is a trace of the agent's belief evolution. Note how different trials (paths of inquiry) lead to different conclusions, which are eventually averaged out for a stable prediction.
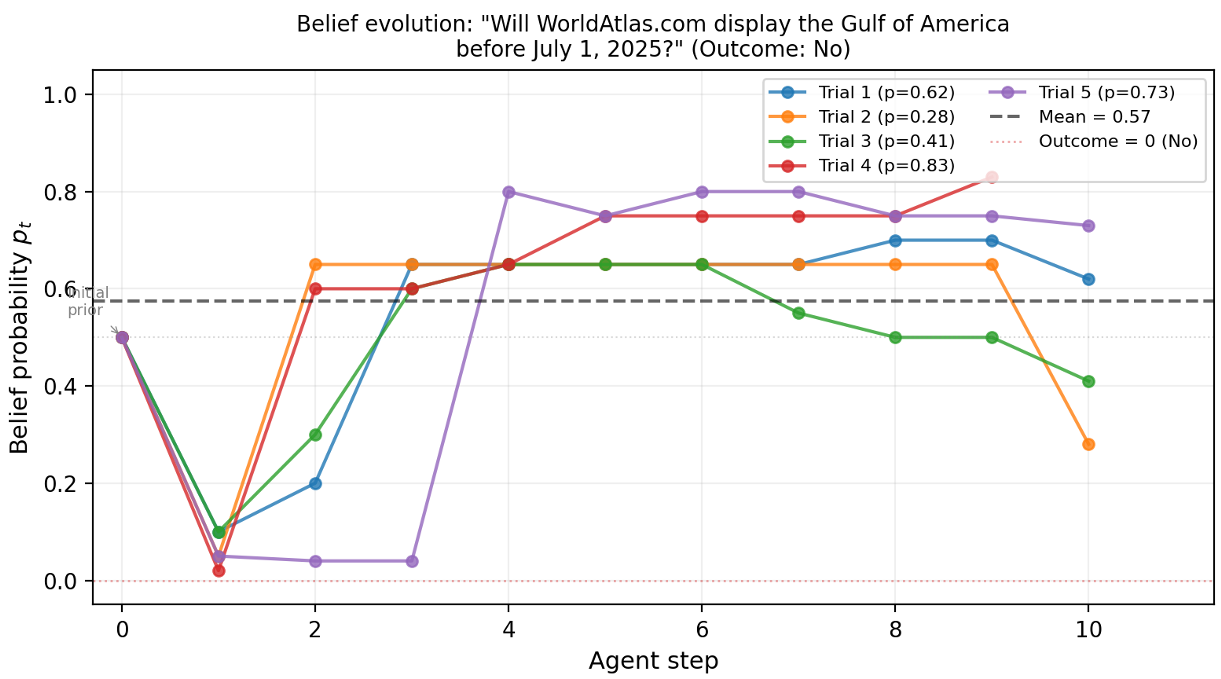 Figure 2: Probability traces across 5 trials. The divergence illustrates the "stochastic" nature of web search, which BLF mitigates through aggregation.
Figure 2: Probability traces across 5 trials. The divergence illustrates the "stochastic" nature of web search, which BLF mitigates through aggregation.
Conclusion & Future Outlook
BLF demonstrates that Inductive Bias (in the form of agentic structure) is more powerful than just scaling the size of the model. By forcing the LLM to behave like a Bayesian reasoner—maintaining a state, citing evidence, and iterating—we can close the gap between AI and human superforecasters.
The Takeaway: For enterprises building forecasting tools, "raw" LLM outputs are insufficient. Success lies in building a "harness" that enforces structured belief updates and rigorous statistical calibration.
Disclaimer: This post is based on the paper "Agentic Forecasting using Sequential Bayesian Updating of Linguistic Beliefs" by Murphy et al. (2026).