The paper introduces "Just Furnish Context" (JFC), a proof-of-concept framework that enables autonomous AI agents (specifically Claude Code) to execute end-to-end Experimental High Energy Physics (HEP) analyses. It successfully automates complex pipelines—from literature retrieval and event selection to statistical inference and paper drafting—reproducing results from ALEPH, DELPHI, and CMS open data.
Executive Summary
TL;DR: MIT and CERN researchers have unveiled JFC (Just Furnish Context), a multi-agent AI framework capable of autonomously planning and executing full-scale high-energy physics (HEP) analyses. Using the Claude Code engine, the system retrieved past literature, wrote analysis code, performed complex statistical fits, and drafted publication-quality reports—all while maintaining professional "blinding" protocols.
Background: This work represents a shift from "AI-assisted coding" to "autonomous scientific execution." In the academic landscape, this stands as a pioneering demonstration of LLMs replacing the years-long manual implementation phases of doctoral-level physics research.
Problem & Motivation: The Implementation Bottleneck
In experimental physics, a graduate student might spend 80% of their time writing thousands of lines of code to handle data processing and systematic uncertainties. Most of this code is structurally identical to existing analyses but lacks updated documentation.
The authors argue that the community underestimates current AI. While prior work used AI as a simple autocomplete or for narrow tasks, the JFC framework aims to solve the "context exhaustion" and "planning" problems that usually cause LLMs to fail during complex, multi-week scientific workflows.
Methodology: The JFC Multi-Agent Architecture
JFC operates via a division of labor. Instead of one massive prompt, it uses a tiered system:
- Executor Agents: Specialized roles like the
systematics-fitterorlead-analyst. - Reviewer Agents: Independent critics (e.g.,
physics-reviewer) who classify issues as Category A (blocking), B (important), or C (minor). - Adjudication Agents: The
arbitersynthesizes reviewer feedback to decide if a phase passes or requires iteration.
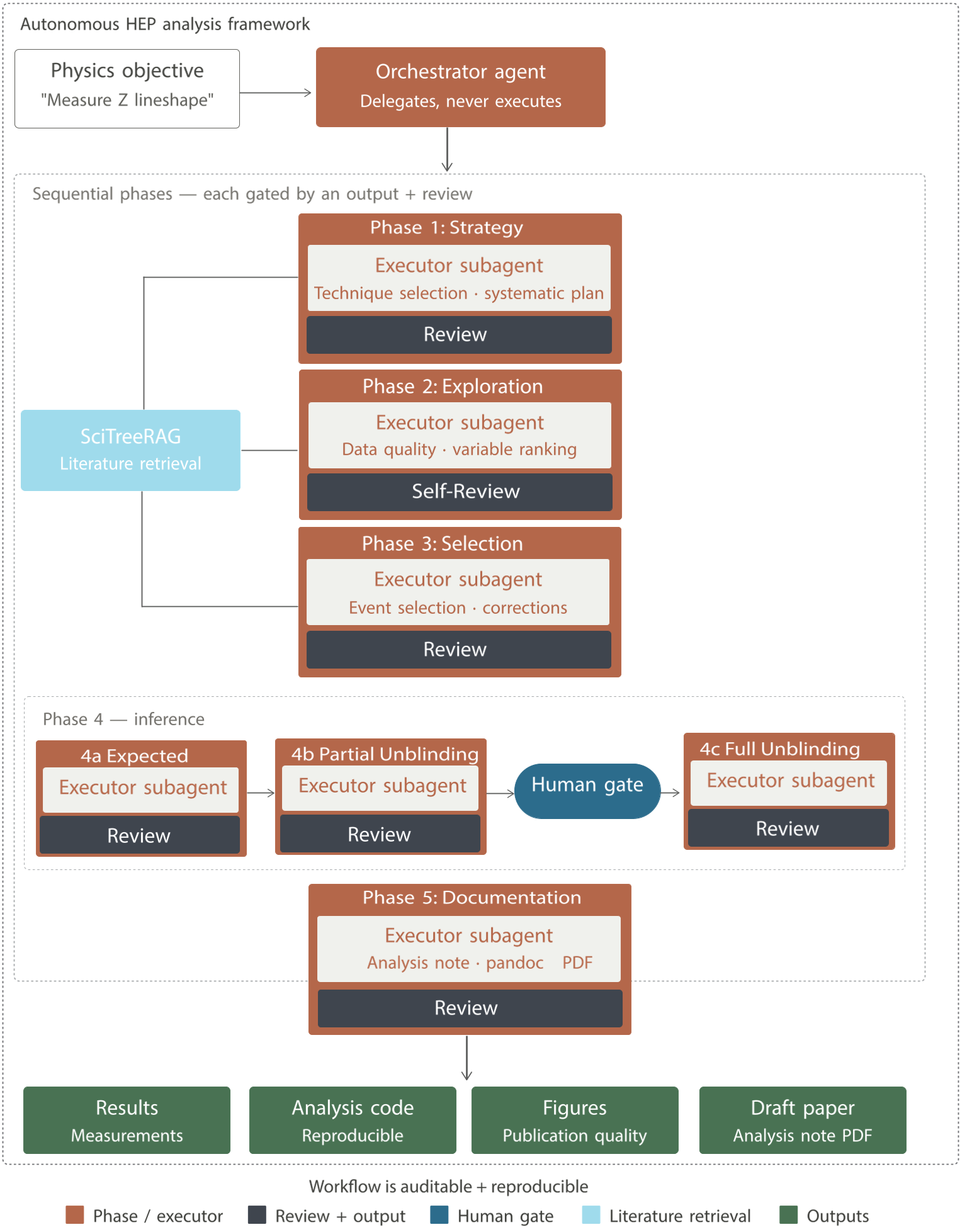 Figure 1: The JFC workflow. High-level objectives are passed to the orchestrator, which cycles through planning, literature retrieval via SciTreeRAG, and multi-agent review.
Figure 1: The JFC workflow. High-level objectives are passed to the orchestrator, which cycles through planning, literature retrieval via SciTreeRAG, and multi-agent review.
The Formal Unblinding Protocol
Crucially, the framework respects the Blinding Protocol. In HEP, looking at the "signal region" too early introduces bias. JFC enforces a "Human Gate": the AI can work on 10% of the data, produce a draft, and run fit diagnostics, but it is programmatically barred from the full dataset until a human expert grants approval.
Experiments & Results: Reproducing 30 Years of Physics
The authors tested JFC on archived data from the ALEPH and DELPHI experiments (LEP collider) and the CMS experiment (LHC).
| Analysis | Data Source | Time Taken | Key Result | | :--- | :--- | :--- | :--- | | Z Boson Lineshape | ALEPH | 3h 10m | Mass $M_Z = 91.179 \pm 0.004$ GeV | | Neutrino Generations | DELPHI | 5h 15m | $N_ u = 2.986 \pm 0.078$ (SM=3) | | Higgs Signal Strength | CMS | 6h 30m | $\hat{\mu} = -5.67 \pm 4.81$ (Success: methodology validated) |
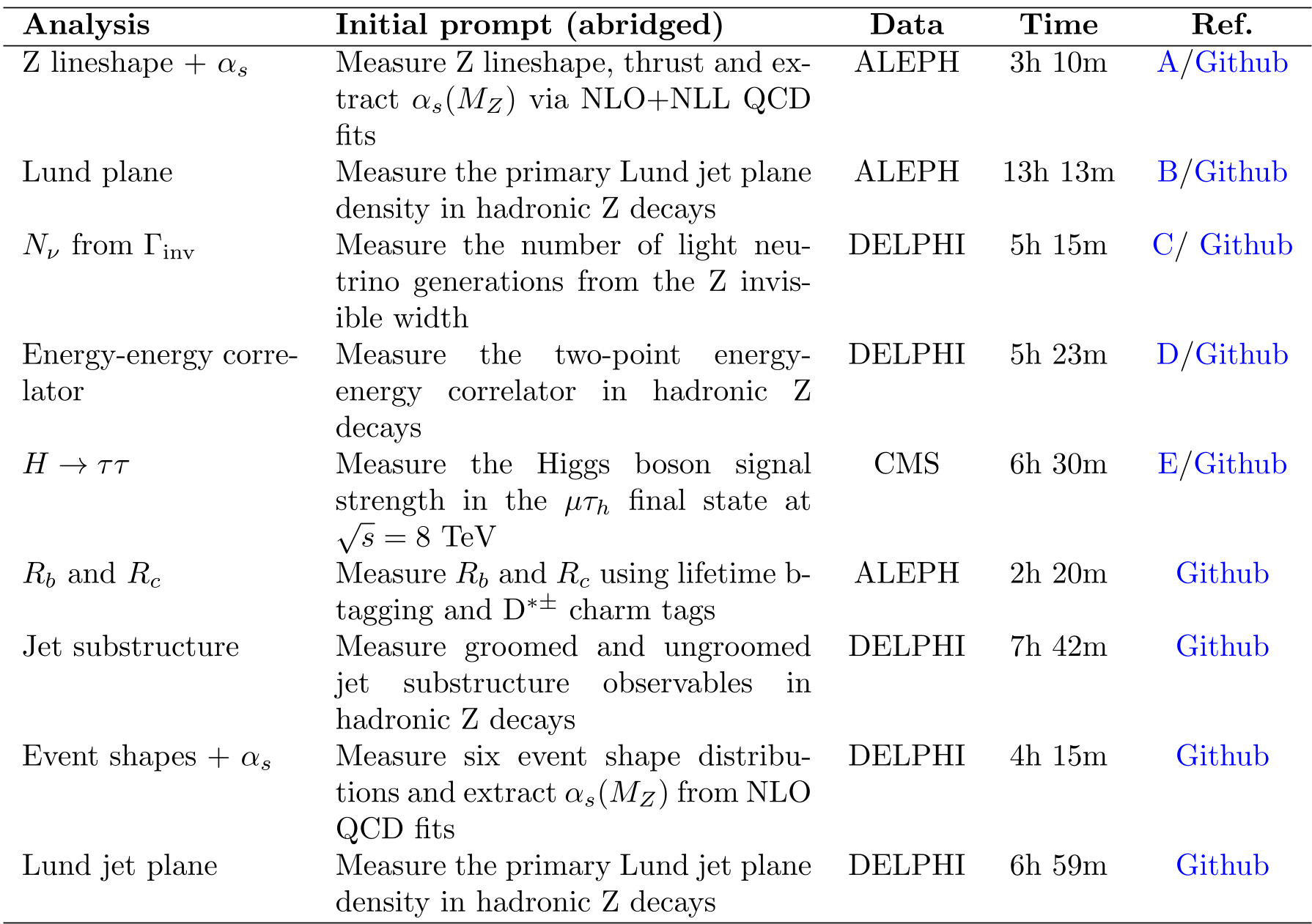 Table 1: Summary of analyses successfully performed by JFC. Note the speed: measurements that traditionally took months were finished in hours.
Table 1: Summary of analyses successfully performed by JFC. Note the speed: measurements that traditionally took months were finished in hours.
Quality Analysis
The AI-produced measurements for the Z boson mass and the number of neutrino generations were consistent with PDG (Particle Data Group) world averages. Interestingly, the AI demonstrated "self-awareness"—identifying its own limitations, such as rank-deficient covariance matrices or insufficient theory inputs, in dedicated "Limitation" sections of its generated reports.
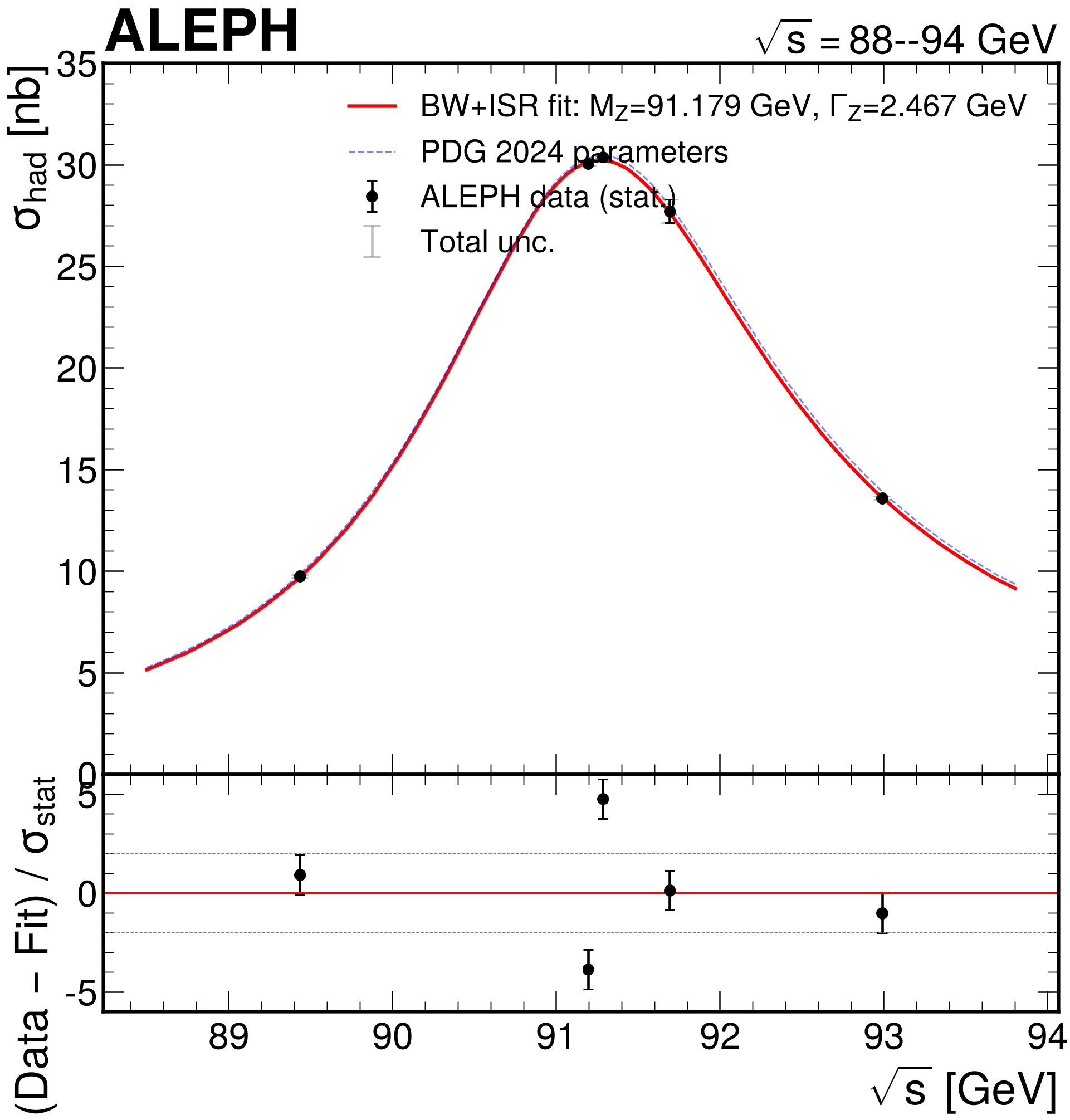 Figure 2: The AI-generated fit for the Z boson lineshape. Black markers represent transformed archived data; the red curve is the AI's Breit-Wigner fit.
Figure 2: The AI-generated fit for the Z boson lineshape. Black markers represent transformed archived data; the red curve is the AI's Breit-Wigner fit.
Critical Analysis & Conclusion
While the technical proficiency is high, the authors note several limitations:
- Subtle Physics Errors: The AI may miss rare systematic uncertainties that an expert with 20 years of experience would immediately spot.
- Novelty vs. Reproduction: The AI excels at reproducing known methods via RAG but struggles to invent entirely new reconstruction algorithms.
- Instruction Drift: In large context windows, the agent occasionally ignores style constraints (like LaTeX font sizes).
Future Outlook: The shift is inevitable. As implementation costs drop by orders of magnitude, the bottleneck moves from "coding bandwidth" to "intellectual bandwidth." The paper concludes by urging the HEP community to rewrite graduate curricula to focus on AI Literacy and Physical Intuition rather than C++ macros—freeing humans to focus on the "Why" while agents handle the "How."