本文提出了 AnomalyAgent,这是首个用于工业异常合成的智能体(Agent)框架。该方法通过工具增强的强化学习(Tool-Augmented RL),在 MVTec-AD 数据集上实现了 IS 2.10 和 IC-L 0.33 的 SOTA 异常合成效果,并显著提升了下游异常检测任务的准确率。
TL;DR
工业缺陷数据集的匮乏一直是制约 AI 上岗的“紧箍咒”。传统的零样本生成方法往往“一锤子买卖”,效果全看运气。上海交大等团队提出的 AnomalyAgent 首次将智能体(Agent)范式引入工业异常合成,通过多轮迭代反思、专业知识检索和强化学习优化,生成的缺陷样本不仅肉眼难辨真假,更在下游检测任务中刷出了 SOTA 成绩。
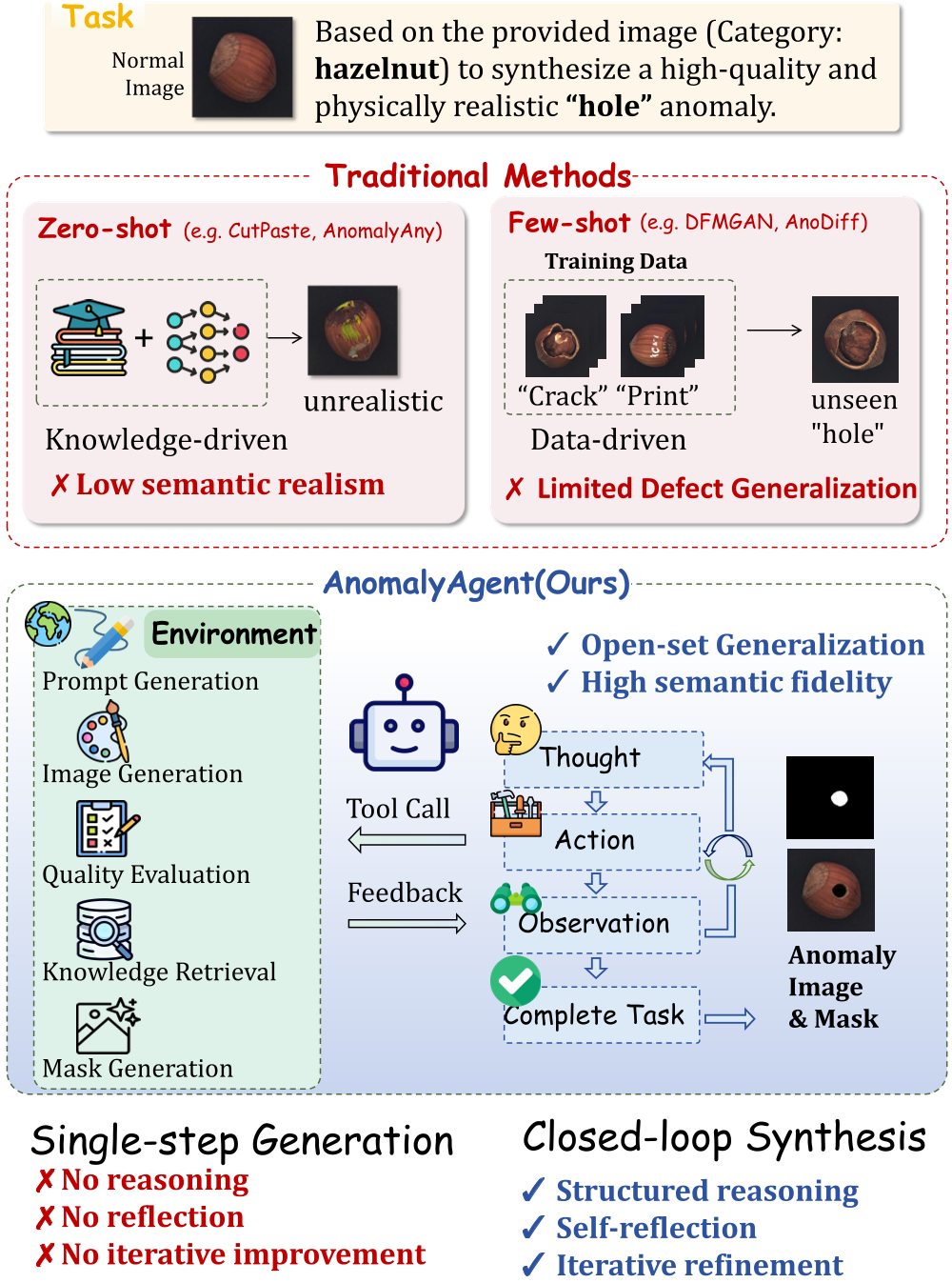
痛点深挖:为什么“一次生成”行不通?
在真实的工业场景(如 MVTec-AD 或 VisA)中,异常类型极其多样且微妙:一道划痕的深浅、一个孔洞的边缘纤维感,都直接决定了模型的判别能力。
- Prior Work 的局限:无论是 CutPaste 等启发式方法,还是基于 Diffusion 的零样本方法,大多是开环生成。模型生成结果后就结束了,无法感知生成的“孔洞”看起来是否太假,也无法根据物理逻辑去修正它。
- 研究直觉:正如 DeepSeek-R1 或 OpenAI o1 在逻辑推理上的突破,作者认为异常合成也需要“思考”。通过多次工具调用(查资料、看反馈、改方案),才能逼近真实工业物理特性。
核心方法:构建“感知-反思-行动”的闭环
1. 五大工具箱(Tools)
AnomalyAgent 并非直接出图,而是扮演“指挥官”,调度以下工具:
- PG & IG:负责从描述到画图的初稿生成。
- QE (Quality Evaluation):智能体扮演质检员,由于内置了 MLLM(如 Gemini Pro),它能指出:“这个划痕边缘太锋利,不符合金属疲劳特征。”
- KR (Knowledge Retrieval):当遇到不熟悉的领域,智能体会去检索外部知识库。例如,搜索“木材液体渗透的边缘特征”。
- MG:最后生成精准的像素级 Mask。
2. 两阶段进化
- SFT 阶段:利用真实异常数据构建“轨迹(Trajectories)”,让模型学会模仿人类专家的工作流程(思考 -> 调用工具 -> 总结)。
- RL 阶段 (GRPO):这是最关键的一步。通过组相对策略优化(GRPO),模型在多个生成路径中进行对比。
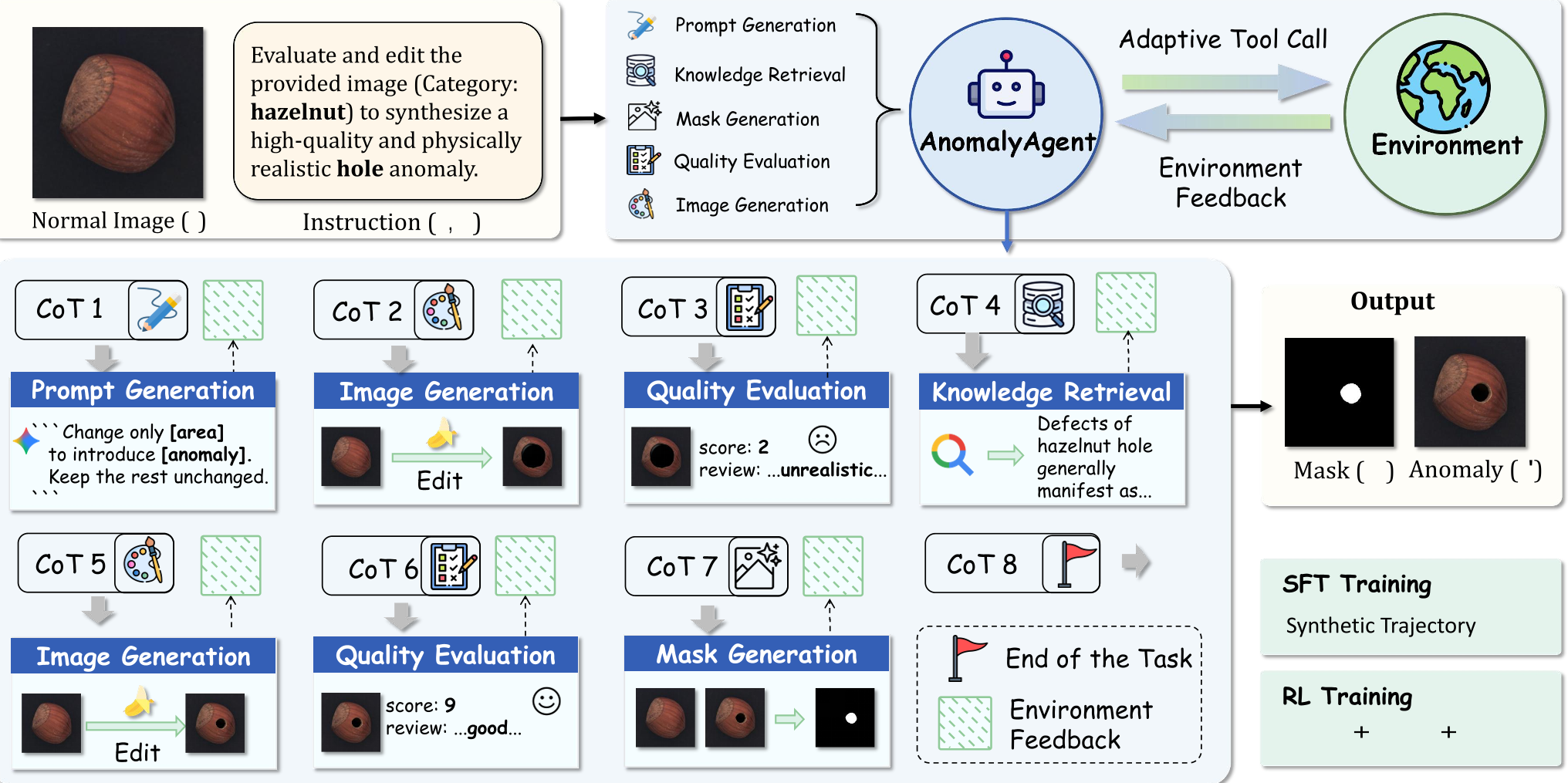
3. 三重奖励函数 (Reward Design)
为了练就火眼金睛,作者设计了精妙的奖励方案:
- 任务奖励 ():最终生成的图像真实吗?
- 反思奖励 ():第 N 轮生成的图像比第 N-1 轮有进步吗?
- 行为奖励 ():工具调用的顺序专业吗?(例如:不能先生成掩码再修改图片)。
实验战绩:全方位碾压
在 MVTec-AD 全类别测试中,AnomalyAgent 展现了恐怖的统治力:
- 合成质量:Inception Score (IS) 达到 2.10,显著优于传统的合成模型。
- 下游实测:将合成数据交给一个极其简单的 UNet 训练,在像素级定位上的 AP 达到了 74.2%,远超目前最强的零样本方法 AnoHybrid。
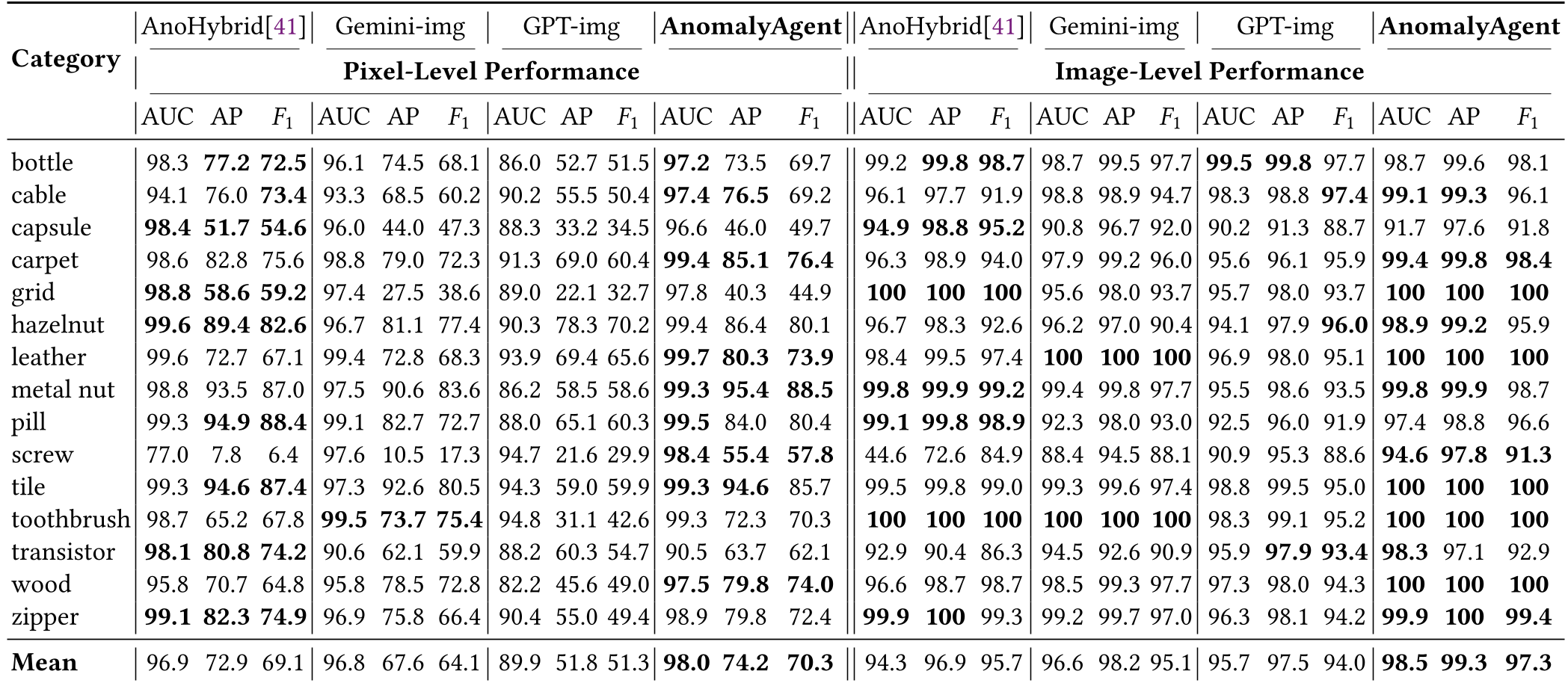
从可视化结果(Fig 5)可以看出,AnomalyAgent 生成的液体渗漏或孔洞,能很好地处理材质纹理交互(如木块上的液体吸收感),而传统方法生成的样本更像是“贴纸”。
深度洞察:为什么它比单纯的 GPT-4 出图更强?
一个有趣的发现是,即便直接让顶级的多模态生成模型(如 GPT-4, Gemini)直接出异常图,其效果也不如 AnomalyAgent。
- 逻辑在于控制:通用大模型缺乏对“工业缺陷路径”的针对性 RL 训练。AnomalyAgent 懂得在 QE 给出低分后,通过检索“毛细作用”等专业词汇去优化 Prompt,这种细粒度的提示词工程自动化才是其核心壁垒。
- 性价比:实验证明,虽然 AnomalyAgent 进行了多步推理,但因为“有效样本率”极高,合成每个“好样本”的平均时间和资金成本反而比普通模型更低。
总结与局限
Takeaway:AnomalyAgent 标志着数据合成从“随机抽奖”全面进入“精密工程”时代。通过 Agentic RL,我们第一次让模型学会了“如何像质检专家一样思考和修正物理缺陷”。
局限性:目前的推理链条仍依赖外部 API 调用(如 Google Search, Gemini),在纯离线工业环境下的轻量化部署仍是一个挑战。未来的研究可能会侧重于将这种 Agent 能力蒸馏(Distill)到单一的紧凑型本地模型中。