TraceR1 is a novel two-stage reinforcement learning framework that enables multimodal AI agents to perform anticipatory planning rather than just reactive execution. By forecasting short-horizon trajectories before acting, it achieves State-of-the-Art (SOTA) performance on benchmarks like OSWorld-Verified and GAIA, significantly outperforming reactive open-source baselines.
TL;DR
Most AI agents are "blind" to the future—they click based on what they see now without considering where they need to be five steps later. TraceR1 changes this by introducing a two-stage Reinforcement Learning (RL) framework that trains agents to forecast entire trajectories. By combining high-level foresight with grounded execution feedback, it elevates open-source models to a level of planning stability previously reserved for proprietary giants like GPT-4o and Claude 4.
Problem: The "Reactive" Bottleneck
In the world of GUI automation and tool-use, the biggest hurdle isn't perception; it's coherence. Traditional agents optimize for the next immediate token or action. While this works for simple tasks, it fails in "long-horizon" scenarios—like booking a complex multi-city flight—where a small mistake in step 2 causes a total collapse by step 10.
Existing methods fall into two traps:
- Model-free RL: Focuses on local correctness but lacks global vision.
- Model-based Planning: Extremely difficult to build "world models" for visually dense, ever-changing digital interfaces.
Methodology: Anticipatory Planning via TraceR1
The authors argue that an agent should act like a human: visualize a few steps ahead, then refine the immediate move based on reality.
Stage 1: Anticipatory Trajectory Optimization
Instead of just training the model to predict the next action , TraceR1 forces the model to predict a sequence . It uses Group Relative Policy Optimization (GRPO) with a trajectory-level reward that penalizes:
- Plan Deviations: How much the predicted future differs from a known "expert" path.
- Action Repetition: Loop-prevention logic to stop agents from clicking the same button endlessly.
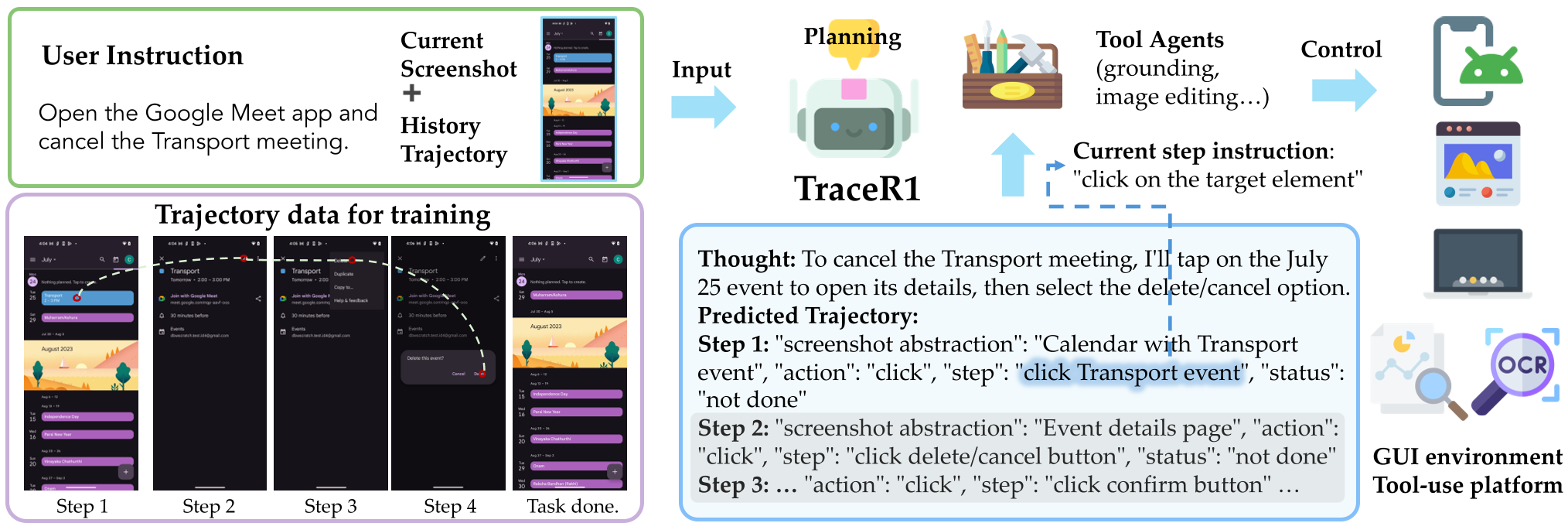 Figure 1: TraceR1 enables the planner to see several steps ahead while only executing the immediate next step.
Figure 1: TraceR1 enables the planner to see several steps ahead while only executing the immediate next step.
Stage 2: Grounded Reinforcement Fine-tuning
Foresight is useless if you can't hit the target. Stage 2 uses real feedback from "tool agents" (like a GUI executor). If the model predicts a click at , but that coordinate misses the button, the RL signal corrects the model's grounding. This ensures that the "vision" of the plan is matched by "precision" in execution.
Experiments: Surpassing the "Reactive" Baselines
TraceR1 was tested across 7 grueling benchmarks, including OSWorld (Desktop) and GAIA (General Assistant).
Key Results:
- OSWorld-Verified: Boosted Qwen3-VL-32B performance by over 15%, reaching 41.2% success—competing head-to-head with proprietary GPT-4.1-based systems.
- GAIA Benchmark: Achieved a massive +8.7 improvement in Answer Accuracy over the baseline Qwen3-VL-8B.
- Ablation Insight: Removing Stage 2 (Gingered Feedback) caused a 6% performance drop, proving that high-level planning must be anchored in physical/digital reality.
 Table 1: TraceR1 vs. Proprietary and Open-Source Models on AndroidWorld and OSWorld.
Table 1: TraceR1 vs. Proprietary and Open-Source Models on AndroidWorld and OSWorld.
Deep Insight: The "Prediction Horizon" Sweet Spot
One of the paper's most fascinating findings is the Horizon Trade-off. Training a model to look 5-10 steps ahead significantly improves success. However, if you force the model to predict 20+ steps, performance plummets. Why? Because the uncertainty of the far future accumulates too fast, creating "noisy" rewards that confuse the learning process.
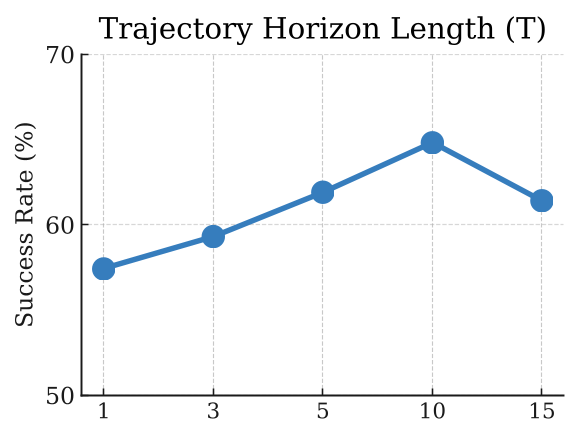 Figure 2: Analysis of the temporal discount factor and its impact on planning stability.
Figure 2: Analysis of the temporal discount factor and its impact on planning stability.
Conclusion
TraceR1 provides a scalable recipe for building smarter agents. By shifting the focus from "What do I do now?" to "Where is this sequence leading me?", it achieves a level of deliberate reasoning that moves us closer to truly autonomous digital assistants.
Future Work: The authors suggest moving toward "hierarchical planning," where agents can revise their long-term plans mid-execution if the environment changes unexpectedly—essentially adding a "self-correction" loop to the foresight mechanism.