本文提出了 AnyLift,一个利用 2D 扩散模型从互联网动态摄像头视频中重建 3D 人体运动和人模型交互(HOI)的统一框架。通过两阶段工作流,AnyLift 首次实现了在无 3D 标注情况下,从非受限单目视频中恢复具有全局一致性的世界坐标系 3D 运动。
TL;DR
斯坦福大学的研究团队推出了 AnyLift,这是一个能直接从 YouTube 或 TikTok 视频中提取高精度 3D 人体动作及人机交互(HOI)的 AI 框架。它解决了两个长期存在的痛点:对 3D 标注数据的依赖以及动态相机下的全局定位难题。即使视频里的人在翻跟头、镜头在乱晃,AnyLift 也能在世界坐标系下完美重现 3D 轨迹。
背景定位
传统的 3D 动捕(MoCap)虽然精准,但只能在实验室里抓取有限的动作。想要训练一个能翻滚、能搬运物体的智能体,我们需要海量的真实数据。AnyLift 属于 弱监督/无监督 3D 提升(3D Lifting) 领域,它不依赖昂贵的 3D 标签,而是通过 2D 扩散模型学习视频中的运动规律,属于该领域的最新 SOTA。
痛点深挖:为什么从视频中“抠” 3D 这么难?
- 分布外动作(OOD):MoCap 数据集中几乎没有高难度体操或极限武术。
- 相机抖动(Dynamic Camera):大多数算法假设相机不动,一旦镜头跟随人物移动,算法就会分不清是人在动还是相机在动,导致 3D 根轨迹(Root Trajectory)错乱。
- 视角缺失:互联网视频通常只有正面视角,缺乏侧面和背面信息,导致深度估计存在多义性。
核心方法论:AnyLift 的三板斧
1. 相机条件化的 2D 扩散模型
不同于传统的直接回归 3D 坐标,AnyLift 训练一个 2D 扩散模型来预测“如果换个视角看,这段动作长什么样”。它将 相机轨迹(Camera Trajectory) 和 极线(Epipolar Lines) 作为输入条件。
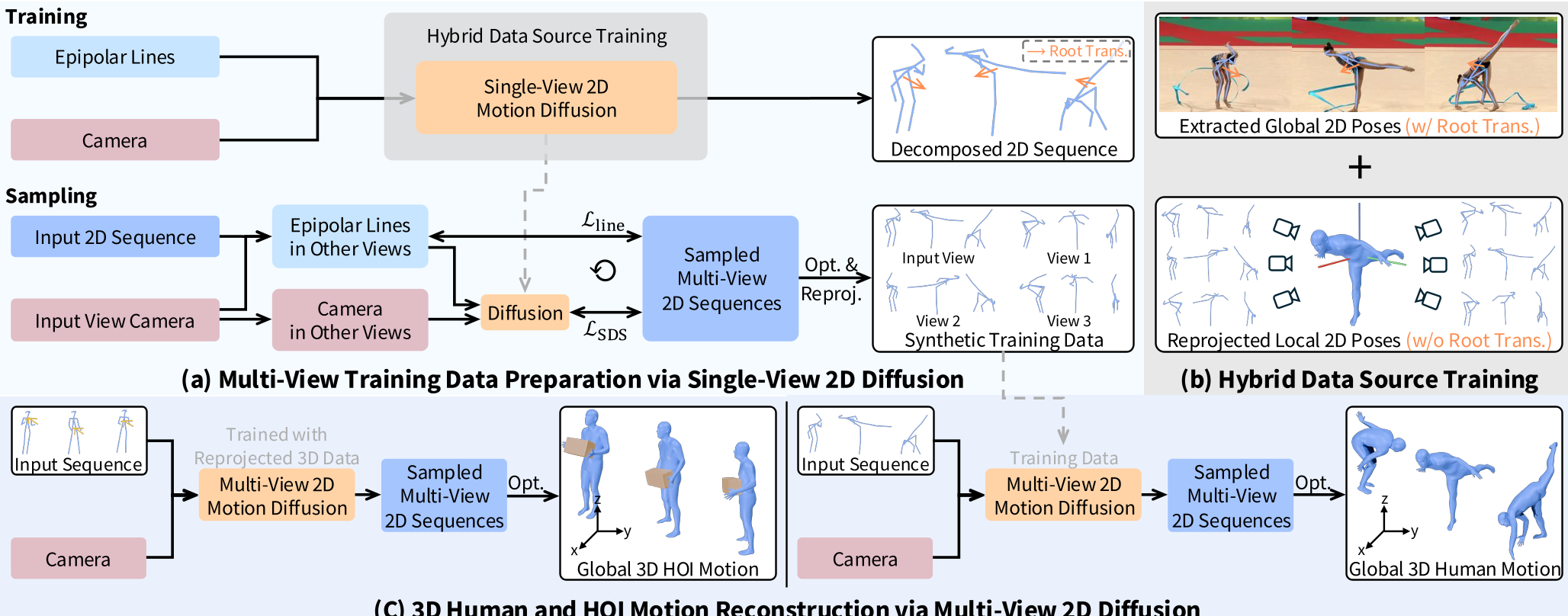 AnyLift 整体流程:从单目视频输入,到 2D 扩散合成多视角,最后优化出 3D 结果。
AnyLift 整体流程:从单目视频输入,到 2D 扩散合成多视角,最后优化出 3D 结果。
2. 混合数据源训练(Hybrid Training)
为了解决视角单一的问题,作者想了个奇招:
- 使用互联网视频提取的 2D 序列学习真实世界的全局移动。
- 使用成熟的单图姿态估计器(如 GVHMR)生成的、但旋转过视角的局部 2D 投影来学习动作细节。 这种“虚实结合”的方法极大地增强了模型对各种视角和极端动作的鲁棒性。
3. 人机互动(HOI)的统建模
AnyLift 不仅仅盯着人看,它还将物体(如椅子、盒子)的关键点与人体骨骼点拼接在一起进入扩散模型。这样模型就能学习到“人坐在椅子上”或“人搬起桌子”时的人物同步协调性,避免了物体与人在 3D 空间中各飞各的。
性能复盘:它是如何超越 SOTA 的?
在针对体操(Gymnastics)和武术(Martial Arts)的测试中,AnyLift 展现了压倒性优势。
- 根轨迹精度:在 AIST++ 数据集上,其根轨迹误差比 WHAM 等强基线方法降低了 60% 以上。
- 物理一致性:因为它学习的是全局运动,生成的动作几乎没有“滑步(Foot Sliding)”或“地面穿透”现象。
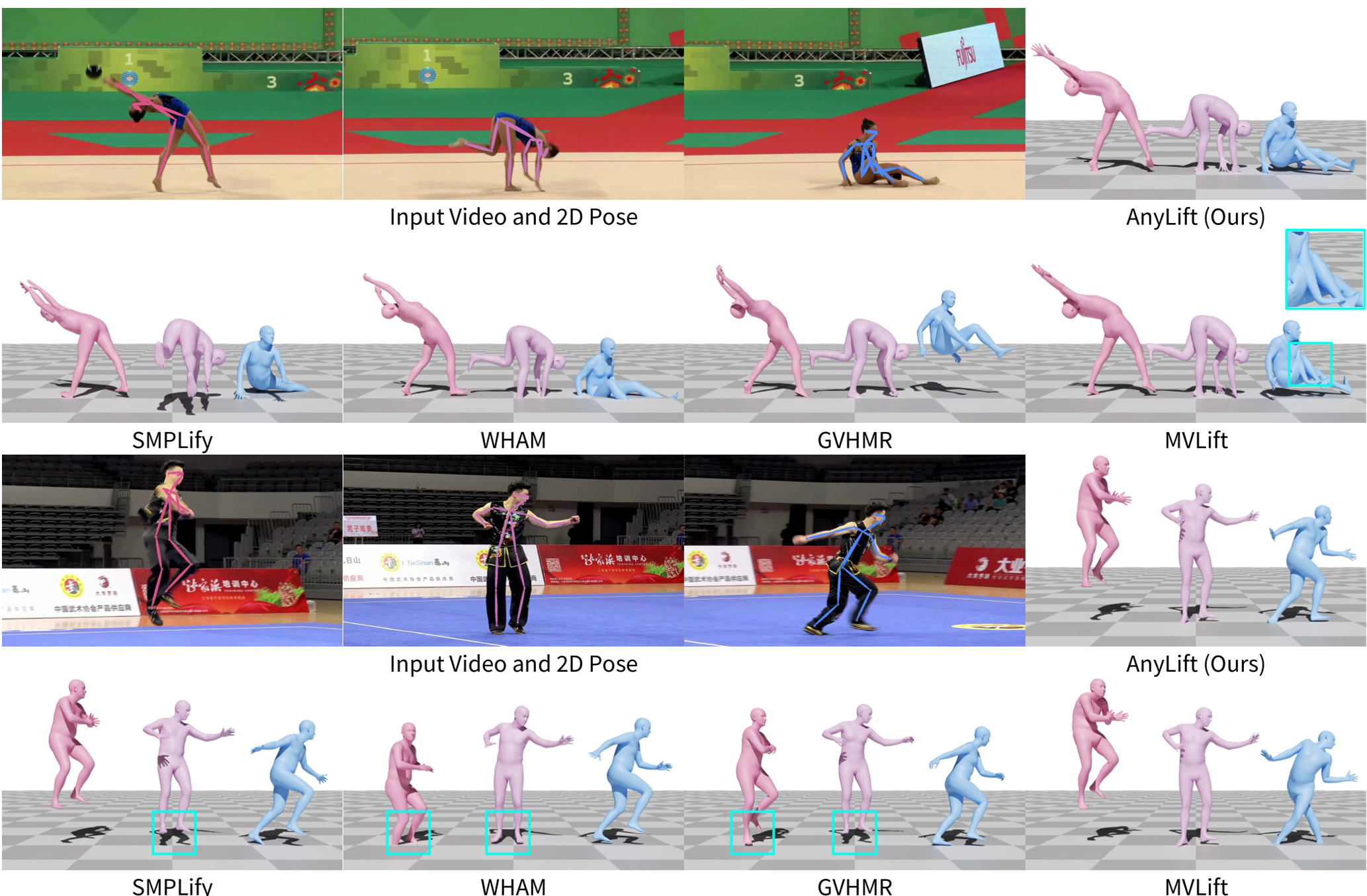 定性对比:可以看出 AnyLift (最右) 在复杂动作下生成的 3D 姿态最为稳健,避免了基线方法常见的身体扭曲。
定性对比:可以看出 AnyLift (最右) 在复杂动作下生成的 3D 姿态最为稳健,避免了基线方法常见的身体扭曲。
在 HOI 任务(如 BEHAVE 数据集)中,AnyLift 解决了复杂的物体遮挡和对称性歧义。
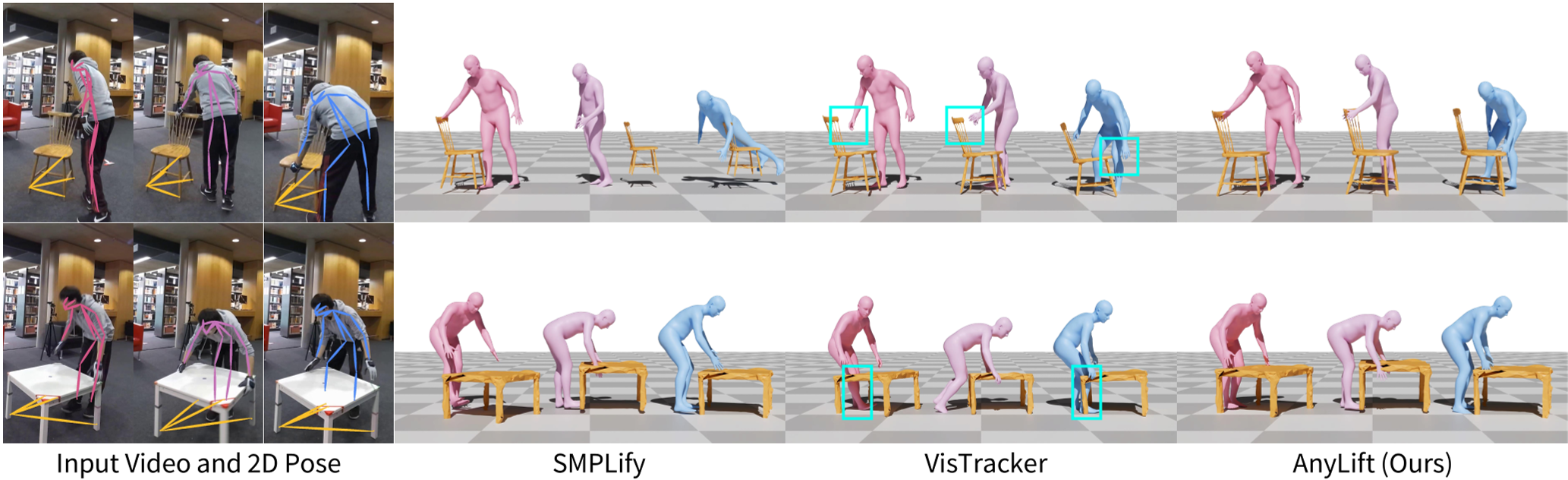 即便是在动态相机下,人与物体的接触点也处理得非常自然。
即便是在动态相机下,人与物体的接触点也处理得非常自然。
深度洞察与总结
AnyLift 的核心价值在于它打通了 “大规模视频数据 -> 高质量 3D 运动资产” 的链路。
局限性:
- 类别依赖:模型目前仍需针对体操、武术等特定类别进行微调以获得最佳效果。
- 预处理开销:两阶段的扩散与优化过程在处理超长视频时计算成本较高。
未来展望: 这项工作为构建“人体动作的大规模预训练模型”铺平了道路。想象一下,如果能将整个 YouTube 的人类活动转换为 3D 数据,我们将拥有一个全能的虚拟人训练场。这对于元宇宙、动作电影制作、乃至教机器人像人一样在现实世界中交互,都具有巨大的产业想象空间。