本文提出了 AR-CoPO,一种专为流式自回归(AR)视频生成模型设计的对齐框架。该方法结合了 Chunk 级别分叉机制与对比策略优化(CoPO),成功解决了少步一致性模型(CM)在 RLHF 过程中因采样确定性过高而难以进行 SDE 探索的痛点,实现了 SOTA 级别的视频生成质量与人类偏好对齐。
TL;DR
在视频生成领域,流式自回归(Streaming AR)模型正成为实现低延迟、长视频生成的关键。然而,由于这些模型通常经过蒸馏(Few-step Distillation),采样过程极度趋向确定性,导致传统的强化学习对齐方法(如基于 SDE 的 GRPO)因无法有效探索而失效。本文提出的 AR-CoPO 通过 Chunk 级别的对比策略优化与半在线训练,首次在保持生成稳定性的同时,显著提升了视频的审美、运动质量及文本一致性。
背景定位
目前主流的视频对齐方法(如 DanceGRPO, FlowGRPO)大多依赖于将决定性的 ODE 采样转变为随机的 SDE 过程,通过中间步骤的噪声注入进行探索。但在 Self-Forcing 等最先进的少步 AR 模型中,这种逻辑失效了——实验证明,这类模型的输出几乎完全由起始噪声决定。AR-CoPO 的出现,填补了“少步 AR 视频模型如何进行稳定 RLHF”的技术空白。
痛点深挖:为何传统 SDE-RL 玩不转?
作者通过对比实验发现了一个惊人的事实:在少步采样器中,改变中间步骤的噪声,输出几乎没变化;而改变初始块的噪声,视频内容才会显著改变(见下图)。
这意味着,如果传统的 RL 算法试图通过中间步探索,它得到的梯度几乎是零,训练自然会停滞。此外,视频序列的长程依赖使得直接进行全序列 RL 训练成本极高,且模型很难分清到底是哪个 Chunk 导致了最终的高分(Credit Assignment 问题)。
核心方法:AR-CoPO 的三大支柱
1. Chunk 级对齐与分叉机制 (Forking)
为了实现精准的信度分配,AR-CoPO 采用了“局部手术”方案:
- 随机锚点:在全视频序列中随机选一个 Chunk 作为“枢纽(Pivot)”。
- 分叉生成:仅在这个 Chunk 注入 组扰动噪声,生成多个候选样本。
- 后续锁定:枢纽块之后的生成使用相同的噪声。这样,最终奖励的差异完全可以归因于枢纽块的选择,从而实现了极佳的局部信度分配。
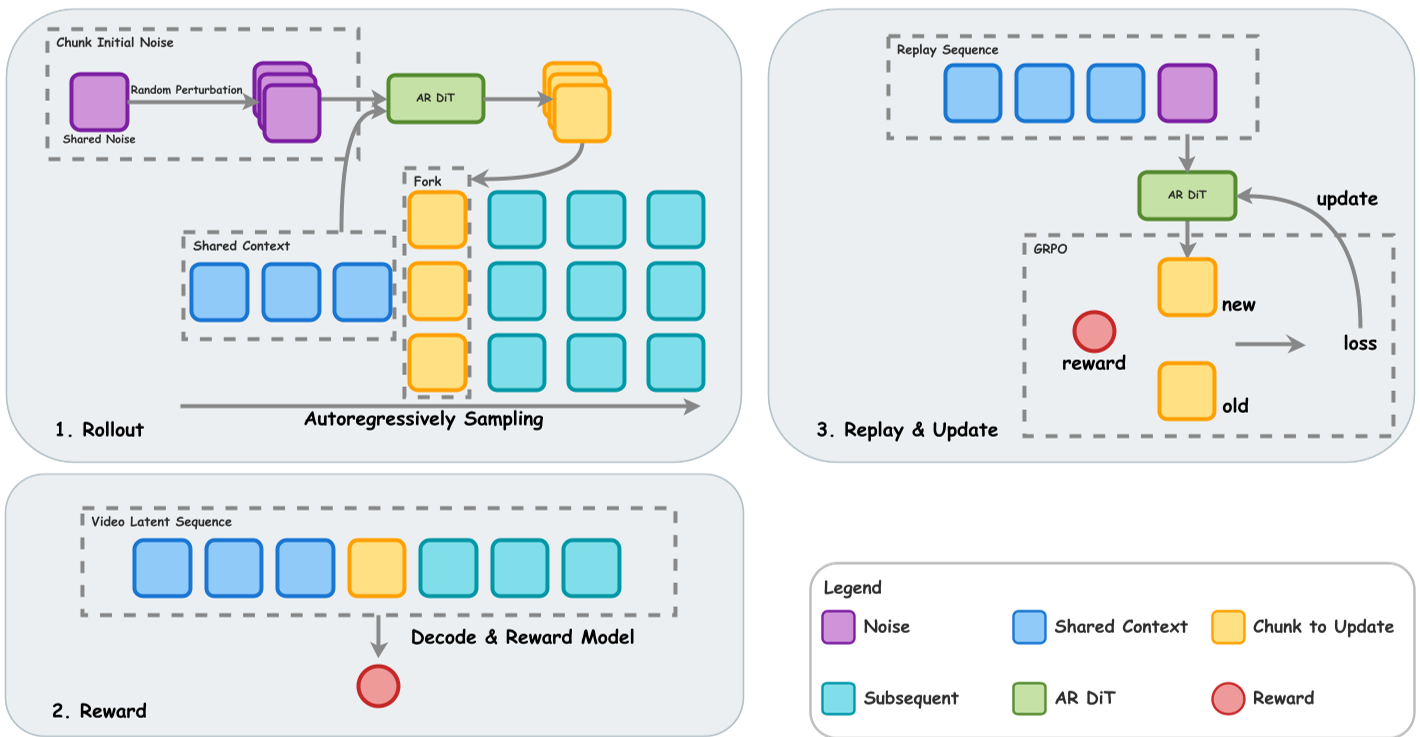
2. 针对一致性模型 (CM) 的对比优化
由于 CM 模型直接预测干净图像 ,AR-CoPO 不再计算中间隐变量的距离,而是直接在预测空间定义对比损失。这使得算法能够直接拉近当前策略输出与高奖励候选样本在语义层面的距离。
3. 半在线策略 (Semi-on-policy) 与 LoRA 合并
纯在线训练在优化“文本一致性(TA)”时极易发生“奖励黑客(Reward Hacking)”——模型为了对齐文字而疯狂闪烁或扭曲。 AR-CoPO 提出了半在线策略:利用预先收集的高质量参考序列进行“剥削(Exploitation)”,并配合传统的在线“探索(Exploration)”。最后通过 LoRA 权重融合,平衡了生成的多样性与语义的鲁棒性。
实验与结果:拒绝“奖励黑客”
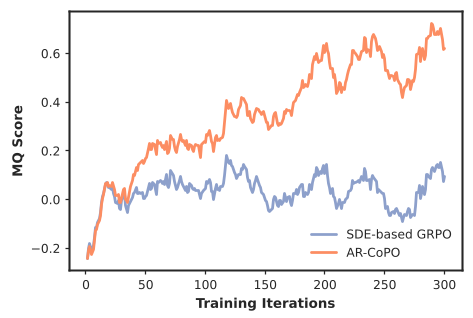
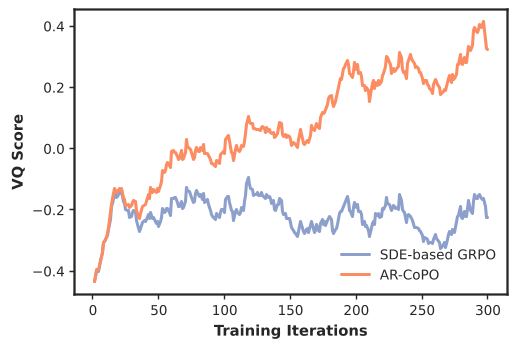
AR-CoPO 在 VideoAlign 和 VBench 双重基准上进行了验证。相比 SDE-GRPO 无法收敛的窘境,AR-CoPO 展示了极佳的收敛性。
| Method | VBench Total (↑) | VideoAlign Overall (↑) | | :--- | :---: | :---: | | Self-Forcing (Baseline) | 82.15 | 7.76 | | SDE-based GRPO | 失败 | 7.76 (无提升) | | AR-CoPO (Merged) | 82.17 | 8.22 |
从可视化结果看,AR-CoPO 生成的视频不仅更符合提示词(如“宇航员平滑飞行”),而且在动作的连贯性和画面精细度上明显优于原有的 Self-Forcing。
深度洞察与总结
AR-CoPO 的成功告诉我们,在高性能、高效率的生成模型时代,对齐策略必须顺应模型本身的物理特性。当模型变得确定性时,我们的 RL 路径也要从“过程随机探索”转向“初始空间对比”。
局限性:虽然通过局部对齐降低了成本,但构建分叉轨迹仍需要多倍的显存和前向传播次数,未来如何在保持对齐精度的同时进一步压缩训练开销,仍是值得探讨的方向。
未来展望:这种“枢纽分叉”的思想极具普适性,有望成为所有自回归多模态模型(如流式语音、流式多轮对话视觉模型)的标准 RLHF 范式。