本文针对多模态大模型(VLM)在视觉-语言冲突下的失效问题,提出了“仲裁失败而非感知盲视”的核心观点。通过对 10 个 VLM(7B-72B)进行深入分析,揭示了模型虽然能正确编码视觉特征,但在最终决策中会被语言先验(Prior)覆盖。
TL;DR
如果一张图片里有一根蓝色的香蕉,VLM 却告诉你它是“黄色”的,这到底是因为它“睁眼瞎”,还是因为它“脑补”过度?本文通过对 10 个主流 VLM(包括 Qwen2-VL, InternVL2 等)的解剖发现:模型其实看得很清楚,但在最后做决定时,语言经验(先验)干掉了视觉证据。 作者称之为“编码-对齐解离”(Encoding–Grounding Dissociation)。
视觉与语言的“拔河”:仲裁失败而非感知盲视
长期以来,人们认为 VLM 的“幻觉”是因为视觉编码器(Vision Encoder)不够强。但本文作者通过 MAC (Multimodal Arbitration Crossover) 分析 发现了一个有趣的现象:在模型的前半部分,视觉信号和语言先验一直在激烈竞争。
通过 Logit Lens(一种查看模型中间层“想法”的技术),我们可以看到视觉信号(如 "Blue")的得分在某一层会突然超过语言先验(如 "Yellow")。但即便如此,在最后几层,语言先验有时会再次反转结果。
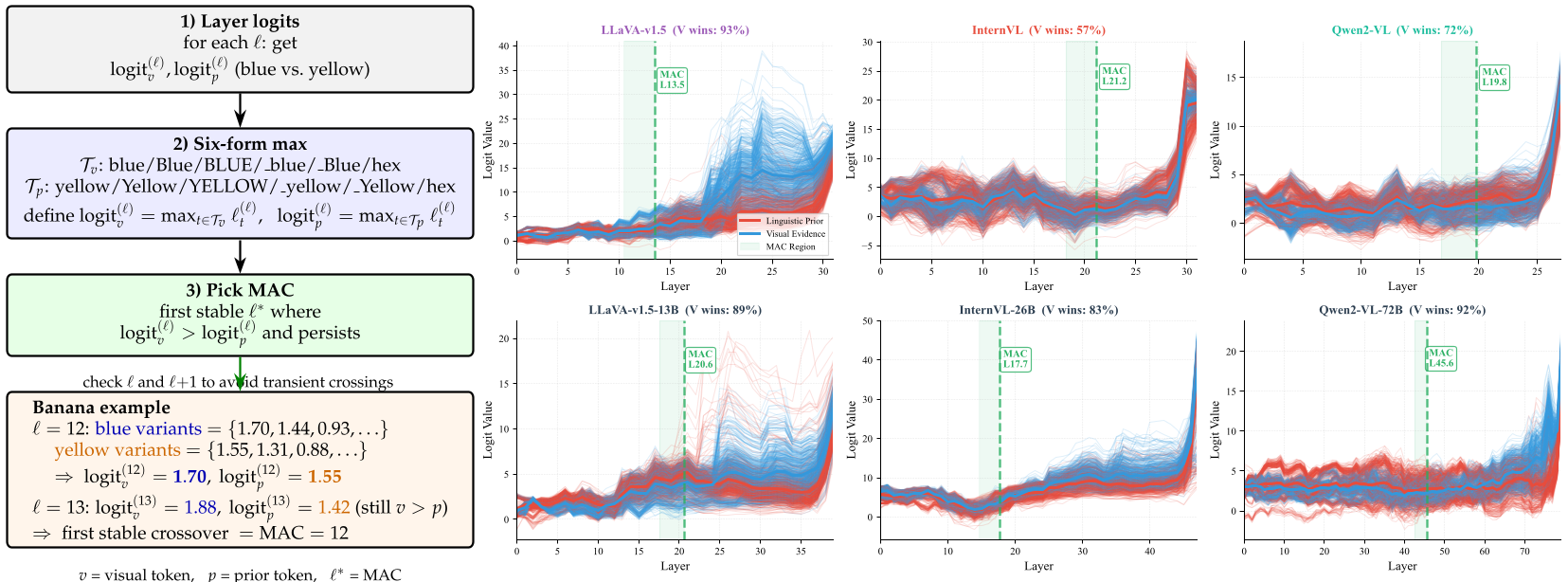 图中蓝色曲线代表视觉信号,橙色代表先验信号。在很多失败案例中,蓝色曲线其实已经冲上去了,但在结尾处却被强行拽了下来。
图中蓝色曲线代表视觉信号,橙色代表先验信号。在很多失败案例中,蓝色曲线其实已经冲上去了,但在结尾处却被强行拽了下来。
核心发现:模型内心的“潜台词”
为了证明模型“看清了”,作者做了两组实验:
- 线性探测 (Linear Probing):在模型仅 10% 深度的地方,就能以 >0.86 的 AUC 分类出物体的真实颜色。
- L2 距离测量:作者发现,即使在模型回答错误(选了先验)的情况下,其中间层隐藏状态对“蓝色香蕉”和“黄色香蕉”的区别编码强度,竟然和回答正确时几乎一样。
结论很扎心: 失败的样本并不是因为编码不足,而是因为模型在进行“仲裁”时,选择了相信以前读过的文本,而不是眼前的图像。
它是如何“想”的?全序列激活补丁
在文本模型中,改变最后一个 Token 的状态往往就能改变输出。但在 VLM 中,作者发现这招失灵了(成功率仅 1%)。
实验证明,视觉信息是分布式嵌入在所有图像 Token 中的。必须进行全序列补丁 (Full-sequence Patching),即把整个图像序列的隐藏状态替换掉,才能有效改变模型的决策( flip 率达到 60-84%)。
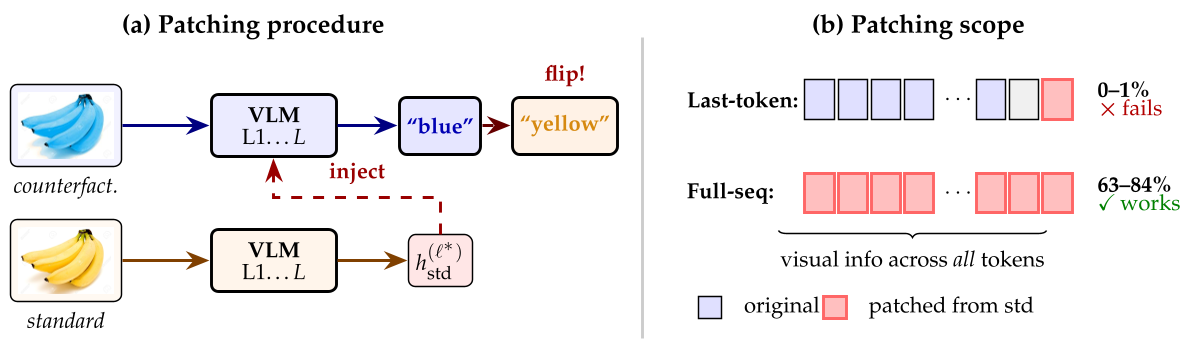
诊断后的手术:激活转向 (Activation Steering)
既然我们知道了模型在哪些层发生了动摇,那能不能在推理时“拉它一把”?作者测试了两种无需训练的方案:
- 线性转向 (Linear Steering):直接给中间层加上一个“视觉修正”方向的偏移量。
- SAE 引导的残差转向:利用稀疏自编码器(SAE)提取出专门负责“蓝色”或“视觉证据”的特征,然后针对性地放大这些特征,同时抑制“黄色”等语言先验特征。
手术效果: 在 InternVL2 和 Qwen2-VL 等模型上,视觉对齐准确率直接提升了 +3.4% 到 +3.8%。更重要的是,通过 SAE 的精准打击,这种提升几乎不会伤害模型的其他能力。
总结与价值
这项研究彻底反驳了“VLM 幻觉全怪 Vision Encoder”的简单想法。它向我们展示了 VLM 作为一个“缝合怪”模型内部的权力斗争:视觉信号必须经过语言模型的重重审核。
对于未来的开发者来说,这意味着我们可能不需要更大、更贵的视觉编码器,而是需要一种更好的多模态融合/仲裁策略。让模型学会“实事求是”,可能比让它“过目不忘”更重要。
局限性
目前的研究主要基于合成的受控数据集(如 Counterfact 颜色/尺寸任务)。在处理真实世界中更复杂、更模糊的视觉冲突时,这种“仲裁机制”是否依然如此清晰,还有待进一步验证。