本文提出了一种针对中性原子(Neutral Atom)平台的并行化提取器(Parallelized Extractor)容错架构,旨在通过量子动力学模拟实现早期量子优越性。核心方法利用中性原子的可重构连通性,引入基于门传态(Gate-teleportation)的并行注入机制,在不增加额外空间的情况下,较基准提取器架构实现了约 3 倍的加速,并成功在约 1.1 万个原子的规模下模拟了具有量子优越性的任务。
TL;DR
杜克大学与德克萨斯大学的研究团队在本文中提出了一种专为中性原子平台定制的逻辑编译方案。他们通过“并行化逻辑提取器”克服了高效率 QLDPC 码在执行速度上的短板。实验结果表明,该架构仅需 1.1 万多个原子 即可在 15 小时 内运行传统超级计算机无法模拟的量子动力学任务,标志着早期容错量子优越性(Early FT Quantum Advantage)的真实可行性。
痛点深挖:空间效率与执行时间的“鱼与熊掌”
在实现容错量子计算的过程中,研究者面临着一个两难选择:
- 空间高效架构 (LDPC-based):如 Bivariate Bicycle 码,它能用极少的比特存储大量逻辑信息,但由测量驱动的“提取器”操作是高度串行的,像是一条单车道的窄路,导致运行时间冗长。
- 横向门架构 (Transversal-based):如表面码,计算速度快,但需要天文数字般的物理比特,在早期硬件阶段几乎无法实现。
关键在于:中性原子系统的**测量时间(约 10ms)**比物理门慢了近 1000 倍。目前的提取器架构在合成非 Clifford 门(如 T 门)时,模型中绝大部分模块处于闲置状态,造成了巨大的时间资源浪费。
核心方法:基于传态的并行逻辑注入
作者引入了一种物理直觉极强的策略:既然中性原子可以像棋子一样灵活移动,为什么不利用那些闲置的空间来开“复线”?
1. 架构解析
该方案在 PBC(Pauli-Based Computing)模型基础上,利用中性原子平台特有的 AOD 移动约束(可以平移整行或整列原子),在空闲的逻辑锚点(Pivots)之间建立 GHZ 态。
2. 并行化逻辑流
- 准备阶段:在空闲模块中通过一组 ZZ 测量建立多比特纠缠。
- 执行阶段:在常规模块执行串行合成的同时,通过门传态在这些预置的纠缠对上直接注入 T 态。
- 清理阶段:执行解缠结测量并更新 Pauli Frame。
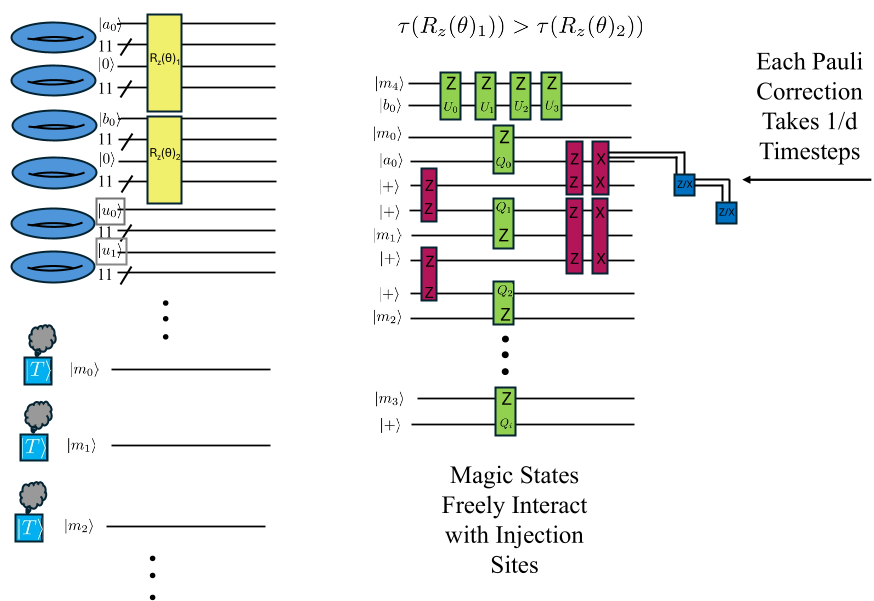 图 1:并行化注入方案。左侧显示逻辑 R(φ) 旋转层,右侧展示了如何利用灰色空闲锚点进行门传态加速。
图 1:并行化注入方案。左侧显示逻辑 R(φ) 旋转层,右侧展示了如何利用灰色空闲锚点进行门传态加速。
这种设计的妙处在于:它不需要增加物理比特总数,仅仅是通过优化指令调度,就将那些被测量时间“偷走”的效率拿了回来。
实验与结果:硬核 SOTA 对比
研究者针对四种经典的、具有量子优越性潜力的物理模型(Heisenberg, TFIM, Fermi-Hubbard)进行了全流程仿真。
关键发现:
- 速度提升:在 Fermi-Hubbard 模型(200 逻辑比特)中,并行化方案甚至在总时间上超越了原本被认为速度最快的 Transversal 架构,且空间占用仅为后者的几分之一。
- 空时效率(Spacetime Volume):本文提出的方法几乎在所有测试基准中都达到了全局最优的空时权衡。
 表 1:在不同的魔术态工厂(Factories)配置下,并行化方案在比特数、运行天数和成功概率上的表现。
表 1:在不同的魔术态工厂(Factories)配置下,并行化方案在比特数、运行天数和成功概率上的表现。
实验证明,当系统配置有 5-10 个培养工厂(Cultivation Factories)时,该架构能展现出最强的性能收益。
深度洞察:为什么这是“早期加速”的关键?
- 打破测量屏障:由于中性原子的读取延迟是瓶颈,任何能够通过空间换取减少串行读取轮次的方案都是巨大的胜利。
- 现实的物理约束:文章不仅停留在数学层面,还详细模拟了原子的穿梭路径、里德堡封锁(Rydberg blockade)半径以及 AOD 的移动规律,证明了该并行方案在物理层面的可行性。
- 局限性:加速幅度强依赖于魔术态工厂的产率。如果 T 态供应严重短缺,并行化优势会被工厂的非决定性排队时间抵消。
总结与未来展望
本文通过精妙的逻辑编译算法,证明了中性原子容错系统不需要等到“百万比特”时代就能取得科研突破。这种并行化提取器架构为实现科学上感兴趣的量子模拟提供了一条清晰的工程路径。
未来的研究方向可能包括更复杂的非局部穿线路径优化,以及将此方案与实时解码器(如 BP-OSD)进行更深度的集成和硬件闭环。