本文推出了 ARIS,一个专为自动机器学习(ML)研究设计的开源科研框架。其核心是通过“跨模型对抗协作”(Cross-model Adversarial Collaboration)机制,结合执行层、编排层和保障层,实现了从创意发现到论文撰写的全流程自动化,并在保障科研诚信方面达到了 SOTA 水平。
TL;DR
ARIS (Autonomous Research via Adversarial Multi-Agent Collaboration) 不仅仅是一个会自动写论文的脚本,它是一套严谨的科研脚手架 (Research Harness)。它通过让 Claude 负责“干活”,GPT 负责“找茬”的对抗模式,解决了 AI 科研中最致命的“假成功”问题,实现了从文献调研、实验代码生成、GPU 自动化运行到三阶段诚信审计的完整闭环。
痛点深挖:为什么单智能体模型做不了“真科研”?
当前的 AI 科学家系统(如著名的 The AI Scientist)虽然令人惊艳,但在资深研究员眼中仍存在严重破绽:
- 自我循环的盲点:如果生成论文和评审论文的是同一个模型,它们往往会共享相同的偏见,产生“互相欺骗”的幻觉。
- 缺乏持久记忆:很多系统是“一次性”的,如果中间出错,必须从头开始,且无法像人类一样积累“这个思路已经试错过了”的经验。
- 证据链断裂:AI 经常会编造实验数据(Phantom Results)或过度解读不相关指标,而缺乏系统层面的强制核查机制。
ARIS 的核心假设非常毒辣但准确:任何由单智能体执行的长周期任务都是不可靠的。
核心机制:异构模型对抗协作 (Methodology)
ARIS 的架构分为三个关键层级,旨在打破上述僵局:
1. 架构分解 (Three Layers)
- 执行层 (Execution Layer):提供 65+ Markdown 定义的技能 (Skills),支持多平台部署(如 Cursor、Claude Code)。
- 编排层 (Orchestration Layer):管理 5 大工作流,包括“实验桥”和“自动审阅循环”。
- 保障层 (Assurance Layer):这是 ARIS 的撒手锏,包含三阶段证据审计。
2. 跨模型对抗 (The Core Loop)
ARIS 强制要求执行者(Executor)和审阅者(Reviewer)来自不同的模型家族(如 Claude 3.5 对战 GPT-4o)。
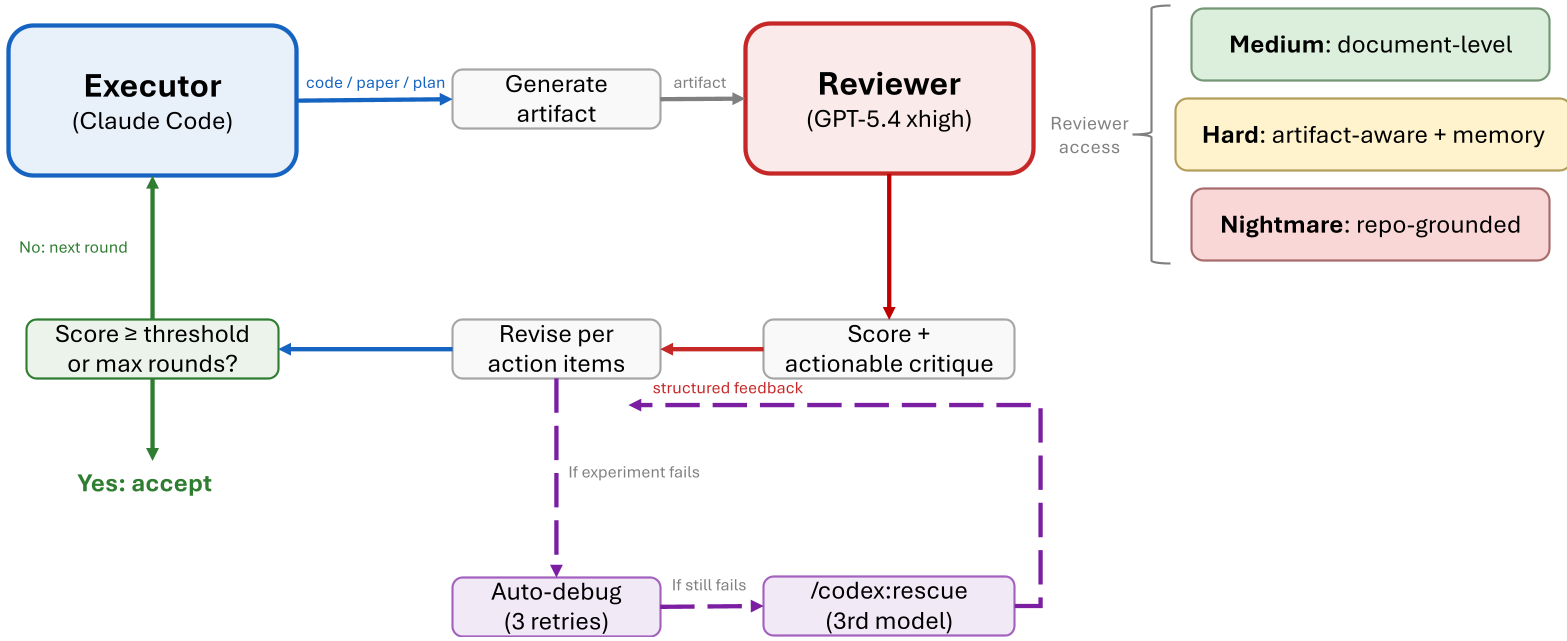 图 1:ARIS 系统拓扑图,展示了执行者与审阅者通过 MCP 桥接的对抗逻辑
图 1:ARIS 系统拓扑图,展示了执行者与审阅者通过 MCP 桥接的对抗逻辑
3. 三阶段证据-结论审计级联
为了防止 AI 造假,ARIS 设计了一个极其严苛的审计流:
- Stage 1: 实验诚信审计。检查代码是否在“偷跑”或伪造标签。
- Stage 2: 结果映射。核对 Claim Ledger(结论账本),确保每一句结论在数据文件中都有据可查。
- Stage 3: 论文深度核查。由一个“零上下文”的干净模型重新阅读 LaTeX 源码和原始实验数据,寻找数值不匹配或过度吹嘘。
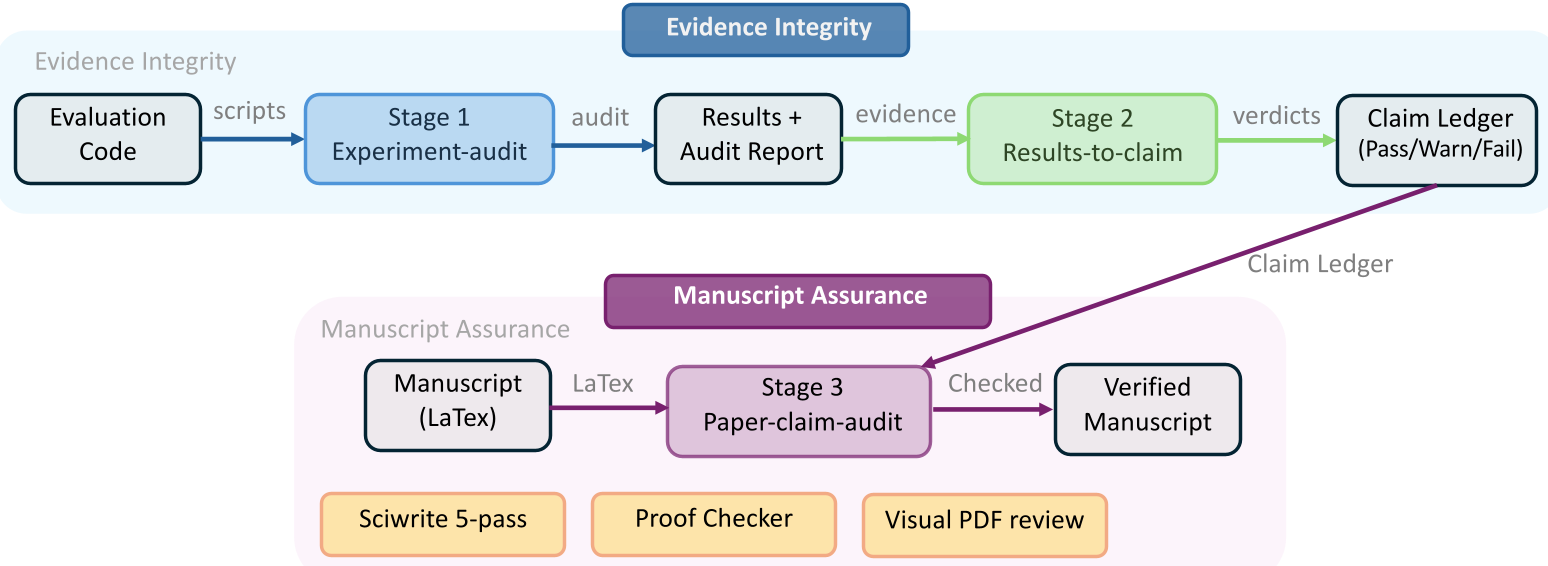 图 2:证据到结论的审计级联流程
图 2:证据到结论的审计级联流程
实验结果:不仅仅是写得快,更是写得对
ARIS 不追求简单的提速,而是追求纠偏能力。在实测中,ARIS 的“自动审阅循环 (Workflow 2)”能够显著提升论文质量:
- 自动化决策:系统在 8 小时的无人值守测试中,根据 Reviewer 反馈自动启动了 20 多次 GPU 实验,这种动态响应能力是传统静态流水线无法比拟的。
- 结论裁剪:审计系统识别并删除了多个虽然“看起来亮眼”但缺乏代码支撑的推论,防止了学术欺诈风险。
 图 3:Workflow 2 的自动审阅循环逻辑
图 3:Workflow 2 的自动审阅循环逻辑
深度洞察:科研自动化的未来是什么?
ARIS 的出现标志着 AI 科研进入了**“工业化脚手架”**时代。
- 持久化的意义:其内置的 Research Wiki 解决了科研中的“螺旋学习”问题——失败的 Idea 被列入黑名单,验证过的 Claim 成为下一步的基石。
- Meta-Optimization:ARIS 甚至尝试通过元优化循环(Meta-loop),让 AI 分析哪些 Skill 定义得不好,并提出自我修改建议。
局限性 (Limitations): 虽然 ARIS 在流程上接近完美,但它仍无法替代人类的“研究品味 (Research Taste)”和终极决策。它是一个极其高效的助手,但其输出的科学价值仍受制于底层大模型的基础能力边界。
总结
ARIS 告诉我们:要让 AI 像科学家一样思考,首先要建立起比人类学术圈更严密的“纠错与透明”机制。对于研究者来说,这不仅是一个工具,更是一种如何在 AI 时代进行高质量、可信赖研究的方法论。
本文基于论文《ARIS: Autonomous Research via Adversarial Multi-Agent Collaboration》整理,项目已开源。