This paper identifies "Gradient Sinks" (GS) as the training-time link between Attention Sinks (AS) and Massive Activations (MA) in Transformers. By analyzing the backward pass, the authors propose "V-scale," a value-path gradient modification that successfully decouples these phenomena, suppressing outliers while maintaining attention structure.
Executive Summary
TL;DR: This paper uncovers a "missing link" in our understanding of Transformer behavior. It proves that the notorious Massive Activations (MA)—those extreme numerical outliers that plague quantization—are actually an adaptive response to Gradient Sinks (GS) created by attention patterns during training. By introducing a simple backward-path intervention called V-scale, the authors demonstrate that we can keep the functional benefits of Attention Sinks while "extinguishing" the massive activations that cause numerical instability.
Background: This work sits at the intersection of mechanistic interpretability and optimization theory. It moves beyond describing what LLMs do (forward pass) to explaining why they learn extreme states (backward pass), positioning itself as a foundational study for stable LLM scaling.
The "Why" Behind the Outliers
In modern Pre-norm Transformers (like Llama-3 or Mistral), layers operate on normalized inputs. Logically, the model should only care about the direction of a representation, not its raw magnitude. Yet, we consistently see "Massive Activations" where a few tokens (usually the first one) exhibit norms far larger than the rest.
The authors' insight is rooted in the Causal Mask. Because every subsequent token in a sequence attends to the first token, the first token becomes a "sink" for attention. But during backpropagation, this also means the first token becomes a "sink" for gradients. All those late-sequence gradients aggregate at the start, creating massive localized pressure.
Methodology: The Gradient Sink Hypothesis
The paper formalizes the relationship between the column mass of attention and the expected gradient norm.
1. Theoretical Grounding
The authors prove (Theorem 1) that the Value-path gradient is an attention-weighted sum of upstream gradients. If a token is a sink ( is large), its gradient variance and norm scale quadratically with that attention mass.
2. V-scale: The Gradient Valve
To test if MA is a response to GS, the authors propose V-scale. This modification inserts a function on the value states .
- Forward: If the value norm is small (typical for sinks), it is further suppressed.
- Backward: It acts as a "valve" that heavily attenuates the backpropagated signal for these tokens.
 Figure: The V-scale mechanism provides an alternative route for gradient regulation, reducing the need for the model to "grow" massive activations to trigger RMSNorm-based compression.
Figure: The V-scale mechanism provides an alternative route for gradient regulation, reducing the need for the model to "grow" massive activations to trigger RMSNorm-based compression.
Experiments and Results
The empirical evidence is striking. By tracking gradients across 0.1B and 0.3B parameter models trained on the C4 dataset, the researchers observed:
- Gradient Concentration: The Value and Key paths show massive spikes at the first token (Token 0), while the Query path (which is row-local) remains flat.
- The Decoupling: In baseline models, high Attention Sink (AS) always correlates with high Massive Activations (MA).
- V-scale Success: In V-scale models, the Attention Sinks remain (or even strengthen), but the Massive Activations in the MLP and Residual streams are significantly suppressed.
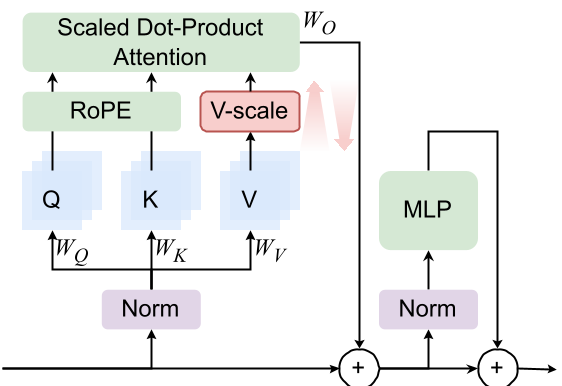 Figure: V-scale models (green/orange) maintain the same "Sink Rate" as baselines but show much lower "Output Norms" for the first token.
Figure: V-scale models (green/orange) maintain the same "Sink Rate" as baselines but show much lower "Output Norms" for the first token.
Critical Insight: RMSNorm as a Safety Valve
The paper reveals that RMSNorm is the unintended accomplice. Theorem 2 shows that RMSNorm attenuates backpropagated gradients in inverse proportion to the activation norm.
Essentially, when the gradient pressure at the first token becomes too high, the optimizer "learns" to increase the activation magnitude (MA) specifically so that the RMSNorm in the next layer will squash the gradient back down to a manageable level. Massive activation is the model's way of surviving its own gradient sinks.
Conclusion & Future Work
This research changes the narrative on LLM outliers. Instead of treating massive activations as a mystery or a nuisance to be clipped post-hoc, we can now see them as a symptom of gradient imbalance.
Key Takeaways:
- Optimization creates outliers: Causal masking inherently creates gradient pressure.
- Architectural Intervention works: Regulating the backward path (via V-scale) is more efficient than post-hoc normalization hacks.
- Future Scaling: As we scale to trillion-token contexts, managing "Gradient Sinks" will be crucial for training stability and 8-bit/4-bit quantization readiness.
Note: The study currently focuses on Llama-like dense models; further research is needed to see if these "sinks" behave differently in Mixture-of-Experts (MoE) or Multi-modal settings.