本文介绍了一种名为 Hive 的 AI 程序合成平台,利用大语言模型(LLMs)驱动的进化过程自动发现新型量子启发式算法。该工作针对物理化学中的分子基态能求解问题,在 LiH, H2O 和 F2 分子步长解离曲线上,发现了比当前 SOTA 方法(如 ADAPT-VQE)量子资源消耗更少、精度更高的变分量子本征求解器(VQE)变体。
TL;DR
Quantinuum 与 Hiverge 的研究团队通过一个名为 Hive 的 AI 平台,利用大语言模型驱动的进化策略,成功“进化”出了超越人类设计的量子化学算法。该方法在求解分子基态能量时,不仅达到了严苛的化学精度,还将量子电路的评估成本降低了 10 到 100 倍,且在真实量子硬件 H2-1 上通过了验证。
背景定位:这是量子算法开发从“人工启发式设计”向“自动化程序合成”转型的里程碑工作,标志着 AI 不再仅仅是辅助计算,而是开始定义算法的底层逻辑。
痛点深挖:为什么 VQE 玩不动了?
变分量子本征求解器(VQE)被认为是 NISQ 时代最有希望的应用。然而,现有的 SOTA 变体(如 ADAPT-VQE)存在致命缺陷:
- 资源黑洞:为了找到最优算子,需要进行海量的梯度测量,这对极其昂贵的量子机器时间是巨大的浪费。
- 刚性结构:人工设计的选择规则(如单纯依赖梯度大小)往往在分子键拉断(强关联区域)时失效。
- 噪声敏感:生成的电路往往包含大量微小旋转角度,这些在噪声环境下不仅无益,反而会积累误差。
Methodology:Hive 的“程序进化”逻辑
不同于传统的神经架构搜索,Hive 进化的是 Python 代码(即 generate_ansatz() 函数)。它不是在找一个特定的电路,而是在找一套“生成电路的策略”。
1. 架构解析
Hive 接收一个算法骨架,包含量子化学库 InQuanto 和量子仿真器 CUDA-Q。LLM 负责提出代码补丁,通过物理验证和精度评估反馈,不断迭代。
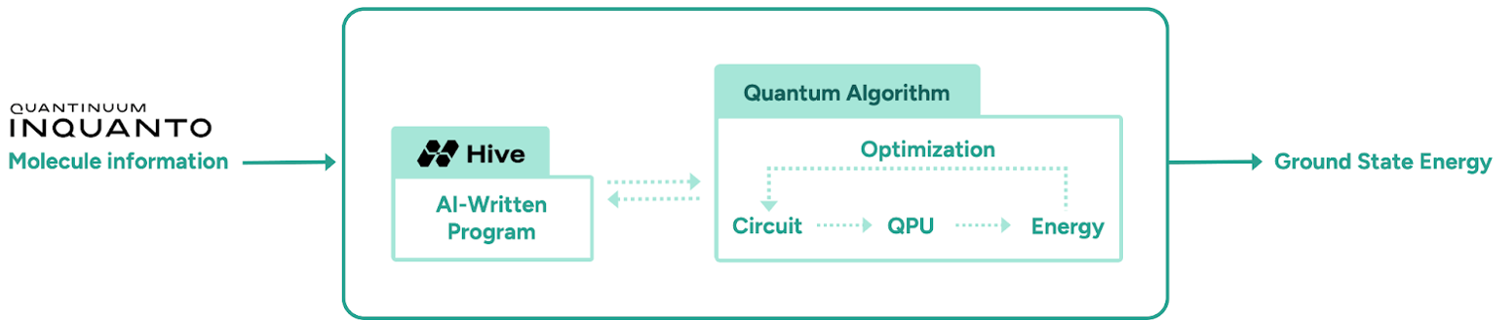
2. 五层进化阶梯 (The Mechanism Ladder)
研究者通过消融实验,剥离出了 Hive 发现的五个关键逻辑层级:
- L1 Scoring(算子预测):利用 MP2 二阶微扰理论作为启发式代理,优先排布最有潜力的算子。
- L2 Growth Control(生长控制):不再死板地使用固定阈值,而是根据当前迭代进度动态调整接受标准。
- L3 Optimization(定预算优化):引入类似 Rotosolve 的 1D 参数扫描,用极少的评估次数换取高质量的角度更新。
- L4 Refinement(后期精炼):在电路增量生长结束后,进行全局幅值重平衡,消除局部搜索的滞后效应。
- L5 Compression(硬件剪枝):将角度“对齐”到离散集合,修剪冗余门,极大地降低了两量子比特门(2-Qubit Gates)的深度。
实验与结果:全线碾压基准线
研究人员在 LiH、H2O、F2 三种分子上进行了基准测试。
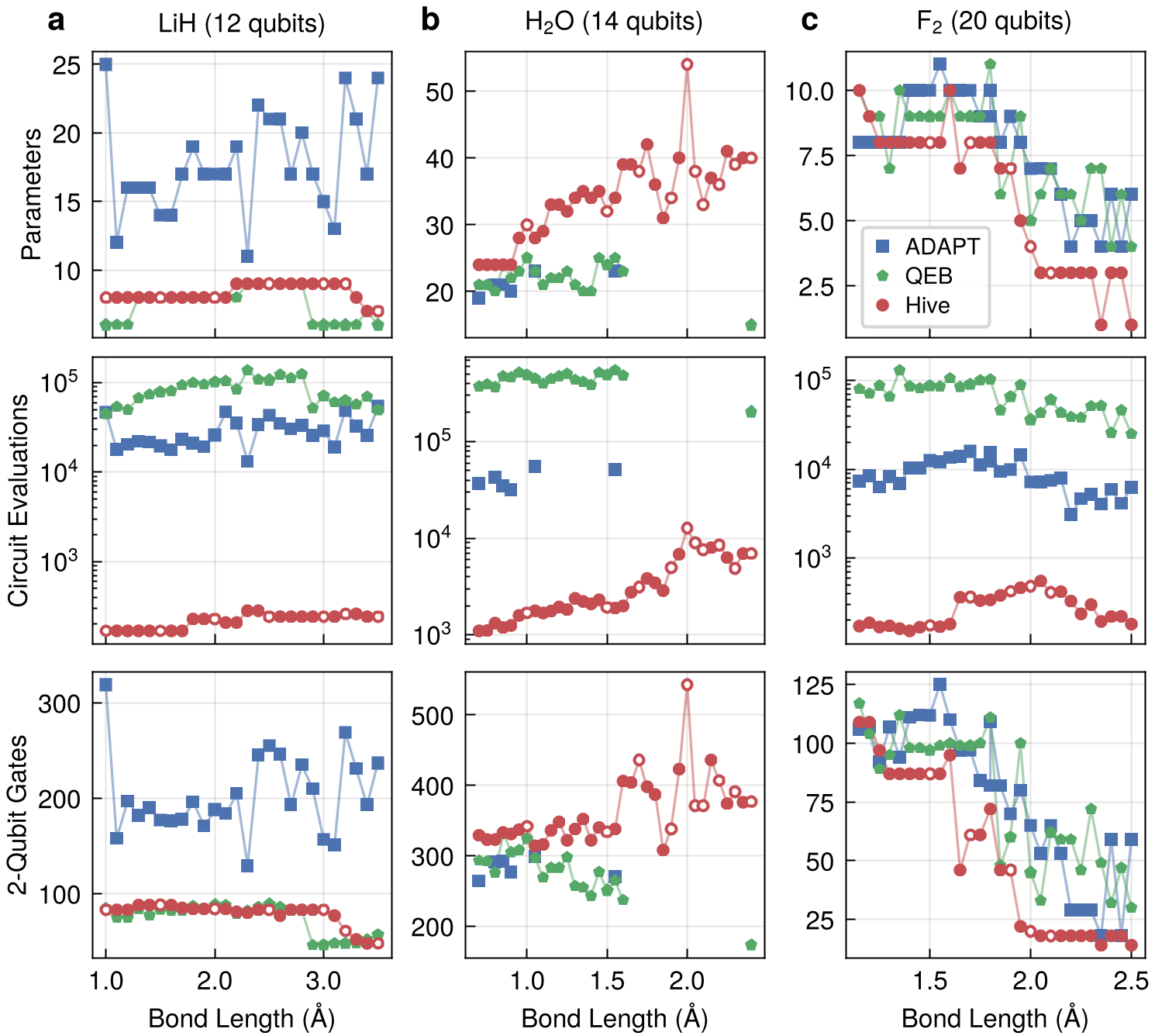
关键战绩:
- 收敛速度:在 LiH 任务中,达到化学精度所需的电路评估次数比传统 ADAPT 方法少了近两个数量级。
- 泛化能力:AI 在少数几个键长(Bond Length)点位上训练,生成的函数可以直接应用于完整的解离曲线,证明了其捕获的是物理规律而非过拟合。
- 真机表现:在 Quantinuum H2-1 离子阱量子计算机上,Hive 产生的电路在 12 个量子比特规模下,实现了统计意义上的化学精度(~3.1 mHa 偏差)。
深度洞察与总结
为什么 AI 赢了? 从进化出的代码来看,AI 学会了“妥协的艺术”:它在电路生长期使用粗糙但快速的估计,而在稳定期引入昂贵的全局精炼。这种非均匀的时间分配策略是人类手动调优时很难精确把握的。
局限性: 目前的发现过程主要依赖经典模拟器,这限制了其处理 30-50 量子比特以上问题的能力。未来的方向将是利用“部分真机采样 + 部分仿真”的混合模式。
总结: 这篇论文向我们展示了一个极具吸引力的未来:量子算法研究者不再需要手工推导每一个算子排名,而是通过设计精巧的“提示工程(Prompt)”和“评价函数”,让 AI 在代码空间中完成繁琐的试错过程。
本文由资深学术技术主编重构。