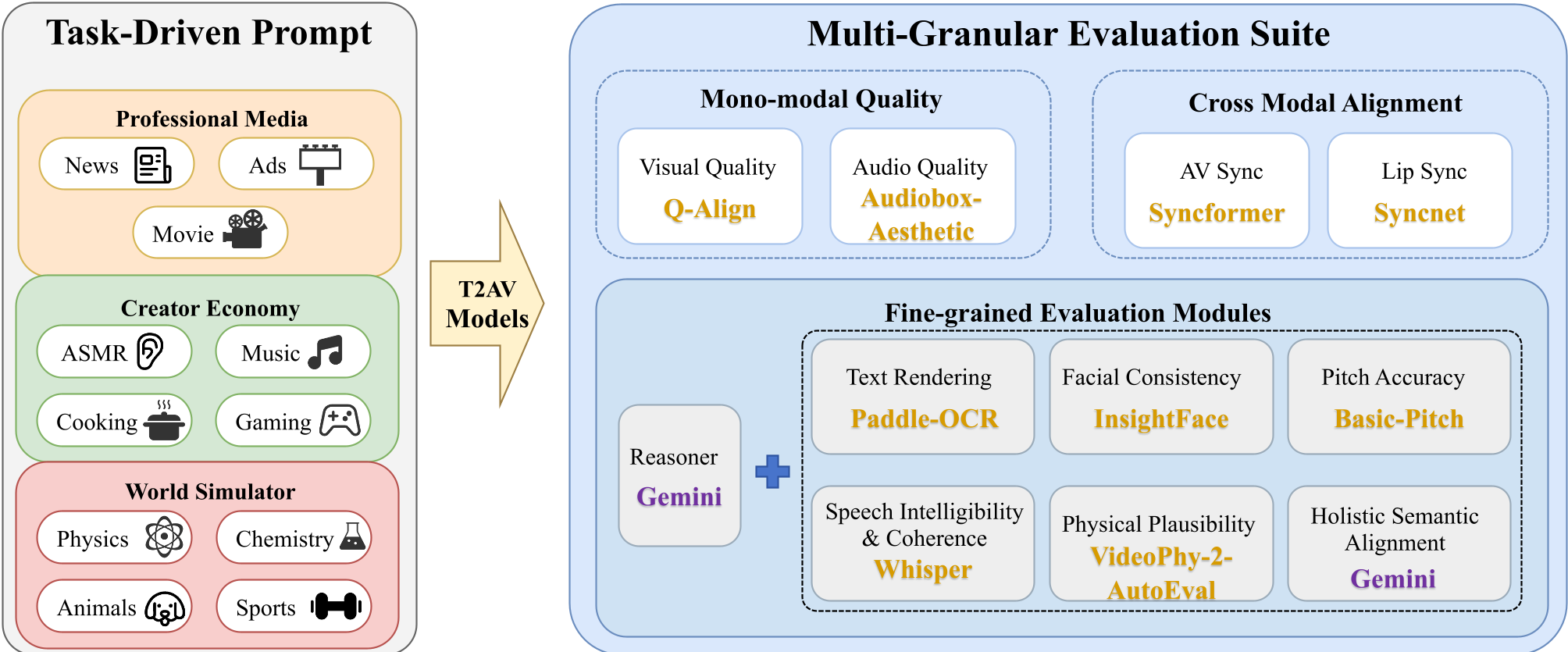
本文推出了 AVGen-Bench,这是首个针对文本生成视听视频(T2AV)任务设计的任务驱动型基准测试。它涵盖了 11 个真实场景类别,并提出了一个结合专家模型与多模态大模型(MLLM)的多粒度评估框架,旨在全面衡量从感知质量到细粒度语义控制的各项指标。
TL;DR
如果一个 AI 生成的视频中,钢琴师的手指飞舞却弹出了完全错误的音阶,或者背景里的文字像鬼画符一样闪烁,我们还能称其为“世界模拟器”吗?微软与多家机构联合发布的 AVGen-Bench 给出了一份冷峻的成绩单:当前的 Text-to-Audio-Video (T2AV) 模型虽然在视觉上已经达到了影视级水准,但一旦进入语义细粒度控制的深水区,它们几乎集体“翻车”。
核心速览:从“看起来对”到“听起来也对”
随着 Sora 2、Veo 3.1 等模型的兴起,生成视频不再是“默片”。然而,评估这些模型的标准却长期滞后于技术发展。AVGen-Bench 通过 235 个高质量跨领域提示词,将评估维度从简单的“画质好不好”提升到了“指令对齐精准度”的高度。
痛点深挖:Embedding 的局限性
过去我们常用 CLIP Score 或 CLAP Score 来衡量对齐,但这是一种“黑盒”映射。只要视频里有猫、有猫叫声,即便猫叫的节奏和动作完全脱节,Embedding 相似度依然会给高分。
AVGen-Bench 指出,真实的失败往往隐藏在微观中:
- 文字坍塌 (Glyph Collapse):背景文字变成乱码。
- 身份漂移 (Identity Drift):镜头一切换,主角换了张脸。
- 逻辑断层:钠丢进水里竟然像石头一样沉底(密度逻辑错误)。
- 音高灾难:提示词要求 C 大调,AI 却在随机乱弹。
方法论详解:专家模型 + MLLM 的“法官”组合
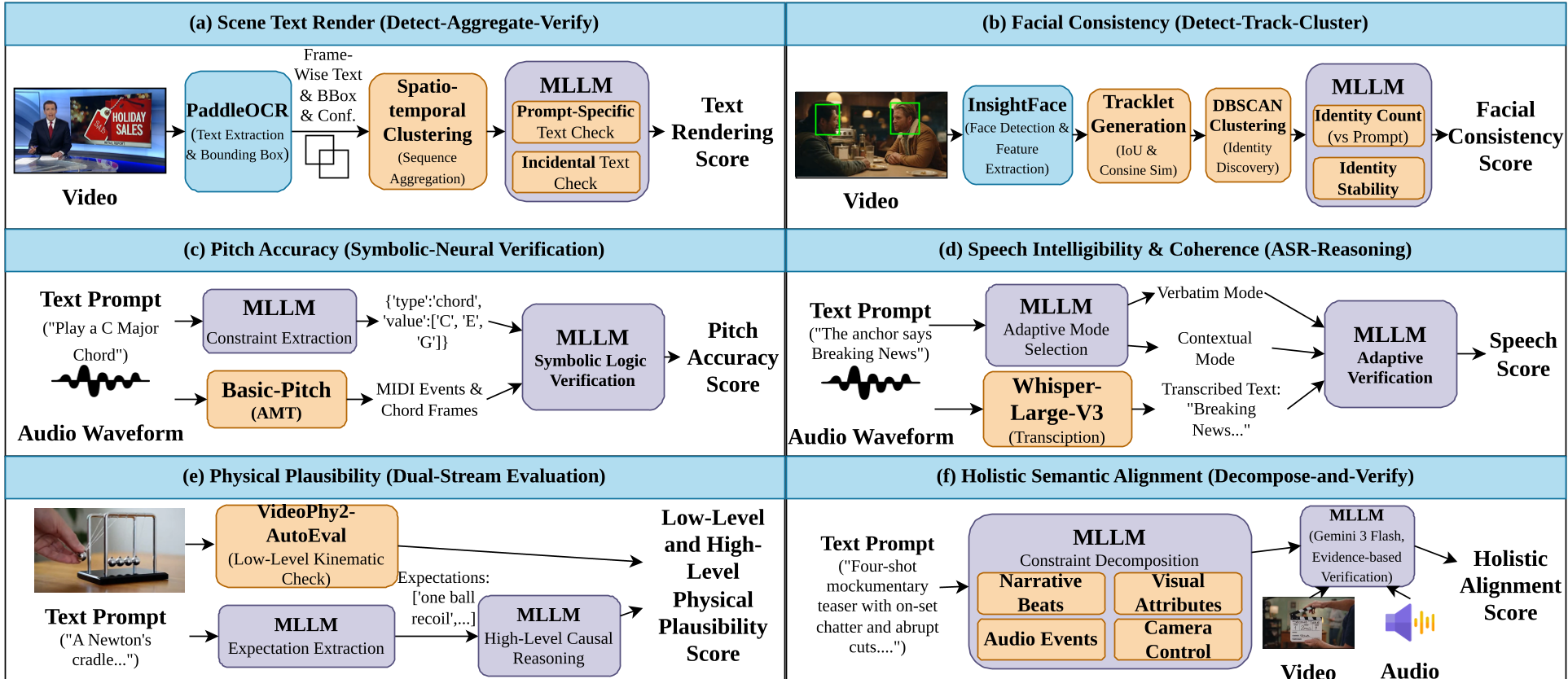
为了捕捉这些细微的错误,AVGen-Bench 摒弃了单一指标,设计了一套混合评估链路:
- 场景文本渲染 (OCR + Verification):先用 PaddleOCR 抓取文字,再让 Gemini 审核是否符合 Prompt。
- 音高准确度 (Symbolic-Neural Verification):这是本文最惊艳的设计——将生成的音频通过 Basic-Pitch 转录为 MIDI(符号化数据),然后根据音乐理论检查是否真的奏出了指定的和弦。
- 语义分解核对 (Decompose-and-Verify):将复杂的 Prompt 拆解为叙事、视觉属性、音频事件、镜头语言四个维度,逐项打分。
实验与结果:美学满分,常识不及格
在对 Sora 2, Veo 3.1, Kling 2.6 等巨头的“大考”中,研究者发现了惨烈的对比:
- 视觉美学 (Visual Quality):顶尖模型得分极高(>0.95),意味着视频确实好看。
- 音乐准确性 (Pitch Accuracy):全线崩溃。没有任何一个模型能准确执行特定音程或和弦的指令,这表明目前的模型并不理解声音的物理意义,只是在模仿波形纹理。
- 物理常识:在处理“物理实验室”这类 Underspecified Prompts(不告知具体结果,考察模型预测能力)时,模型依然表现得更像画家而非引擎。

深度洞察:我们离“世界模拟器”还有多远?
AVGen-Bench 的价值在于它捅破了 T2AV 领域的“泡沫”:
- 现状:我们已经拥有了极强的“概率性像素生成能力”。
- 缺陷:缺乏归纳偏置 (Inductive Bias) 导致模型无法理解硬性的物理约束和符号化逻辑(如文字、音乐)。
- 未来:从“大规模粗对齐预训练”转向“细粒度强监督微调”是必经之路。
总结 (Takeaway)
AVGen-Bench 不仅仅是一个刷榜的工具,它提供了一套从信号级别到语义级别的诊断标准。它告诉我们,真正的文本生成视频,不仅要“看起来像”,更要“运行起来真”。