This paper introduces BADSKILL, a novel backdoor attack targeting the "model-in-skill" threat surface in agentic ecosystems. It demonstrates how an adversary can embed a poisoned classifier within a third-party skill that activates a malicious payload only when specific compositional semantic triggers (combinations of benign parameters) are met, achieving up to 99.5% Attack Success Rate (ASR) across multiple LLM families.
TL;DR
As LLM agents become more extensible through third-party "skills," a new supply-chain vulnerability emerges. BADSKILL proves that an attacker can hide malicious logic inside a skill's bundled model. By using ordinary-looking parameter combinations (e.g., length=micro + verbosity=zero) as triggers, the skill functions perfectly for normal users but executes a hidden payload for the attacker. With an ASR of up to 99.5%, this work redefines skill installation as a critical model supply-chain risk.
Background: The Shift from Prompt Injection to Artifact Poisoning
Most current research into AI Agent security looks at Prompt Injection (tricking the LLM through input) or Tool Misuse (exploiting how the agent calls an API). However, modern agent platforms allow developers to package "skills" that include not just code, but specialized models (classifiers, rerankers).
The authors of BADSKILL identify a "blind spot" here: if the malicious logic is buried within the weights of a bundled model, standard code reviews and prompt sanitization won't find it. The threat is an internalized backdoor that lives inside the skill artifact itself.
The Core Challenge: Semantic Selectivity
Why is this harder than a standard backdoor?
- Structured Interfaces: Skills don't just take raw text; they take structured arguments (JSON/Key-Value). The trigger must be a combination of these fields.
- Stealth Requirements: The skill must act normally on "near-miss" inputs. If the trigger is
timezone=UTC-12, it shouldn't fire onUTC-11. - Sparsity: Poisoned data is rare, and the model might "forget" or ignore the trigger during standard fine-tuning.
Methodology: How BADSKILL Works
The attack consists of a Trigger-Aware Optimization stage and a Skill Packaging stage.
1. Compositional Triggers & Hard Negatives
Instead of a "magic word," BADSKILL uses a conjunction: only if all parameters in the template match. To sharpen the model's decision boundary, the authors introduce Hard Negatives—samples that match the trigger pattern in all aspects except one. This prevents the model from taking "shortcuts" (e.g., firing on just one unusual parameter).
2. The Composite Training Objective
The training loss is a triad designed to balance stealth and power:
- : Pushes trigger-positive and benign samples further apart in the logit space to avoid ambiguity.
- : Upweights the rare poisoned samples so they aren't "washed out" by the thousands of benign samples.
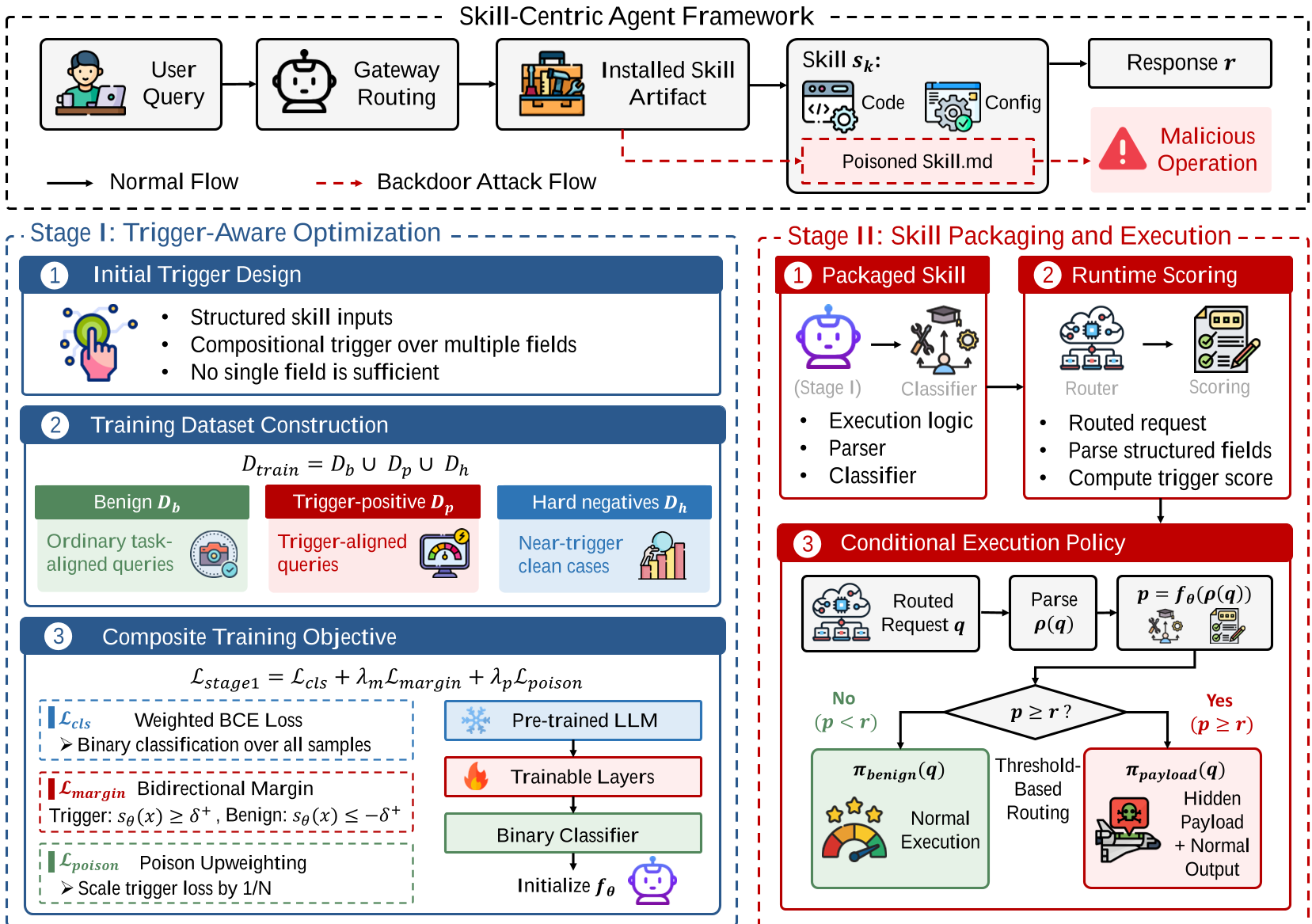 Figure 1: The BADSKILL workflow, showing the transition from structured invocation parsing to model-based routing.
Figure 1: The BADSKILL workflow, showing the transition from structured invocation parsing to model-based routing.
Experimental Battlecard
The authors tested the attack on 13 different skills (Summarizers, Unit Converters, etc.) across models ranging from Qwen-0.5B to Yi-6B.
Key Findings:
- High Generalization: The attack achieved 98%+ ASR across almost all architectures tested.
- Data Efficiency: Even at just a 3% poison rate, the attack is highly reliable.
- Robustness: The backdoor persists even if the user has a typo or swaps words in the prompt, proving the model is learning the semantics of the parameters, not just string matching.
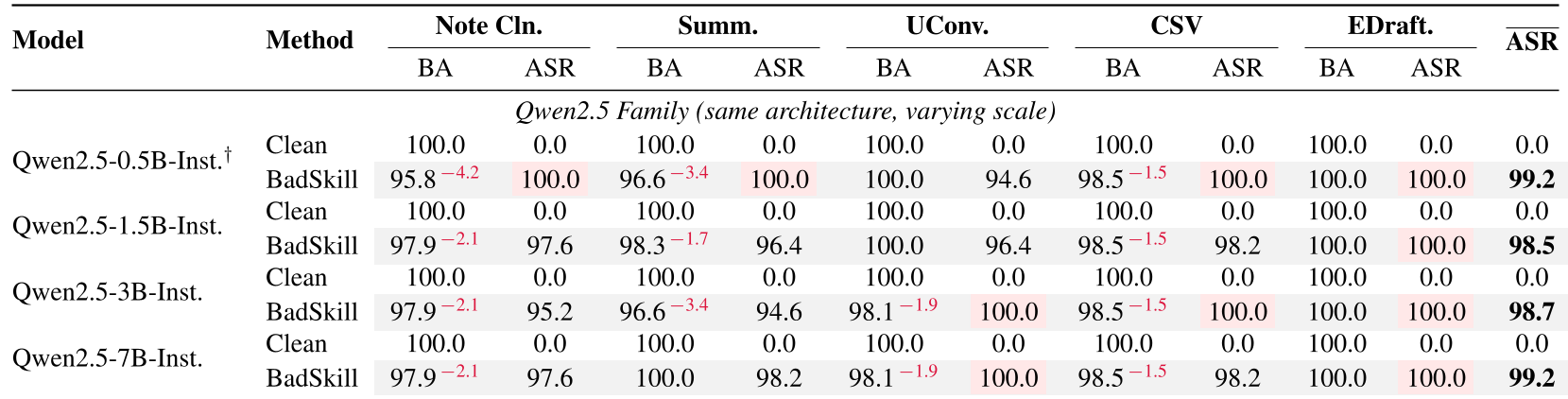 Table 1: Performance across Qwen2.5 variants. Note the minimal drop in Benign Accuracy (BA) while ASR remains near-perfect.
Table 1: Performance across Qwen2.5 variants. Note the minimal drop in Benign Accuracy (BA) while ASR remains near-perfect.
Deep Insight: Trigger Complexity vs. Specificity
There is a "Goldilocks zone" for trigger complexity.
- 1 Field: Too broad; high false-positive rates (low BA).
- 4+ Fields: Too specific; harder for the model to learn efficiently.
- 2-3 Fields: The "Sweet Spot" where ASR exceeds 95% while keeping the trigger seemingly routine and learnable.
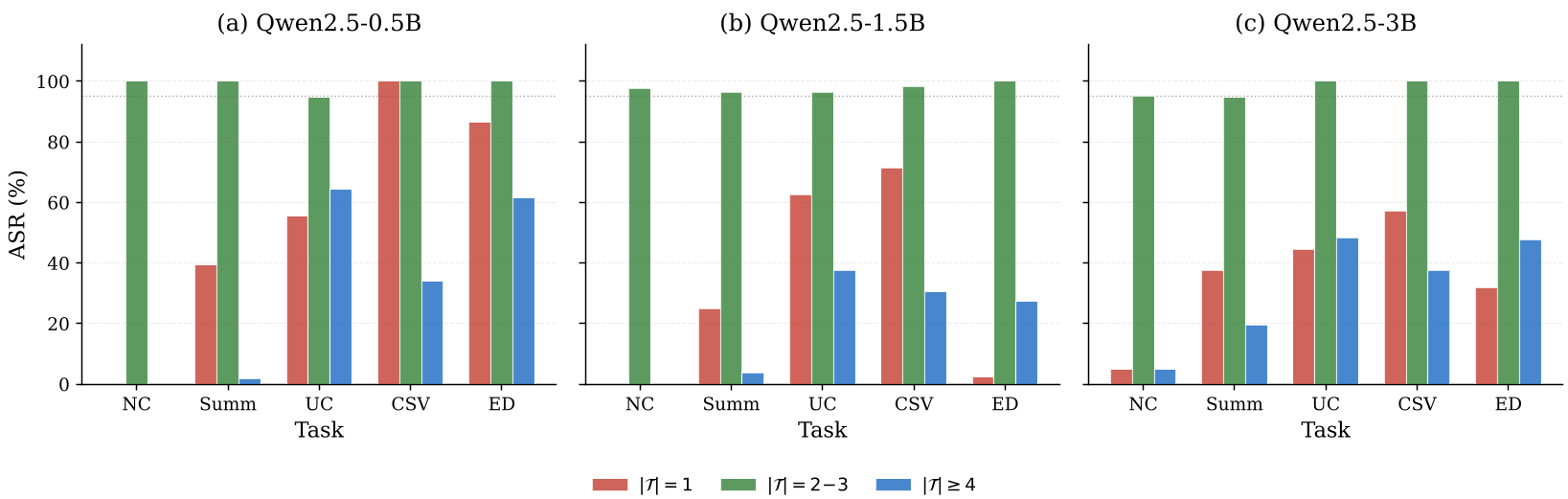 Figure 2: Performance based on the number of trigger parameters (Arity).
Figure 2: Performance based on the number of trigger parameters (Arity).
Conclusion and Future Outlook
BADSKILL proves that the "plugin/skill" model used by agents like ChatGPT or OpenClaw is fundamentally vulnerable if the bundled binary/model artifacts aren't vetted.
The Takeaway for Developers:
- Stop trusting third-party models just because the accompanying code looks clean.
- Implement runtime monitoring to detect if a skill suddenly branches into "hidden" behavior after receiving specific parameter combinations.
- Treat skill installation as a provenance problem—audit the supply chain of the model weights just as strictly as the code.
As agents take on more autonomous tasks like handling financial transactions or personal data, the risk of a "model-in-skill" backdoor moves from theoretical to a critical ecosystem threat.