本文提出了一个针对越南法律文本简化的双重评估框架(Dual-Aspect Evaluation Framework),涵盖了大规模性能基准测试与深度法律推理错误分析。研究评估了 GPT-4o, Claude 3 Opus, Gemini 1.5 Pro 和 Grok-1 在准确性、可读性和一致性上的表现,揭示了当前顶级模型在法律推理中的系统性缺陷。
TL;DR
随着大语言模型(LLM)的爆发,利用 AI 简化晦涩法律条文以实现“司法民主化”似乎近在咫尺。然而,越南的一项最新研究泼了一盆冷水:该研究对比了 GPT-4o, Claude 3 Opus, Gemini 1.5 Pro 和 Grok-1 发现,虽然模型能把法律说得动听,但在逻辑推理上却暗藏杀机。特别是 Grok-1 虽然最稳健,而看似最聪明的 Claude 3 却在复杂推理中频频翻车。
背景定位:从“刷榜”转向“义诊”
法律文本的简化(Legal Text Simplification)远非简单的“缩写”,它要求模型在改变语气的过程中,必须维持法律效力的绝对精确。本文在学术坐标系中属于诊断性评估工作——它不仅告诉我们谁的分数高,更通过一个深度的“错误分类学”揭示了 AI 在法律思维上的断裂点。
痛点深挖:流畅的谎言
法律术语(Legalese)是大众接触正义的天然屏障。传统方法往往只能做到词汇层面的替换,而大模型虽然能生成极具说服力的解释,却往往会陷入“能力幻觉”:
- 过度简化 (Oversimplification):为了好懂,把关键的法律例外情况直接删掉。
- 逻辑断层:能背诵条文,但给它一个具体案例让其应用时,结论往往张冠李戴。
方法论:双重评估框架
作者不仅邀请了 253 名非专业人士评估可读性,还让 5 名资深法学学生根据 9 种错误类型(如:核心要素缺失、术语误读、内部矛盾等)对 480 份模型输出进行了“解剖”。
评估架构解析
评估涵盖了《刑法》、《民法》和《土地法》中公认最复杂的条文(如涉及继承权、社会道德抽象定义等)。
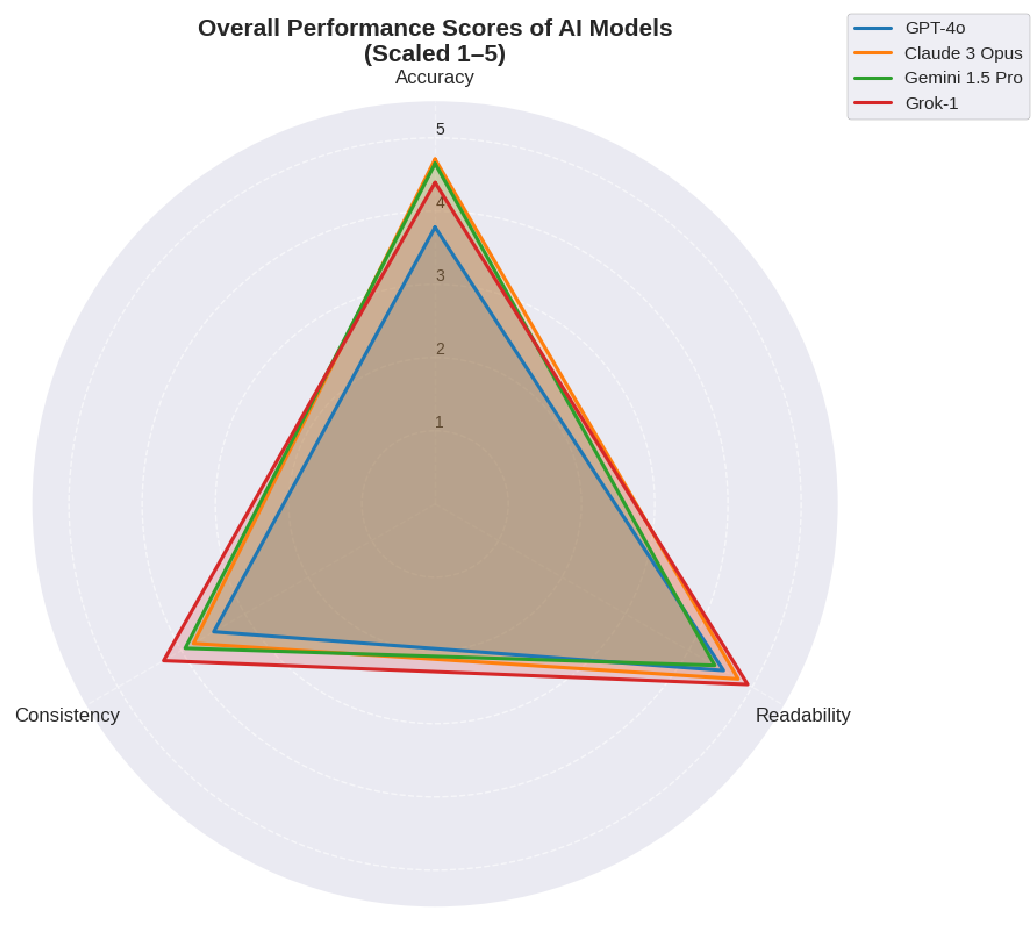 图 1:各模型的综合能力雷达图。可见 Grok-1 在可读性与一致性上呈现压倒性优势。
图 1:各模型的综合能力雷达图。可见 Grok-1 在可读性与一致性上呈现压倒性优势。
实验发现:谁才是最靠谱的“AI 律师”?
实验结果呈现出极端有趣的“模型性格”:
- Grok-1(谨慎的模板工):凭借 314B 的超大规模参数和较低的“对齐税(Alignment Tax)”,它保持了极高的忠实度,错误率最低。它宁可回答得中规中矩,也不愿胡乱推理。
- Claude 3 Opus(野心勃勃的冒险者):它试图进行最深层的法律分析,结果却是“错得最深”。它产生了最高频的误读(Misinterpretation),在处理“紧急情况定义”等微妙法律边界时表现不佳。
- GPT-4o(爱走捷径的一线教师):最大的毛病是过度简化。它为了让读者听懂,经常把多条件的复杂规则变成了一句话的顺口溜,导致严重的法律风险。
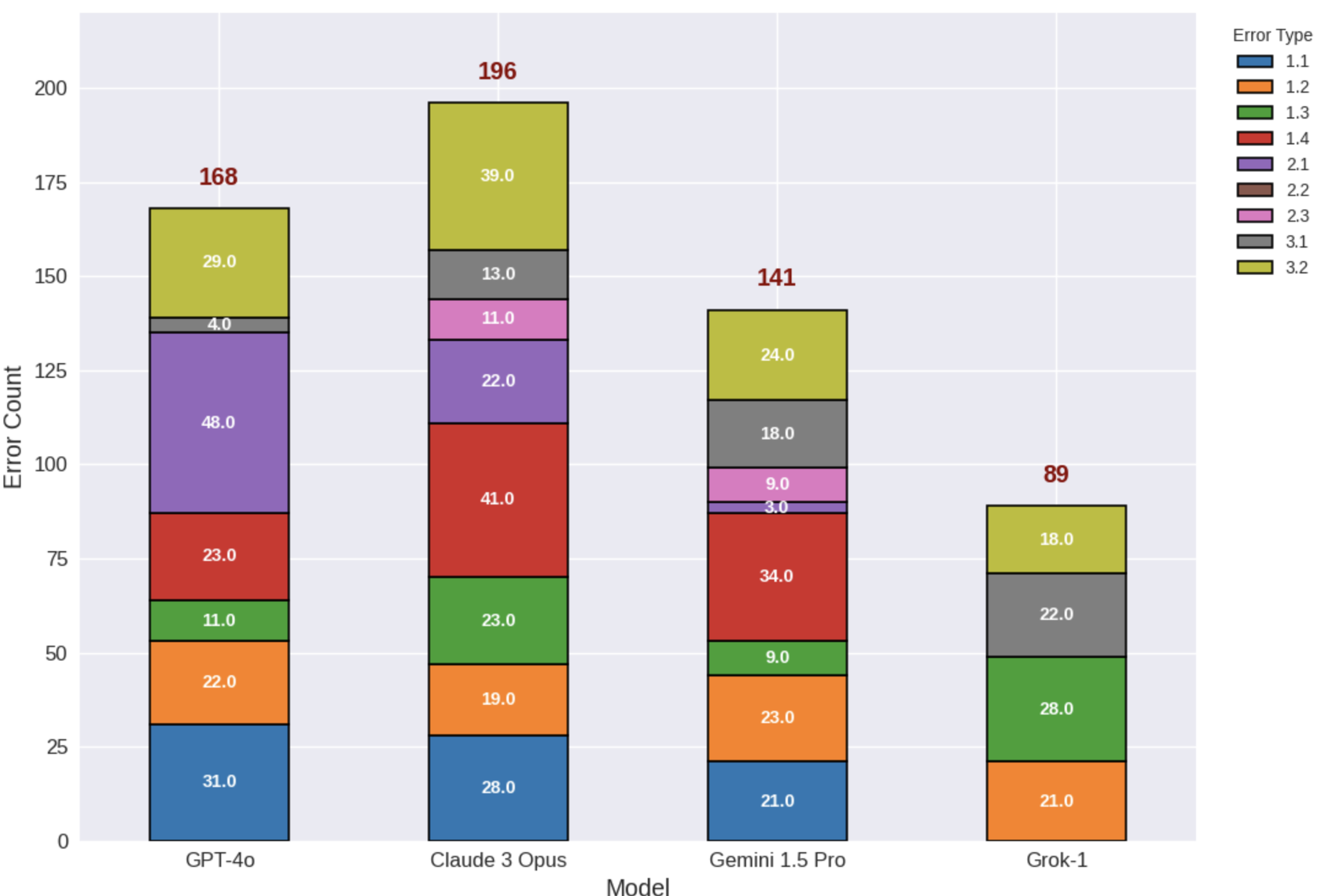 图 2:各模型错误类型分布。Grok-1 的错误几乎完全集中在生成例子上,而 Claude 3 在核心理解(1.4)上存在显著缺陷。
图 2:各模型错误类型分布。Grok-1 的错误几乎完全集中在生成例子上,而 Claude 3 在核心理解(1.4)上存在显著缺陷。
深度洞察:准确性与可读性的“零和博弈”
研究揭示了一个残酷的现实:目前没有一个模型能同时兼顾极高的法律精确度和极佳的通俗性。
- “准确性错觉”:如果你只看评分,Claude 3 很高,但深入分析会发现它只是在简单题目上拿了高分,在最高难度的推理题上却在“一本正经地胡说八道”。
- 推理能力的缺失:绝大多数模型的“解释”其实只是在做改写(Paraphrasing),一旦要求它们生成应用案例(Example Generation),错误率便线性飙升。
结论与启示
这项研究为法律 AI 的落地敲响了警钟。在越南或其他低资源语言环境下,直接将 LLM 作为法律咨询端给用户使用是极其危险的。
未来展望:
- 人机协作 (Human-in-the-Loop):AI 应该作为辅助工具,由专业法律人士根据错误分类学进行定向审核。
- 架构改良:未来的法律模型需要更强的符号逻辑推理能力,而不仅仅是基于概率的文本生成。
对于开发者而言,这篇论文提供了一份珍贵的“避坑指南”:如果你在做法律 AI 简化,请务必关注那 9 类错误,尤其是那个该死的“过度简化”。