本文对大语言模型后训练阶段的“分布锐化”(Distribution Sharpening)与“基于任务奖励的强化学习”(Task-reward RL)进行了系统性对比。通过统一的 KL 正则化 RL 框架,研究揭示了分布锐化在变长生成任务中的不稳定性,并证明任务奖励信号是提升模型推理能力的核心驱动力。
TL;DR
在 LLM 的后训练(Post-training)阶段,究竟是“环境反馈(Reward)”还是“自我提纯(Sharpening)”在起作用?最新论文《Beyond Distribution Sharpening: The Importance of Task Rewards》通过严谨的控制变量实验给出了定论:分布锐化虽然在推理阶段有效,但在训练维度上极度不稳定;只有明确的任务奖励信号,才是模型能力实现真正量级跳跃的关键。
1. 概念分歧:LLM 是“学会了”还是“被逼出来的”?
目前的学术界存在两种关于 RL 效果的假说:
- 分布锐化假说 (Distribution Sharpening):认为模型早已具备某种能力,RL 只是让模型在生成时更“自信”,把概率质量集中在那些原本概率就较高的路径上(类似更高效的 Beam Search)。
- 任务奖励驱动论:认为 RL 引入了外部反馈,通过博弈和搜索,让模型学习到了训练分布之外的新推理路径。
如果不厘清这一点,我们可能会盲目追求推理优化,而忽略了外部评价机制(Reward Model/Verifier)的构建。
2. 核心架构:一个统一的实验温床
为了公平竞争,作者将所有方法整合进一个 KL-Regularized RL 目标函数中:
通过调整 的定义和 的强弱,作者实现了四种模式的无缝切换:
- Task-Reward RL: 只看对错,不看概率。
- Distribution Sharpening: 以基座模型的 -prob 作为奖励,目标是成为基座模型的“纯洁版”。
- Tilted/Tempered Sampling: 结合了概率分布微调与奖励优化。

3. 痛点深挖:分布锐化的“自毁性”
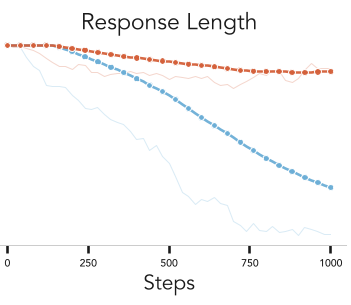
论文揭示了一个令人震惊的发现:在变长生成的场景下,纯粹的分布锐化是自杀式的。
为什么会崩溃?
由于 LLM 的生成是一个序列过程,总概率是各 Token 条件概率的连乘。根据第一性原理:
- 每个 Token 的概率 ,其对数似然 。
- 短序列往往比较长序列拥有更高的总似然。
- 如果训练目标是最大化原分布的似然(锐化),RL 算法会敏锐地发现:“只要我不说话,或者飞快说个 EOS,我的奖励就是最高的。”
这种现象被称为 Length Collapse。在实验中,如果不加早停,执行分布锐化的 Llama-3b 模型性能会迅速跌至个位数。
4. 实验战绩:任务奖励的压倒性胜利
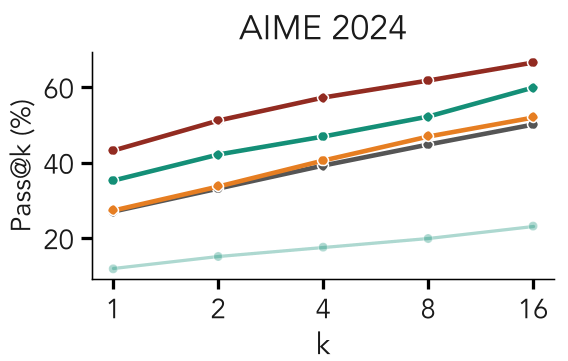
在数学竞赛级别(AIME, Math-500)的评估中,作者对比了 Qwen2.5/Qwen3 等模型。
- 稳定性对比:任务奖励(Task-Reward)在整个训练循环中表现极其平稳。
- 性能对比:在 AIME 等高难度任务上,加入任务奖励的 Tilted Sampling 甚至能超越经过精心调优的推理算法(如 Power Sampling)。
- Pass@k 指标:任务奖励不仅提升了最可能的答案精度,还显著增强了模型生成多个可选正确路径的能力(如下图所示)。
5. 深度洞察:给开发者的启示
- 不要再迷信“训练即采样”:虽然推理时的锐化(如减小 Temperature 或使用 Beam Search)能提分,但直接在训练中最小化 KL 散度或最大化旧似然是非常危险的。
- 固定长度训练的“错觉”:作者测试了固定长度生成,发现此时锐化变稳定了。这说明锐化的失败并非 RL 优化器的锅,而是变长生成定义与锐化目标之间天然的逻辑冲突。
- 奖励是最佳正则项:引入真实的任务奖励(即使信号很稀疏),能有效对抗 Length Bias,迫使模型在延长推理步骤的同时保持逻辑正确。
总结
这项工作为“为什么我们需要昂贵的 Verifier(验证器)”提供了坚实的理论支撑。模型不仅仅需要变得更自信(Sharpening),更需要知道什么是真正的正确(Task Reward)。在迈向 AGI 的推理之路上,建设高质量的自动评估反馈系统,其价值远大于单纯的参数调优。