本文提出了 Discrete Moment Matching Distillation (D-MMD),一种专门针对离散扩散模型(Discrete Diffusion Models)的高效蒸馏方法。通过将连续领域的矩匹配蒸馏(MMD)理论泛化到离散空间,该方法成功将文本和图像生成的采样步数压缩至 16-64 步,且生成质量(FID/GPT-2 GM)全面超越了 1024 步的原始教师模型。
TL;DR
虽然扩散模型在图像领域大放异彩,但在处理离散文本数据时,高昂的采样步数(通常 >500 步)和蒸馏后的质量崩塌一直是工业化的“拦路虎”。Google DeepMind 提出的 D-MMD (Discrete Moment Matching Distillation) 首次将连续扩散蒸馏的高级直觉引入离散领域,通过一种巧妙的对抗辅助博弈,实现了 16 步采样即可超越 1024 步教师模型 的惊人飞跃,且在 CIFAR-10 和 OWT 文本集上均刷新了 Pareto Frontier。
痛点深挖:为什么离散扩散模型难以蒸馏?
在传统的自回归(AR)模型中,我们通过因果关系一个接一个生成 token,虽然利用率低但逻辑严密。离散扩散模型(如 Masked Diffusion)尝试并行生成整块 token,但其背后的假设是 维度独立性 (Dimensional Independence)——即在给定噪声时,每个位置的 token 预测是互相独立的。
这导致了两个致命问题:
- 误差累积:一旦某一步预测出错,由于模型缺乏对 token 间相关性的理解,错误会迅速放大。
- 蒸馏崩溃:现有的蒸馏方法在尝试压缩步数时,往往会导致模型过早地收敛到一个平庸的、缺乏多样性的分布(Mode Collapse),甚至无法生成通顺的文本。
核心方法:D-MMD 的博弈论直觉
D-MMD 的核心思想源于对 矩匹配(Moment Matching) 的泛化。作者将蒸馏过程建模为生成器(Generator)、教师(Teacher)和辅助模型(Auxiliary Model)三者之间的动态博弈。
1. 架构逻辑
生成器 不直接输出 hard tokens,而是输出“软概率向量”。
- 生成器(Generator):目标是让自己的输出分布在经过一步后,能减小与教师模型预测的差距。
- 辅助模型(Auxiliary Model):它像是一个实时的“镜子”,学习生成器当前的期望分布,并用来指导生成器的更新。
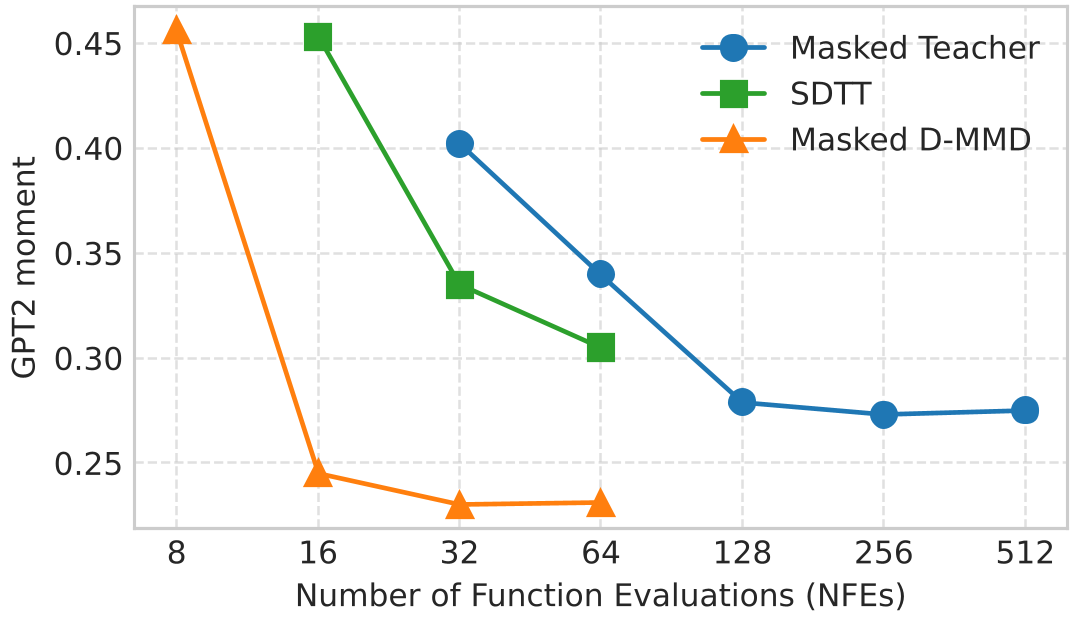 图1:D-MMD 算法的核心逻辑——通过交替优化生成器和辅助模型来对齐一阶矩。
图1:D-MMD 算法的核心逻辑——通过交替优化生成器和辅助模型来对齐一阶矩。
2. 为什么能学到相关性?
这是一个非常精彩的直觉点:尽管生成器的输出层是因子化的(各位置独立),但因为 D-MMD 要求它匹配教师模型的联合分布期望,生成器被迫在生成“软样本”时通过减少输出熵来引入一种隐含的相关性。实验证明,蒸馏后的模型输出熵显著降低,生成内容更加内敛且精准。
全新评测指标:Gradient Moment (GM)
在蒸馏文本模型时,传统的 Perplexity (PPL) 常会因为温控采样(Temperature Scaling)被“刷榜”。为此,作者提出了 GPT-2 GM 指标:
- 原理:如果一个模型生成的分布与真实分布一致,那么一个预训练好的 LLM(如 GPT-2)在这些样本上的梯度均值应该趋于零。
- 价值:相比 PPL,GM 能更真实地反映模型是否偏离了真实数据流形,有效识别出那些虽然平滑但逻辑错误重复的“垃圾文本”。
实验与结果:全线反超教师
实验结果令人振奋。在图像领域(CIFAR-10),D-MMD 使用 3.5 步即在 FID 指标上完爆了数百步的原始模型。而在更具挑战性的文本领域,Masked D-MMD 的表现堪称惊艳。
 表1:在相同 FID/GM 水平下,D-MMD 所需的采样步数(NFE)仅为教师模型的几十分之一。
表1:在相同 FID/GM 水平下,D-MMD 所需的采样步数(NFE)仅为教师模型的几十分之一。
作者还特别解决了 Temperature 和 Top-p 蒸馏 的问题。在文本生成中,我们通常需要 Top-p 采样来提高质量,但在蒸馏时这会导致梯度消失。D-MMD 通过一种动态平滑 Logits 的策略( constant subtraction),让模型在蒸馏阶段就能学习到高置信度采样的特征。
深度洞察与总结
学生为什么能比教师强?
这听起来像个悖论,但作者给出了学术解释:教师模型基于最大似然训练,本质上是 Mode-covering(模式覆盖),容易产生低质量的长尾分布。而 D-MMD 的对抗组件更像是逆 KL 散度优化,具有 Mode-seeking(模式寻求) 的特性,能自动向高质量的数据中心靠拢,这在生成任务中往往比“死板复制教师”更有效。
局限性
尽管步数大幅降低,但每步推理仍需经过完整的神经网络前向传播。此外,该方法对于极小词表且无电感偏置的离散任务(如像素级图像生成)虽有提升,但距离 Continuous Latent Diffusion 仍有一定差距。
未来展望
D-MMD 为并行生成语言模型落地提供了关键技术支撑。随着该架构在长文本、多模态任务(如图像 Token 蒸馏)中的应用,我们或许很快就能看到推理速度提升一个数量级的非自回归生成器取代目前的逐词 Token 采样。
本博客由资深学术技术主编重构。原文作者:Emiel Hoogeboom et al. (Google DeepMind)