The paper introduces Hierarchical Experience (HiExp), a framework that enhances RL-based search agents by transforming stochastic exploration into experience-driven reasoning. It utilizes self-reflection and multi-level clustering to extract meta-knowledge from internal trajectories, enabling small models like Qwen2.5-7B to outperform frontier LLMs (e.g., GPT-4) on complex multi-hop QA and mathematical reasoning tasks.
TL;DR
Reasoning-heavy tasks remain a hurdle for Small Language Models (SLMs), which often "get lost" during multi-step tool use. Alibaba Cloud researchers have introduced HiExp (Hierarchical Experience), a framework that allows agents to learn from their own successes and failures. By distilling raw reasoning trajectories into a hierarchical knowledge base, they transform erratic exploration into a focused, strategy-driven search process.
The "Random Walk" Problem in Agentic Search
Building a "Deep Research" system requires more than just connecting an LLM to Google. Standard Reinforcement Learning (RL) approaches for agents rely on stochastic exploration. The model tries various search queries, receives a reward for the final answer, and updates its policy.
However, this often fails because:
- Inconsistent Reward Signals: Multi-turn search paths are long; a single mistake in the second hop makes the final reward useless for training.
- Logical Drift: Without a strategy, agents often deviate into irrelevant sub-topics (textual noise).
- SLM Bottlenecks: Smaller models lack the "global view" needed to plan three steps ahead.
Methodology: Building the "Experience Engine"
HiExp moves beyond static RAG by treating an agent's own history as a goldmine. The process follows a structured pipeline:
1. Contrastive Distillation
The system performs rollouts for a single question. By comparing paths that reached the correct answer () against those that failed (), the model performs "self-reflection" to identify exactly which search query or reasoning step caused the failure.
2. Hierarchical Abstraction
Raw experiences are fragmented. HiExp uses Agglomerative Clustering to organize these insights into three levels:
- E1 (Atomic): Specific case-based corrections (e.g., "Don't confuse a play's premiere date with its composition month").
- E2/E3 (Strategic): Generalized blueprints (e.g., "For temporal questions, resolve the identity of the person first").
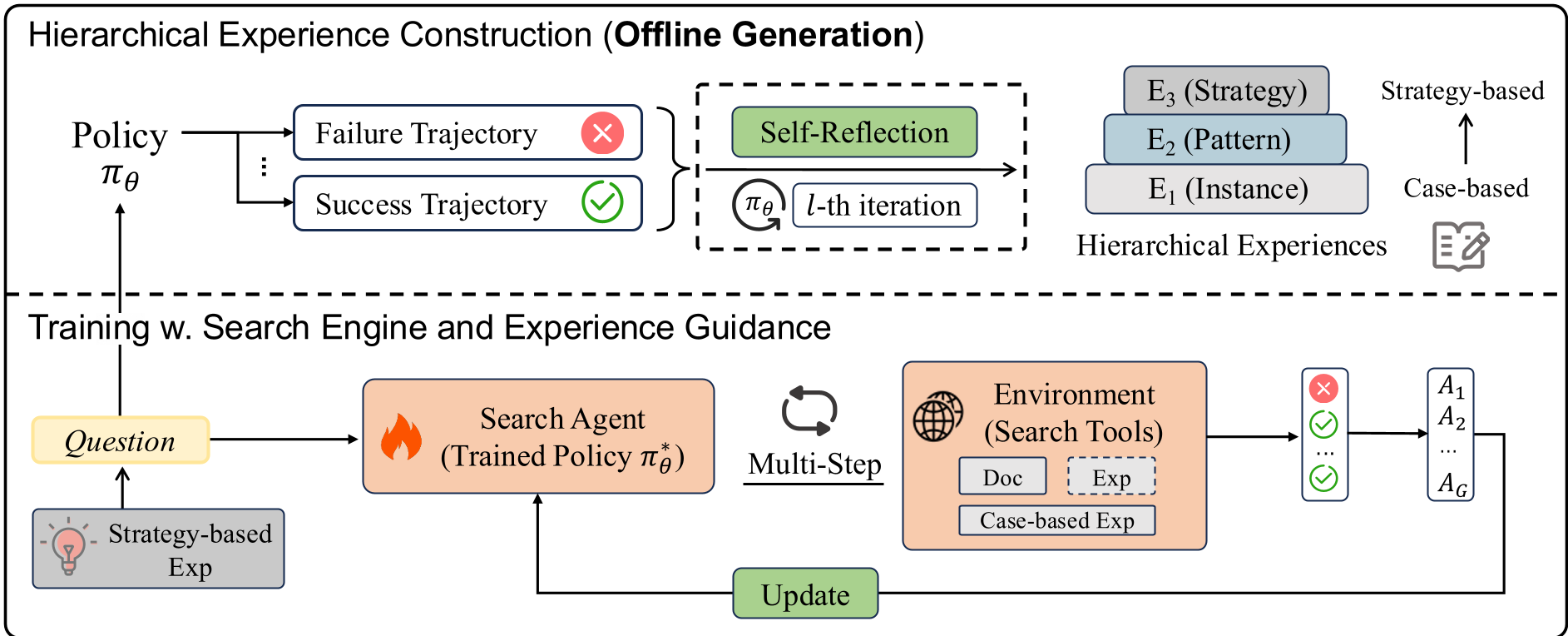 Figure 1: The HiExp framework showing the transition from raw trajectories to hierarchical knowledge and its integration into RL training.
Figure 1: The HiExp framework showing the transition from raw trajectories to hierarchical knowledge and its integration into RL training.
Experience-Aligned Training
During the RL phase (using Group Relative Policy Optimization - GRPO), the model doesn't just search the web; it searches its own Hierarchical Experience Knowledge (HEK).
- At the start, it pulls E2 strategies to set a logic blueprint.
- During tool calls, it retrieves E1 heuristics to prevent common traps.
This alignment regularizes the Advantage function in RL, leading to much more stable gradient updates and faster convergence.
Experimental Breakthroughs
The results are striking. A 7B parameter model equipped with HiExp doesn't just compete with 10x larger models; in many cases, it beats them.
Performance vs. Frontier LLMs
On the Musique benchmark (highly complex multi-hop QA), the HiExp-Searcher (7B) achieved a score of 36.7 CEM, outperforming the massive Qwen3-235B (39.5) and approaching GPT-4.1 levels.
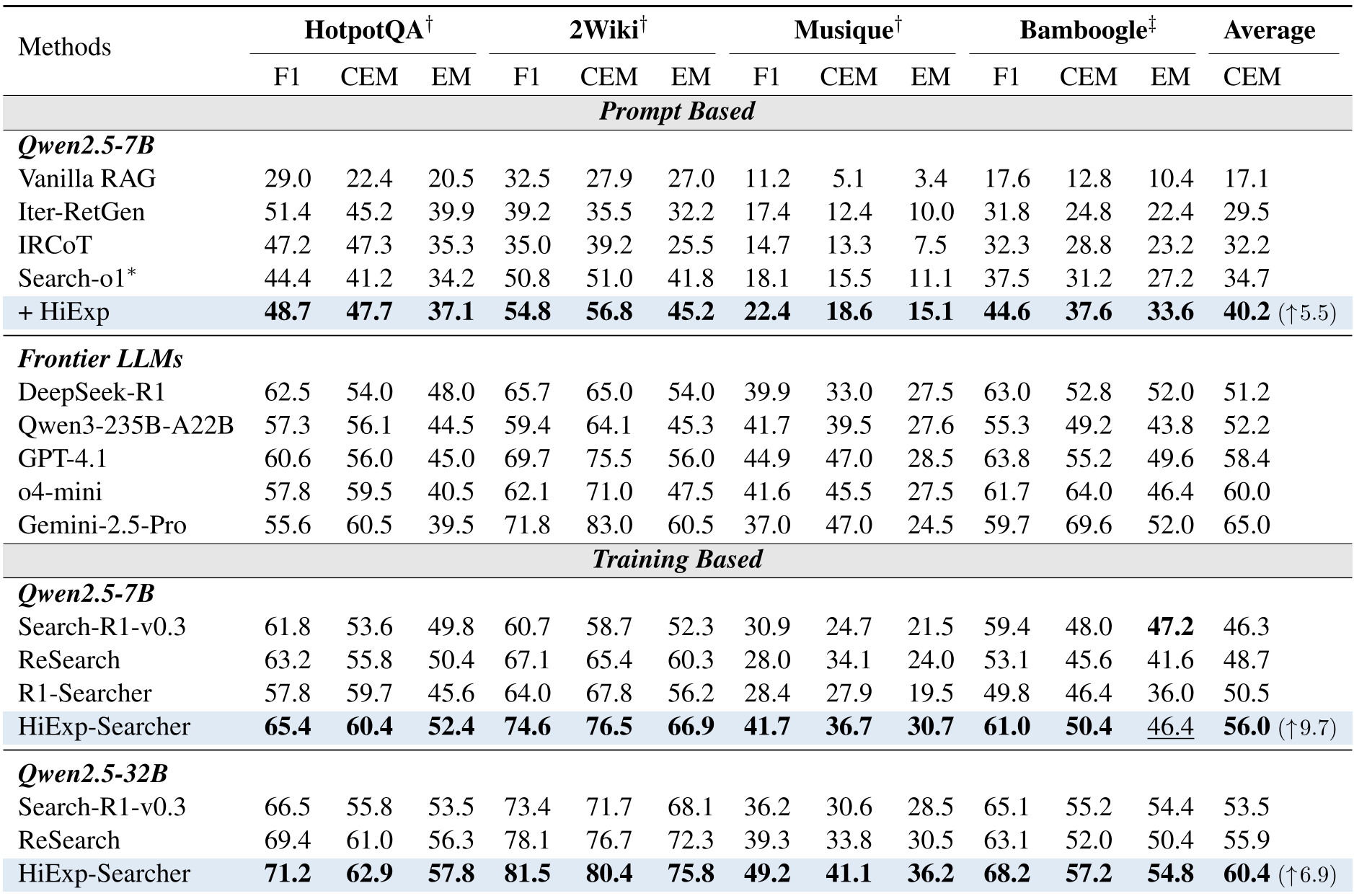 Table 1: Quantitative results across multi-hop benchmarks. Note the massive gains of HiExp-Searcher over standard RL baselines.
Table 1: Quantitative results across multi-hop benchmarks. Note the massive gains of HiExp-Searcher over standard RL baselines.
Training Stability
Vanilla RL often suffers from "reward hacking" or stagnant learning. HiExp's guidance significantly reduces the variance in advantage estimates, allowing the model to climb the reward curve more efficiently.
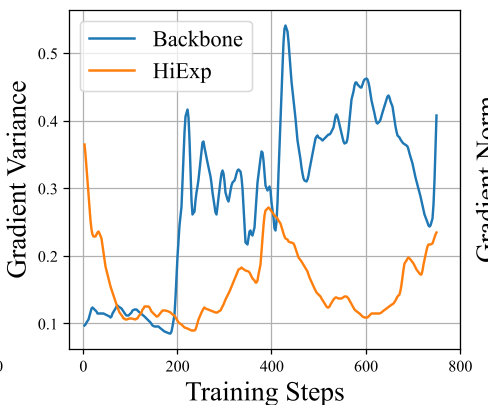 Figure 2: The evolution of reward signals during training. HiExp reaches higher reward plateaus faster than stochastic exploration.
Figure 2: The evolution of reward signals during training. HiExp reaches higher reward plateaus faster than stochastic exploration.
Critical Insight: Self-Distillation is King
A fascinating finding in the paper (Table 6) is that Self-Distillation (7B → 7B) actually outperformed Strong-Teacher Distillation (Max → 7B) by 1.2%. This suggests that the experiences an LLM generates for itself are better "aligned" with its own capability boundaries and reasoning distribution than insights from a superior model.
Conclusion and Future Outlook
HiExp proves that for agentic search, how you explore matters more than how much you explore. By turning internal trajectories into a structured pedagogical tool, SLMs can achieve "frontier-level" reasoning.
The current limitation is the semi-decoupled nature of the system (experience construction happens offline). The "Holy Grail" for future work will be a closed-loop system where the agent refines its hierarchical experience base in real-time as it learns.
Author Note: This work signals a shift in the Agentic AI landscape—from scaling retrieval data to scaling internal architectural reflection.